标签:click tor 技术 推荐引擎 cli ref 模型 资源 pen
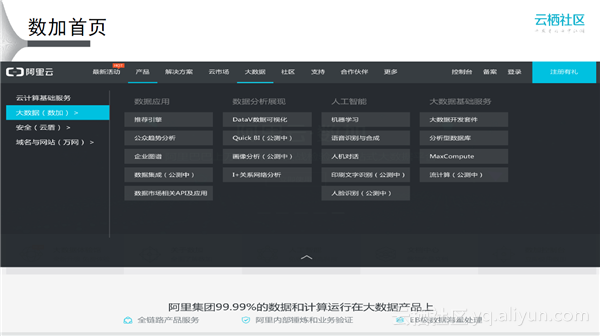
在阿里云的官网打开大数据部分(整个大数据部分统称为数加),其中包括:大数据基础服务部分,MaxCompute、ADS、流计算、大数据开发套件;人工智能部分,机器学习(基础平台是PAI)、语音识别、ET等;数据分析展现部分,数据可视化(大屏、BI报表)、I+关系网络分析(安全领域用的比较多);数据应用部分,推荐引擎(提供面向终端用户的服务,以大数据中间件存在)等。天池比赛也是基于数加平台,数加数据市场相当于大数据的App Store。
数加是什么?数加=数加平台+数加市场+数加应用。平台相当于OS部分,其上有App Store(即市场),市场上有大量的应用(包括官方应用和第三方应用)。数加平台基于阿里十几年在大数据上的经验积累,在对内的平台BASE上做了一个对外的实例即数加。数加平台除了BASE,还包括多租户、账号、权限、安全、meta、计量计费、Open API、数据市场、数加网站等模块,也包括算法平台PAI。
数加平台=大数据OS=大数据的IOS。大数据OS希望提供高度集成的大数据平台,将计算引擎、数据开发工具、数据采集和传输工具、数据分析工具、机器学习平台无缝集成,提供端到端的一站式用户体验;提供云数仓服务(对标redshift),革传统数据仓库的命,让基于Hadoop自建数据平台成为往事,让客户专注于业务系统开发,把用户数据还给用户,提供安全隔离的租户空间;是开放的大数据OS,兼容开源数据生态,支持各种第三方数据应用在上面安装使用;支持数据交换和分享,让用户安全,可计量的使用他方数据。
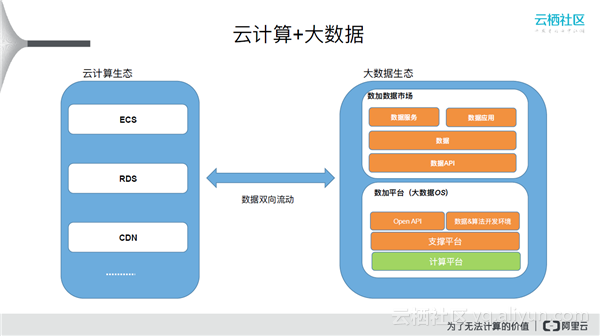
大数据生态中,数加平台最底层是计算平台,还包括一系列支撑平台、数据开发和算法开发,对外提供大数据的基本职能是SQL开发(是Web界面,方便易用)、MapReduce开发、算法开发(PAI)。Open API层可与外部应用打通。数加数据市场中,包括数据服务(包括API服务)、数据应用(基于整个数据开发平台,以及数据API等各种东西)。
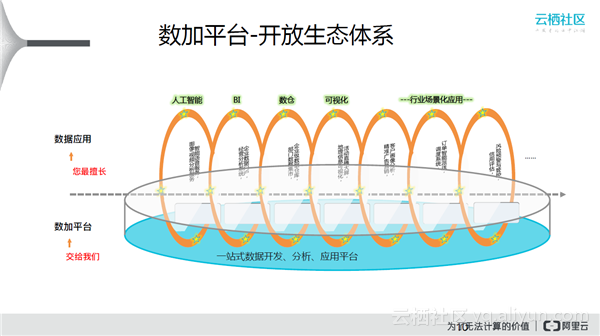
上图中,下面是数加平台,核心的东西是数据开发、数据分析、应用平台,上面是各个领域的应用。
很早以前,阿里很多的BO用的都是IOE,其存储昂贵、可扩展性差。阿里各个分支有不同的尝试,B2B、支付宝尝试的是Greenplum,淘宝选择了Hadoop。此时产生了数据孤岛问题,各业务部门的数据散落在多个集群,彼此之间数据不通,数据共享太难,缺少权限安全的管理。所以需要做数据仓库来把数据集中在统一的一个平台来管理。数据共享的问题解决之后,由于数据不集中,也没有较好的数据仓库规划,导致数据被拖来拖去、重复存储和计算,出现了重复建设的问题。
在Hadoop的基础上,做了统一的自主可控的大数据平台,其特点是:统一平台,数据大集中,统一的存储,统一的计算平台,统一的数据开发平台,统一的元数据又会涉及到数据治理;资源共享,弹性分配,基于ODPS多集群技术,由数以万计的服务器提供超级计算能力,按需弹性分配给各数据开发团队;数据隔离,权限管理,基于ODPS多租户机制,各部门可独立管理自身的数据,独立做数据授权。
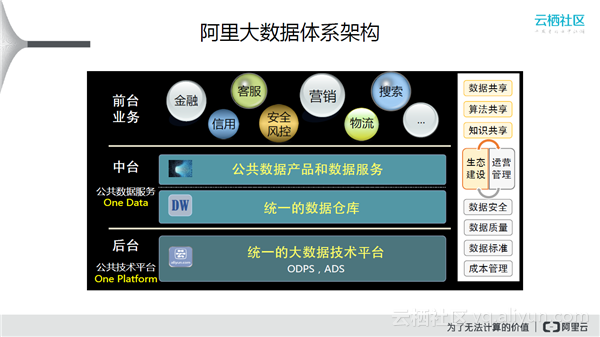
上图展示了阿里内部数据平台的进化。首先是大数据平台的统一,数据仓库的统一极其重要,然后是产品和服务层的统一。最上方的前台业务也契合了阿里的公司战略:基础设施要足够大,前台能够利用其快速突破业务。右边是支撑数据平台的一些工具软件。比如成本管理,当一个公司足够大的时候,成本控制非常重要。怎么做到数据共享、算法共享、知识共享,一直是阿里的愿景。
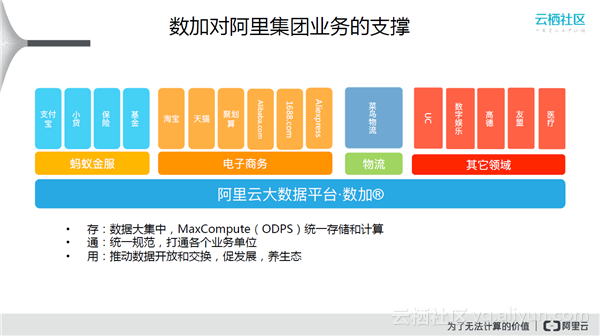
上图是数加对阿里集团业务的支撑,下面是数加平台,支撑着蚂蚁金服、电子商务、物流及其他领域。存、通、用是阿里在数据上面多年来总结的心法。存是指数据大集中,MaxCompute(ODPS)统一存储和计算;通是指统一规范,打通各个业务单位,进而推动数据开放和交换,促发展,养生态;用是指数据化运营,进而运营数据。

阿里集团绝大部分数据都在数加平台上。
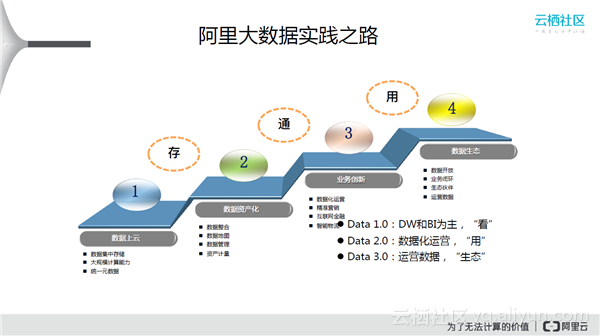
首先需要统一的数据上云,然后数据资产化是指解决成本问题,只有能产生业务价值才能反向拉动整个数据相关技术及团队的成长。数据生态是将前三步积累的东西构建一个平台。
首先是,希望数加平台成为数据分享第一平台,基于大数据OS构建大数据生态。普惠大数据也是其中一个愿景,希望大家通过这个平台可以更加关注自己的业务而不是研究如何搭建平台、Hadoop。其实,做数据平台最难的并不是搭Hadoop、Spark,而是如何做元数管理、调度、数据治理、数据监控。一个公司需要投入很大的人力才能做到基本可用。普惠大户数据的提出就是希望基于这个平台,人人可用,便宜,好用。
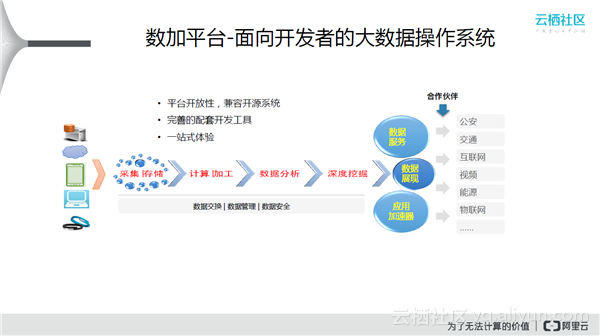
业务数据经过4个过程:采集存储环节,工具可以使用DataX;计算和加工环节,包括数据预处理和加工、数据模型、算法;数据分析环节,一般是使用BI工具,也包括即时查询、多维查询工具;深度挖掘环节。最后进行数据服务和数据展现。应用加速就是经常提到的大数据中间件,比如大屏的中间件DataV。右边是一些应用的行业。
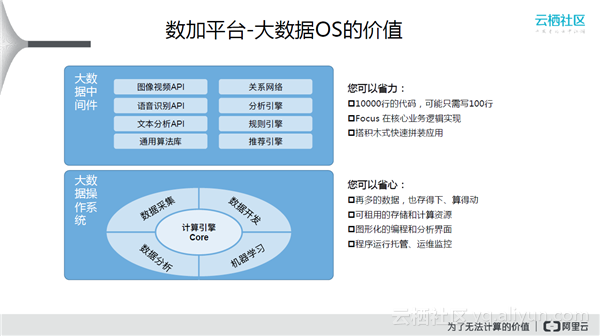
OS层最里面是计算引擎,数据采集、数据开发、数据分析、机器学习是最重要的数据学习领域。上部分列出了有些比较常见的中间件。正常来说,从零开始开发一个个性化推荐需要900人天的时间,但是使用上述的中间件可以将时间缩短到30人天。从零开始开发一个活动直播大屏需要一个月的时间,使用中间件只需要3天~1个小时。
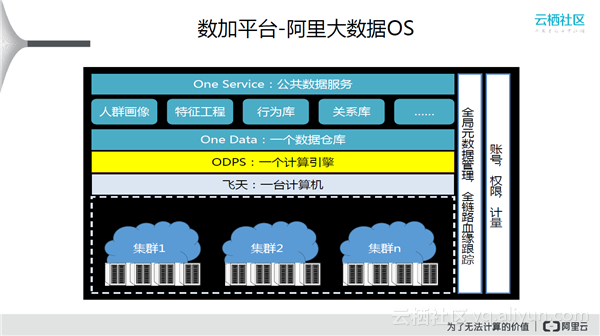
上图展示了阿里大数据OS整个体系。下面是n个独立的集群(可能是跨国的),用飞天OS将其变得相当于一台计算机,使用ODPS则看起来像一个计算引擎,One Data做数据仓库进行统一的管理和数据治理。周边是数加平台的基础设施和支撑软件,比如元数据、调度和任务监控。最上方基于One Service公共数据服务对外提供服务。
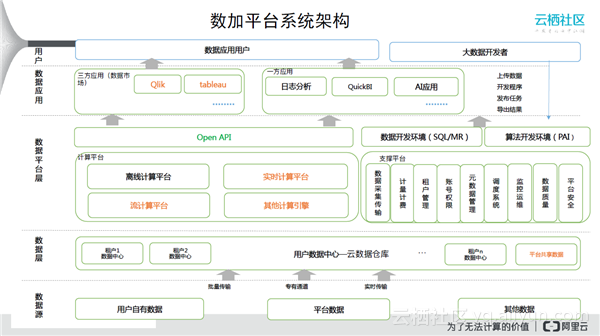
更详细来看,数据层包含了各种数据,用户数据中心即云数据仓库,每个用户可以在其上建立自己的数据中心。各租户之间可以做分享,并且有平台共享的数据。数据平台层包括计算引擎和支撑平台,对外有做SQL开发和MapReduce开发的接口,OpenAPI可以将做好的数据分享或者授权给别人使用。上面是数据应用,包括一方应用(日志分析、QuickBI、AI应用)和三方应用。
阅读全文:http://click.aliyun.com/m/15157/
标签:click tor 技术 推荐引擎 cli ref 模型 资源 pen
原文地址:http://www.cnblogs.com/iyulang/p/6636855.html