标签:决策 info 天气 需要 nbsp 聚类 速度 提升 动物
1、机器学习定义
大数据时代,随着网络的普及化以及计算机计算速度和存储能力的提高,人类更容易收集、存储、传输、管理数据,各行各业已经积累了大量的数据资源。如何利用这些数据服务于人类社会、促进经济发展、便捷人类生活日益成为各行各业关注的重点。由于人类处理数据的能力有限,因而只能让机器处理大量的数据,“机器学习”正是针对这一问题,它致力于研究通过计算的手段,让计算机从数据中学习知识,从而实现一些人类才能完成的任务,产生机器智能。
机器学习的定义有很多,大致可以归纳为以下三个:
(1) 如果一个系统能够通过执行某个过程改进自身的性能,我们就可以称之为学习。
(2) 学习可以看作是一个基于经验数据的函数估计问题。
(3) 学习就是从数据中提取重要模式,并理解数据。
机器学习的核心问题就是如何设计一种模型(算法)从数据中学习到知识(经验),并据此对未来做出预测。
2、机器学习的类型
监督学习(supervised learning):在给出计算机输入的同时,同时给与输出的标签,学习的模型能够对任意给定的输入,对其相应的输出做出一个好的预测。
无监督学习(unsupervised learning): 只给计算机训练数据,不给结果(标签),因此计算机无法准确地知道哪些数据具有哪些标签,只能凭借强大的计算能力提取数据内在的隐含特征,从而得到一定的成果,通常是得到一些集合,集合内的数据在某些特征上相同或相似。例如,聚类(clustering),聚类的结果将产生一组集合,集合中的对象与同集合中的对象彼此相似,与其他集合中的对象相异
半监督学习(semi-supervised learning):给计算机大量训练数据与少量的分类结果(具有同一标签的集合)。
强化学习(reinforcement learning):强调如何基于环境而行动,以取得最大化的预期利益。强化学习作为一个序列决策(Sequential Decision Making)问题,它需要连续选择一些行为,从这些行为完成后得到最大的收益作为最好的结果。在序列决策中,获取大量有标记的训练样本本身是一件困难的事,强化学习在没有任何label告诉算法应该怎么做的情况下,通过先尝试做出一些行为——然后得到一个结果,通过判断这个结果是对还是错来对之前的行为进行反馈,通过奖励和惩罚措施,鼓励模型做出正确的决策,从而改进算法的性能。
3、回归与分类的不同
回归(regression)的目标是用来预测一个连续的值,如预测房价、未来的天气情况等等,例如一个产品的实际价格为500元,通过回归分析预测值为499元,我们认为这是一个比较好的回归分析。一个比较常见的回归算法是线性回归算法(LR)。另外,回归分析用在神经网络上,其最上层是不需要加上softmax函数的,而是直接对前一层累加即可。回归是对真实值的一种逼近预测。
分类(classification)的目标是将事物打上一个标签,预测结果为离散值。例如判断一幅图片上的动物是一只猫还是一只狗,分类通常是建立在回归之上,分类的最后一层通常要使用softmax函数进行判断其所属类别。分类并没有逼近的概念,最终正确结果只有一个,错误的就是错误的,不会有相近的概念。最常见的分类方法是逻辑回归,或者叫逻辑分类。
4、过拟合(overfitting)与欠拟合(underfitting)
过拟合是在训练样本学习的很好,从而把训练样本本身的一些特点当作了所有潜在样本都会有的一般性质,导致泛化能力下降,在测试样本表现不好。欠拟合是指对训练样本的一般性质尚未学好。通常过多的参数会导致过拟合,可以加入正则项减弱过拟合。
5、损失函数(loss function)
损失函数是用来估量模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。损失函数通常有两部分组成:损失项和正则项。
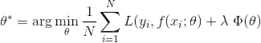
其中,前面的均值函数表示的是经验风险函数,L代表的是损失函数,后面的Φ是正则化项(regularizer)或者叫惩罚项(penalty term),它可以是L1,也可以是L2,或者其他的正则函数。
常用的损失函数有以下几中:
(1)0-1损失函数(0-1 loss function)
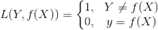
(2)绝对值损失函数(absolute loss function)
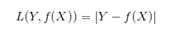
(3)平方损失函数(quadratic loss function)
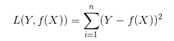
(4) 对数损失函数(logarithmic loss function)或对数似然损失函数(log-likelihood loss function)
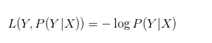
(5) 指数损失函数(exponential loss function)
指数损失函数的典型代表是AdaBoost。Boosting是一族可将弱机器学习器提升为强机器学习的算法。工作机制:先从初始训练集中训练一个基学习器,再根据学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多的关注,最典型的代表是AdaBoost算法。
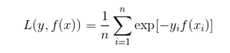
6、模型评估
(未完待续)
标签:决策 info 天气 需要 nbsp 聚类 速度 提升 动物
原文地址:http://www.cnblogs.com/nlplmt/p/6607742.html