标签:需要 shel pat 中间 兴趣 匹配 port 内容 des
不了解编码的,需要先补下:http://www.cnblogs.com/jiangtu/p/6245264.html
现象:从scrapy抓取的页面中文会变成unicode字符串,如下图
2017-03-28 23:00:12 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.lagou.com/jobs/2617468.html> {‘describe‘: [u‘<div>\n <p>\u5c97\u4f4d\u804c\u8d23</p>\n<p>\u8d1f\u8d23\u7f51\u7ad9\u4e0b\u8f7d\u5185\u5bb9\u7684\u65e5\u5e38\u66f4\u65b0\u7ef4\u62a 4\u4e0e\u5ba1\u6838</p>\n<p>\u8d1f\u8d23\u7ef4\u62a4\u7f51\u7ad9\u5404\u76f8\u5173\u9875\u9762\u7684\u65e5\u5e38\u66f4\u65b0\u63a8\u8350</p>\n<p>\u8d1f\u8d2 3\u8ddf\u8fdbSEO\u90e8\u95e8\u7684\u65b9\u6848\u5b9e\u65bd\u548c\u76f8\u5173\u9879\u76ee\u8ddf\u8fdb</p>\n<p>\u8f85\u52a9\u4e3b\u7f16\u534f\u8c03\u7ba1\u740 6\u548c\u5b89\u6392\u7f51\u7ad9\u5185\u90e8\u4eba\u5458\u7684\u5de5\u4f5c</p>\n<p><br></p>\n<p>\u5c97\u4f4d\u8981\u6c42</p>\n<p>\u7535\u8111\u548c\u624b\u67 3a\u64cd\u4f5c\u719f\u7ec3\uff0c\u638c\u63e1\u529e\u516c\u8f6f\u4ef6\u3001\u5b89\u5168\u8f6f\u4ef6\u548c\u56fe\u7247\u5904\u7406\u8f6f\u4ef6\u7684\u57fa\u67 2c\u4f7f\u7528</p>\n<p>\u4e86\u89e3\u76ee\u524d\u4e3b\u6d41\u7684\u70ed\u95e8PC\u8f6f\u4ef6/\u624b\u673a\u5e94\u7528/\u624b\u673a\u6e38\u620f\uff0c\u5bf9\u6 5b0\u5947\u7279\u7684\u8f6f\u4ef6\u6709\u4e00\u5b9a\u7684\u654f\u611f\u5ea6</p>\n<p>\u6709\u8d23\u4efb\u5fc3\u3001\u6709\u6c9f\u901a\u548c\u5b66\u4e60\u80fd \u529b\uff0c\u80fd\u5403\u82e6\u8010\u52b3\u3001\u6027\u683c\u5f00\u6717</p>\n<p>\u6709SEO\u57fa\u7840\u6216\u76f8\u5173\u7f16\u8f91\u7ecf\u9a8c\u4f18\u5148 </p>\n<p><br></p>\n<p>\u85aa\u8d44\u5f85\u9047</p>\n<p>\u5de5\u4f5c\u65f6\u95f4\uff1a\u4e0a\u534810\uff1a00\u81f3\u4e0b\u534819\uff1a00\uff1b</p>\n<p>\u85aa \u8d44\u7ed3\u6784\uff1a\u57fa\u672c\u5de5\u8d44+\u5c97\u4f4d\u5de5\u8d44+\u7ee9\u6548\u5de5\u8d44+\u5348\u9910\u8865\u52a9+\u591c\u9910\u8865\u52a9+\u6253u8f66\u8d39\u62a5\u9500+\u4e94\u9669\u4e00\u91d1+\u5e74\u7ec8\u5956\u7b49</p>\n<p>\u5176\u4ed6\u798f\u5229\uff1a\u53cc\u4f11+\u6cd5\u5b9a\u5047\u65e5\u4f11+ \u8fc7\u8282\u8d39/\u8282\u65e5\u793c\u54c1+\u5e74\u4f11\u5047\u7b49</p>\n\n </div>‘], ‘title‘: [u‘\u7f51\u7ad9\u7f16\u8f91‘], ‘url‘: ‘https://www.lagou.com/jobs/2617468.html‘}
这个response的截图
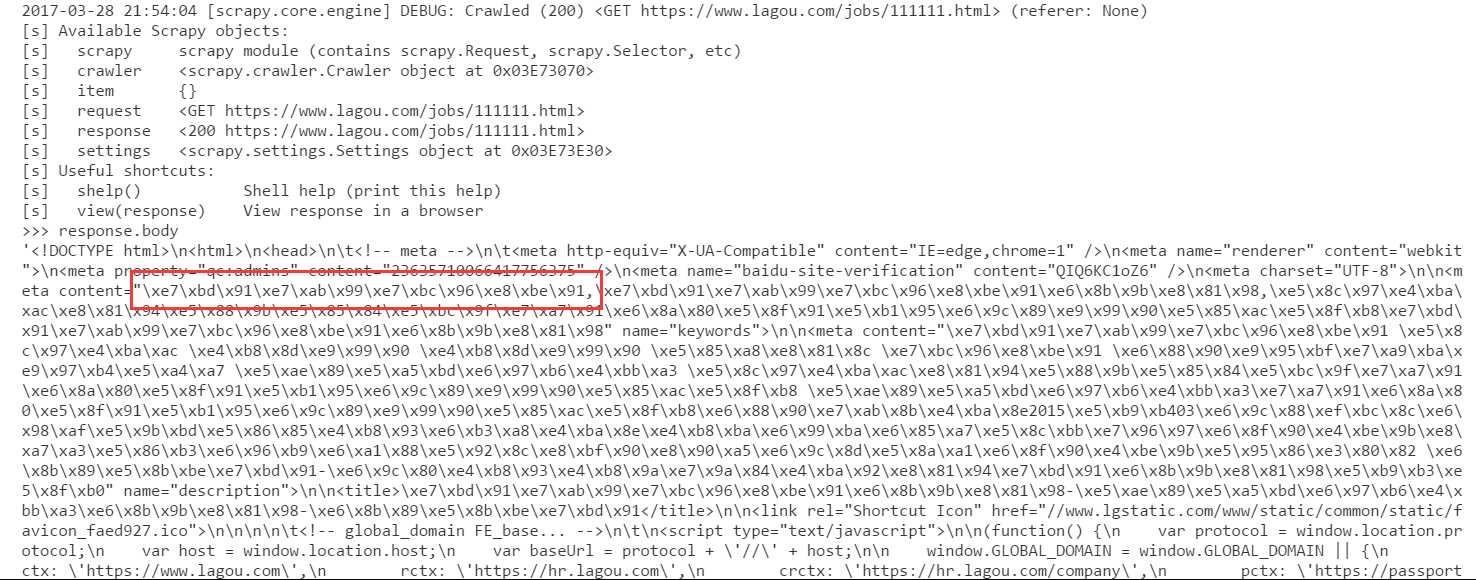
我取红框中的字符串(utf-8编码)做了本地处理,下图是此字符串对应的中文。

然后在本地做了如下测试:
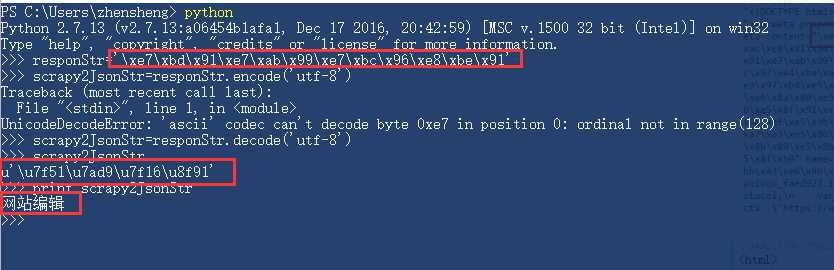
可以看到,字符串本地查看时就是 unicode 字符串格式。print打印时会改变
1 >>> s=u‘\u7f51‘ 2 >>> y={"a":s} 3 >>> y 4 {‘a‘: u‘\u7f51‘} 5 >>> import json 6 >>> t=json.dumps(y) 7 >>> t 8 ‘{"a": "\\u7f51"}‘ 9 >>> fi=open(r‘C:\Users\zhensheng\Desktop\123‘,‘w‘) 10 >>> fi.write(t) 11 >>> fi.close() 12 >>> fii=open(r‘C:\Users\zhensheng\Desktop\123‘,‘r‘) 13 >>> tt=fii.readlines() 14 >>> tt 15 [‘{"a": "\\u7f51"}‘] 16 >>> json.loads(tt[0]) 17 {u‘a‘: u‘\u7f51‘} 18 >>>
文件中的内容为:
{"a": "\u7f51"}
直接向文件中写 u‘\u7f51‘ 会报错,因为默认以ascii写入,然后碰到 第一个u 会报错。所以我将其用 json 序列化后写到文件里了
可以看到,读出的内容前加了 u 。
虽然我还是没弄懂为什么。。
捋一下流程:首先,Spider发送Request,网站返回了 Response,由于网络传输的原因,必然Response.body中的中文被utf-8编码转码了。所以是 \x..样式。然后,Scrapy对其进行处理,中间肯定有对其进行转码的过程,此处应该是正确将其编码了。就跟上图中的红框 Scrapy2jsonStr 显示的,是以u开头的,此时如果 print,是可以显示中文的,但是,由于Scrapy接下来对其进行了Json序列化以及某些包装处理,(若只有json序列化,应当为 {u‘a‘: u‘\u7f51‘} 这种形式,见上方代码16~17行)。所以 最后Scrapy输出的是{‘describe‘: [u‘<div>\n \u..‘]}这种样式。其中, [u‘<div>\n \u..‘]是list,因为Scrapy默认你匹配到的是多个(参考选择器里有addxpath,可见一斑)。
或许就是因为 Python 默认存储使用 unicode 方式的原因吧。(不知从那瞄得,忘记了)
虽不知确切原因,但是目前只能按以下方案暂行处理了:
在 Pipeline 中对字段进行处理,只去列表中的第一个元素,这样,提取到的Json文档变为:{‘describe‘: u‘<div>\n \u..‘},然后,若要print输出,则直接 print result[‘describe‘]即可,若要输出到文件,则对其进行编码即可: fi.write(result[‘describe‘].encode(‘utf-8‘))。
关于windows powershell输出还有坑,有兴趣的可以看下:http://www.cnblogs.com/jiangtu/p/6608212.html
标签:需要 shel pat 中间 兴趣 匹配 port 内容 des
原文地址:http://www.cnblogs.com/jiangtu/p/6637640.html