一种生成词向量的途径是利用神经网络算法,当然,词向量通常和语言模型捆绑在一起,即训练完后两者同时得到。用神经网络来训练语言模型的思想最早由百度 IDL (深度学习研究院)的徐伟提出。 这方面最经典的文章要数 Bengio 于 2003 年发表在 JMLR 上的 A Neural Probabilistic Language Model,其后有一系列相关的研究工作。
谷歌的 Tomas Mikolov 团队开发了一种词典和术语表的自动生成技术,能够把一种语言转变成另一种语言。该技术利用数据挖掘来构建两种语言的结构模型,然后加以对比。每种语言词语之间的关系集合即“语言空间”,可以被表征为数学意义上的向量集合。在向量空间内,不同的语言享有许多共性,只要实现一个向量空间向另一个向量空间的映射和转换,语言翻译即可实现。该技术效果非常不错,对英语和西语间的翻译准确率高达 90%。
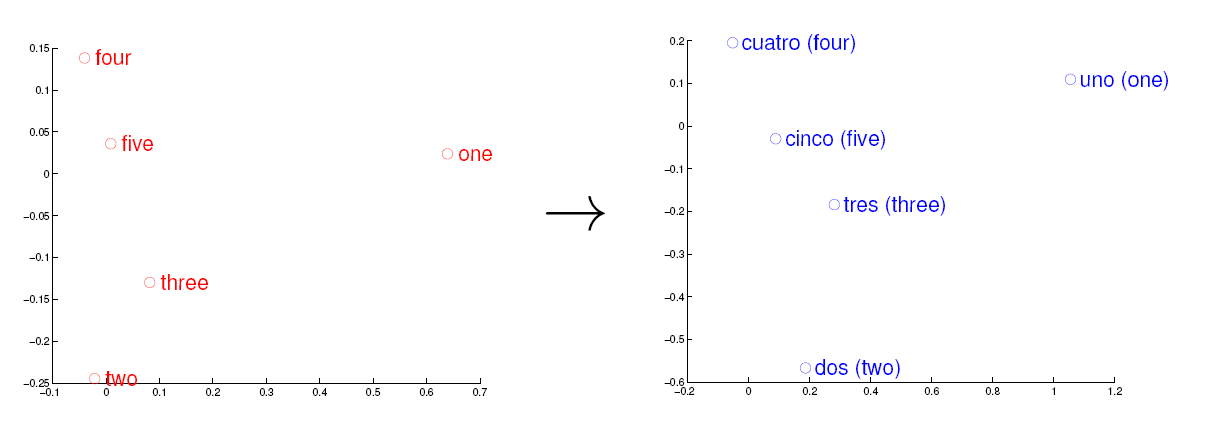
考虑英语和西班牙语两种语言,通过训练分别得到它们对应的词向量空间 E 和 S。从英语中取出五个词 one,two,three,four,five,设其在 E 中对应的词向量分别为 v1,v2,v3,v4,v5,为方便作图,利用主成分分析(PCA)降维,得到相应的二维向量 u1,u2,u3,u4,u5,在二维平面上将这五个点描出来,如下图左图所示。类似地,在西班牙语中取出(与 one,two,three,four,five 对应的) uno,dos,tres,cuatro,cinco,设其在 S 中对应的词向量分别为 s1,s2,s3,s4,s5,用 PCA 降维后的二维向量分别为 t1,t2,t3,t4,t5,将它们在二维平面上描出来(可能还需作适当的旋转),如下图右图所示: