标签:存在 位置 http arch pip 保留 分享 图形 play
两周以前读了些文档自动摘要的论文,精读了三篇并做了presentation。下面把相关内容简单整理一下。
文本自动摘要(Automatic Text Summarization)就是说在不改变文档原意的情况下,利用计算机程序自动地总结出文档的主要内容。自动摘要的应用场景非常多,例如新闻标题生成、科技文献摘要生成、搜索结果片段(snippets)生成、商品评论摘要等。在信息爆炸的互联网大数据时代,如果能用简短的文本来表达信息的主要内涵,无疑将有利于缓解信息过载问题。
一、概述
自动摘要可以从很多角度进行分类,例如单文档摘要/多文档摘要、单语言摘要/跨语言摘要等。从技术上说,普遍可以分为三类:
i. 抽取式摘要(extractive),直接从原文中抽取一些句子组成摘要。本质上就是个排序问题,给每个句子打分,将高分句子摘出来,再做一些去冗余等。这种方式应用最广泛。
ii. 压缩式摘要(compressive),在抽取式摘要的基础上对句子再做压缩。常用方法是ILP:既然是规划嘛就是给出各种限制,来确定句子中的词是否保留、句子是否保留,这是一种jointly的方式。此外还可以是pipeline的方式,抽句子和压缩句子这两个过程是分开的。
iii. 理解式摘要(abstractive),也叫产生式摘要,试图理解原文的意思,然后生成摘要,也就是像我们人做摘要那样来完成任务。
从是否有用户查询的角度来说,可以分为通用型摘要(generic)和基于用户查询的摘要(query-oriented),其中后者不仅要求生成的摘要应概括原文关键信息,还要尽可能与用户查询具有很高的相关性。
二、评价指标
首先可以是人工评价,这里主要介绍自动评价。目前来说,自动评价指标采用的是ROUGE,R是recall的意思,换句话说,这个指标基于摘要系统生成的摘要与参考摘要的n元短语重叠度:
$$\text{ROUGE-N}_{\text{recall}}=\frac{\displaystyle\sum_{S\in\{\text{Ref}\}}\displaystyle\sum_{n\text{-gram}\in S}Count_{\text{match}}(n\text{-gram})}{\displaystyle\sum_{S\in\{\text{Ref}\}}\displaystyle\sum_{n\text{-gram}\in S}Count(n\text{-gram})}$$
这个指标用来应付抽取式摘要可能问题不大,但是由于其无法评价所生成摘要的语法和语义,而且倾向于长摘要,所以其实还应该继续探索更合理的指标来评价理解式摘要。此外,当然也可以计算基于precision的ROUGE,而且ROUGE还有ROUGE-L等多种版本;最常使用的是ROUGE-N的N取2的方式(也就是ROUGE-2)。
三、使用seq2seq + attention机制,生成理解式摘要
前面简略介绍了一些概念(还差语料没介绍,后面随着说实验时再说吧)。下面就开始介绍我精读的前两篇文章:
[1] A Neural Attention Model for Abstractive Sentence Summarization,2015EMNLP
[2] Abstractive Sentence Summarization with Attentive Recurrent Neural Networks,2016NAACL
第二篇文章是第一篇文章所做工作的延续。它们所试图解决的是句子级别摘要问题:输入新闻的第一句话,试图生成新闻标题。至于为什么是一句话,主要还是因为就目前来看神经网络还不能很好地处理太长的序列。
由于自动摘要和机器翻译都属于“序列到序列”这个类型(输入的是序列,输出也是序列;但必须注意翻译和摘要这两个问题是非常不同的),因此这两篇文章将神经机器翻译中广泛使用的encoder-decoder框架和attention mechanism(注意力机制)引入到自动摘要问题,试图用这样一种fully data-driven的方式,端到端地训练出自动摘要模型。
首先简要介绍一些概念。
1. Sequence to sequence learning 与 encoder-decoder框架
如果只说“序列到序列”的话,那么词性标注(POS)其实也是这样的过程。但是它跟翻译、摘要显著不同的地方在于:在POS问题中,输入和输出是一一对应的,而翻译、摘要的输出序列与输入序列则没有显著的对应关系。所以如下图所示,POS问题可以用最右边的那个RNN结构来建模,每个时刻的输入与输出就是词与词性。相比之下,翻译、摘要这种则可以通过倒数第二张图那样的结构来解决,这个结构可以看作是encoder和decoder都是RNN的encoder-decoder框架。
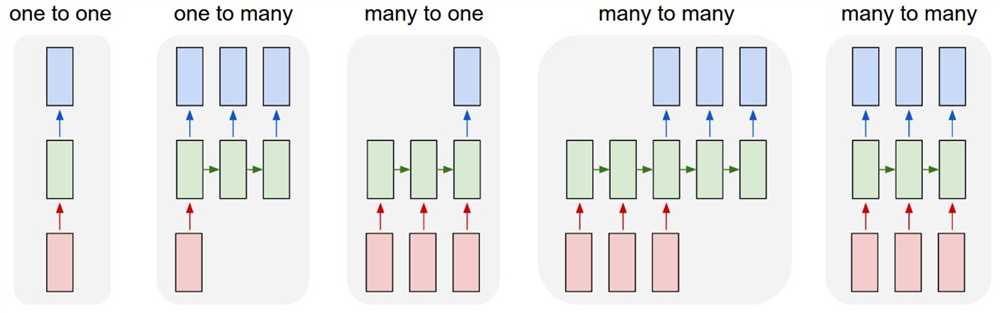
图片来源:http://karpathy.github.io/2015/05/21/rnn-effectiveness/
encoder-decoder框架的工作机制是:先使用encoder,将输入编码到语义空间,得到一个固定维数的向量,这个向量就表示输入的语义;然后再使用decoder,将这个语义向量解码,获得所需要的输出,如果输出是文本的话,那么decoder通常就是语言模型。这种机制的优缺点都很明显,优点:非常灵活,并不限制encoder、decoder使用何种神经网络,也不限制输入和输出的模态(例如image caption任务,输入是图像,输出是文本);而且这是一个端到端(end-to-end)的过程,将语义理解和语言生成合在了一起,而不是分开处理。缺点的话就是由于无论输入如何变化,encoder给出的都是一个固定维数的向量,存在信息损失;在生成文本时,生成每个词所用到的语义向量都是一样的,这显然有些过于简单。
2. attention mechanism 注意力机制
为了解决上面提到的问题,一种可行的方案是引入attention mechanism。所谓注意力机制,就是说在生成每个词的时候,对不同的输入词给予不同的关注权重。谷歌博客里介绍神经机器翻译系统时所给出的动图形象地展示了attention:
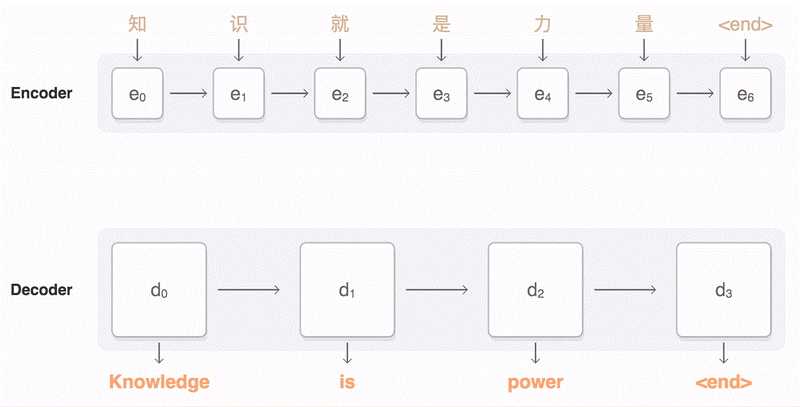
图片来源:https://research.googleblog.com/2016/09/a-neural-network-for-machine.html
[1] 中的一张图也展示了这一点:右侧序列是输入序列,上方序列是输出序列。输出序列的每个词都对应一个概率分布,这个概率分布决定了在生成这个词的时候,对于输入序列的各个词的关注程度。如图所示,看蓝色框起来的那一列,就是模型在生成joint这个词时的概率分布,颜色最深的地方对应的是输入的joint,说明模型在生成joint这个词时最为关注的输入词是joint。所谓attention,就是说生成每个词时都为这个词得到这个概率分布,进而可以使生成的词“更好”。
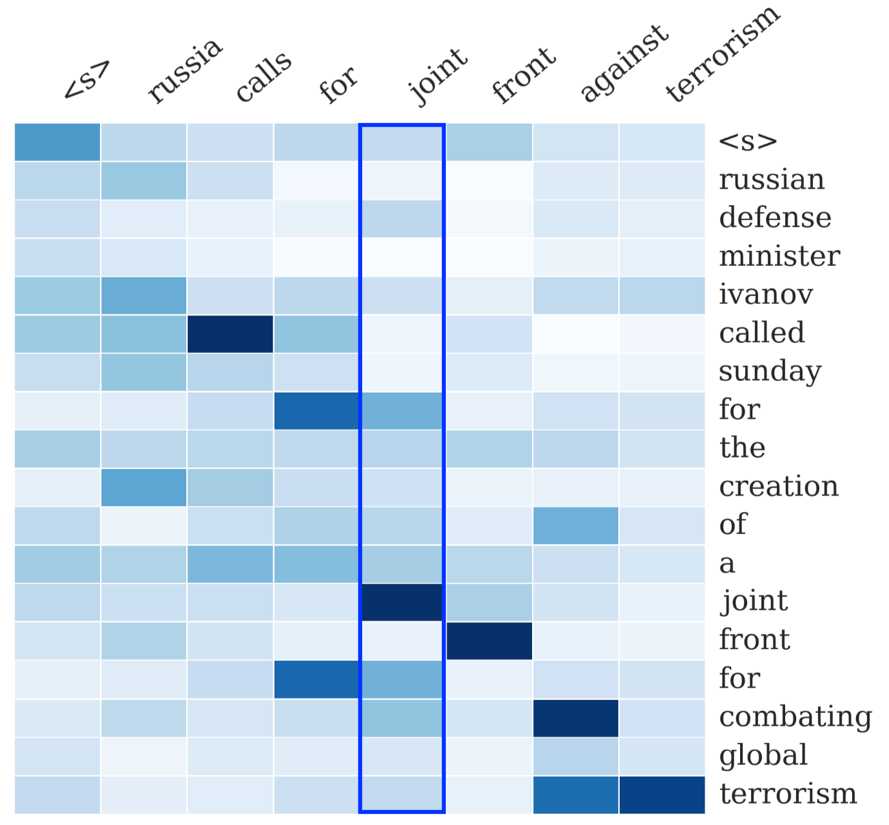
这种机制具体的实现方式将在讲论文的过程中详细介绍。概括来说就是一个data-driven的过程,从大规模的训练语料中学习出来。
3. 实现
下面主要介绍 [2] 。刚才已经说过,文章解决的是句子级别的摘要问题,输入是一个词序列:$\textbf x=[x_1,x_2,...,x_M]$ ,每个词都是词表中的一个(记词表大小为 $V$ ,低频词将被标为UNK);输出也是一个词序列:$\textbf y=[y_1,y_2,...,y_N]$ ,要求长度要短于输入。模型的目标就是下式:
$$\arg\max_yP(y|\textbf x)$$
$y$ 是随机变量,每个可能取值都是一个词序列。给定输入序列,生成某个输出序列的概率可以用下式建模:
$$P(\textbf y|\textbf x;\theta)=\prod_{t=1}^NP(y_t|\{y_1,y_2,...,y_{t-1}\},\textbf x;\theta)$$
所以现在的问题就变成了如何估计给定上文词时生成当前词 $y_t$ 的条件概率 $P(y_t|\{y_1,y_2,...,y_{t-1}\},\textbf x;\theta)$ ,换句话说,就是个训练语言模型的问题。模型训练没什么好说的,就是使用大规模的训练语料,语料的每个样本都是句子-摘要对儿:$\mathcal S=\{(\textbf x^i,\textbf y^i)\}_{i=1}^S$ ,训练方式就是用SGD来最小化负对数似然:
$$\mathcal L=-\sum_{i=1}^S\sum_{t=1}^N\log P(y_t^i|\{y_1^i,y_2^i,...,y_{t-1}^i\},\textbf x^i;\theta)$$
模型训练完成后,给定一个句子来生成摘要:由于每个词都有 $V$ 种可能,如果每个长度为 $N$ 个词的序列都计算一个概率再从中挑出最大的那个的话,代价太大。所以在生成摘要时采用的是beam search的方法:生成第一个词时只保留概率最大的 $k$ 个词,然后生成第二个词时,从 $kV$ 个可能的二元短语里只保留概率最大的 $k$ 个;依次类推,每生成一个词时都只保留 $k$ 个。可以看出这种剪枝操作大大缩小了搜索空间,如果 $k=1$ ,就相当于是一种贪心的策略。beam search原先是统计机器翻译里缩小短语对译时的搜索空间的一种策略,这里把其中的思路借用了过来。
下面就介绍如何建模条件概率。
(1) decoder:RNN-based
这里建模条件概率时使用的是RNNLM。与传统的基于n-gram假设的语言模型不同,RNNLM最大的优势就是在 $t$ 时刻生成一个词时可以利用到此前全部的上文信息,而不是只能利用此前 $n-1$ 个时刻的信息。懒得打字了,直接上图了。。。我presentation里的一页。$d$ 时隐层神经元个数,$c_t$ 就是当前时刻encoder的输出,由于attention机制的存在,每个时刻生成词时对输入序列各个词的关注程度是不一样的,所以encoder在每个时刻给出的输出 $c_t$ 是不一样的,具体如何计算将在下面马上介绍。
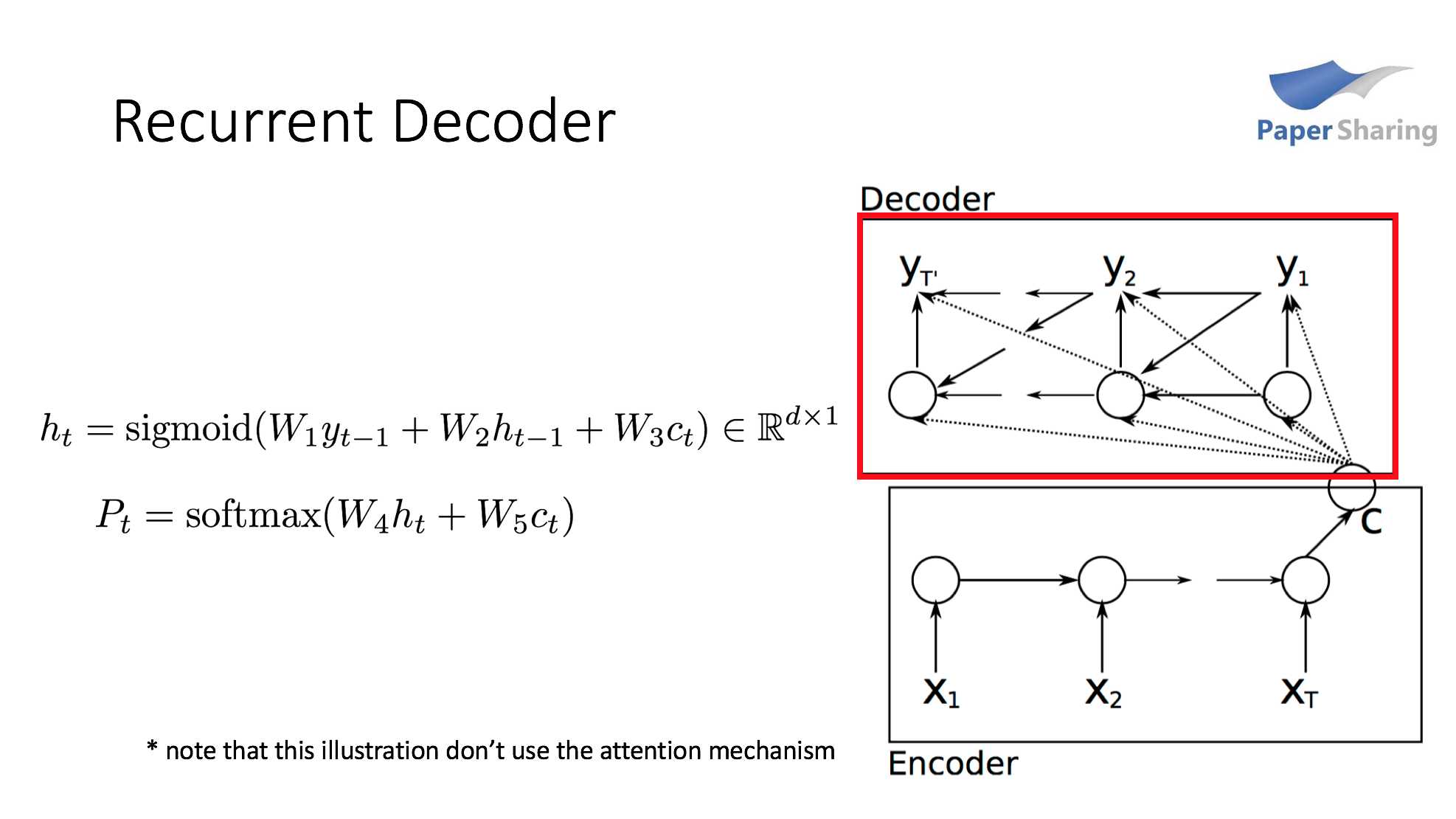
另外,论文中也使用了带LSTM单元的RNN,但是实验部分中介绍道效果并不如最基本的RNN,可能的原因是复杂的模型招致了过拟合。
(note:在 [1] 中,decoder部分用的是2003年Bengio的那个NPLM模型,在以前的博客中介绍过。)
(2) encoder:CNN-based + attention
这篇文章的编码部分使用的是卷积操作,将输入序列 $\textbf x$ 的每个词 $x_i$ 的从原先的词向量 $x_i\in\mathbb R^d$ 编码到了新的空间,得到新的词向量 $z_i\in\mathbb R^d$ ,维数不变(下图所示,实际上是对 $a_i$ 做的卷积,$a_i$ 相比于 $x_i$ 多了一个 $l_i$ ,这代表的是词在序列中的位置信息,与词本身的语义无关,也是通过学习得到的)。
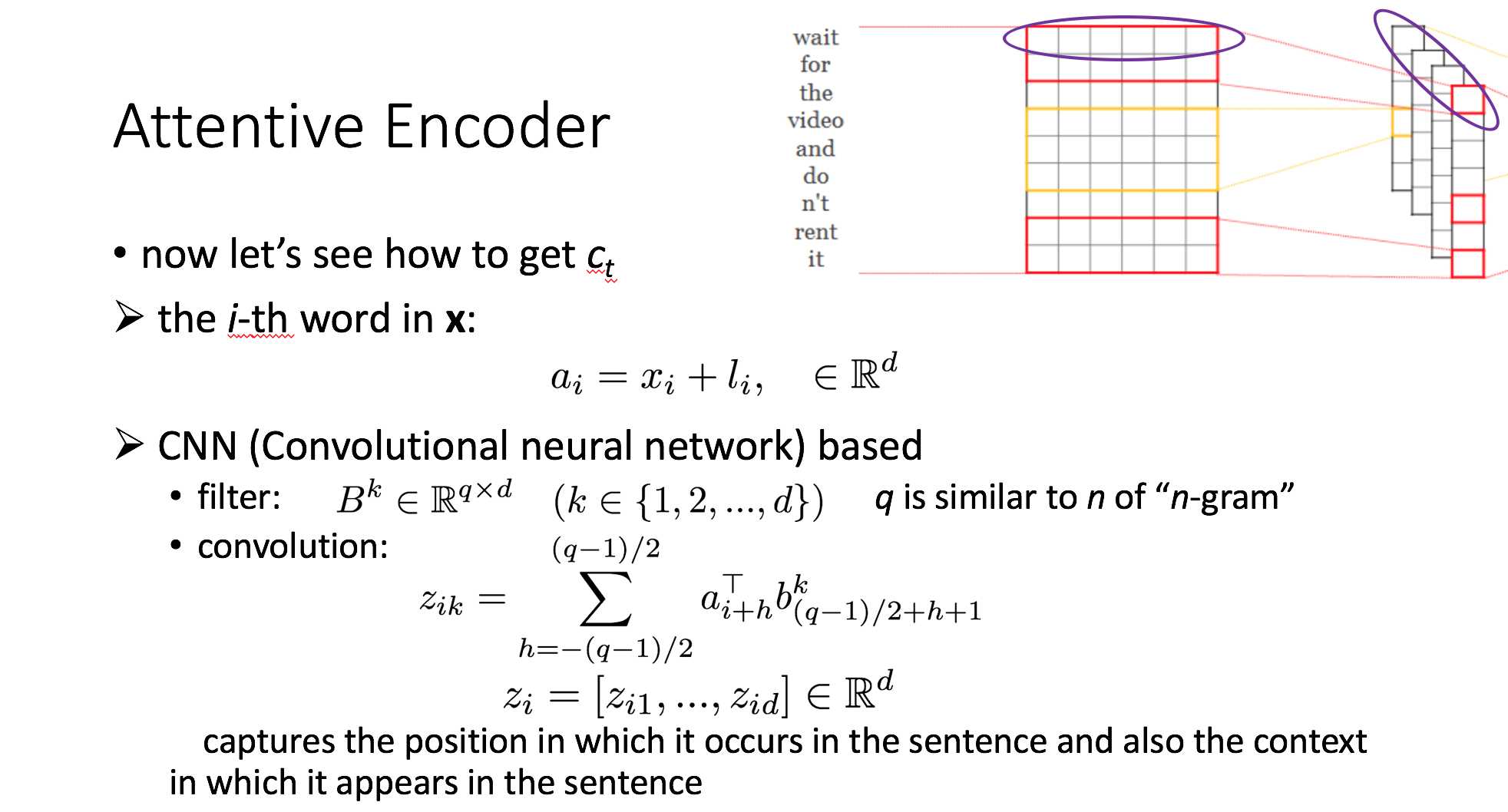
具体来说,共有 $d$ 个卷积核,每个卷积核的大小为 $B^{k}\in\mathbb R^{q\times d}$($k\in\{1,2,...,d\}$ ),也就是说卷积核的宽度是词向量维度,长度是 $q$(可以类比为n-gram中的 n )。换句话说,卷积核对长度为 $q$ 个词的窗口进行特征提取,一个卷积核可以得到一个feature map(图示中的“一列”),$d$ 个卷积核就可以得到 $d$ 列。然后每个 $x_i$ 所对应的 $z_i$ 是什么呢?看图,比如说第一个词,$x_1$ 就是左边的那个紫色圈圈,$z_1$ 就是右边的那个紫色圈圈。到这有一个需要提及的地方——卷积所得到的每个feature map的长度相比于句子长度是变短了啊,怎么做到一一对应?答案就是padding,在卷积之前对句子序列做了padding,使得输出的feature map的长度和句子长度是一致的(这个图是从Yoon Kim的那篇文章截的,放在这只是示意用)。
(note:我觉得论文[2]里卷积的式子写错了,也就是3.2节的式(2),我在slides里写的是我认为正确的。)
卷积完之后,就需要得到 $c_t$ 了,下面就是重头戏,也就是attention的实现方式。刚才说过,attention的目的就是让不同时刻在生成词的时候,对输入序列的各个词的关注程度不同,因此encoder在每个时刻都会输出不同的编码向量。
如何做到对输入序列的各个词的关注程度不同?加权求和呗:
$$c_t=\sum_{j=1}^M\alpha_{j,t-1}x_j\in\mathbb R^d$$
所以,attention的关键就是求那个权重:$\alpha_{j,t-1}$ ,表示的是 $t$ 时刻对词 $x_j$ 的关注程度。
这篇文章使用下面的方式求取:
$$\alpha_{j,t-1}=\frac{\exp(z_j^{\top}h_{t-1})}{\sum_{i=1}^M\exp(z_i^{\top}h_{t-1})}$$
很明显,外层就是一个softmax,起到归一化的作用;核心在于里面的那一项 $z_j^{\top}h_{t-1}$。其中,$z_j$ 是词 $x_j$ 经过编码后的新的词向量,$h_{t-1}$ 则代表的是 $t$ 时刻之前的输出序列信息,也就是即将生成的词 $y_t$ 的上文信息。
本文使用的是内积操作来实现attention,除此之外,还可以在 $z_j$ 和 $h_{t-1}$ 中间夹一个矩阵,这种形式在两个向量不同维的时候可以起到将维度对齐的作用(soft alignment)。当然,维度相同时也可以夹矩阵(如 [3] 中所做),用内积操作的话使得模型的参数得以减少。至于这种看似简单的方式为什么可以显著提升效果,答案就是data-driven。
4. 实验结果
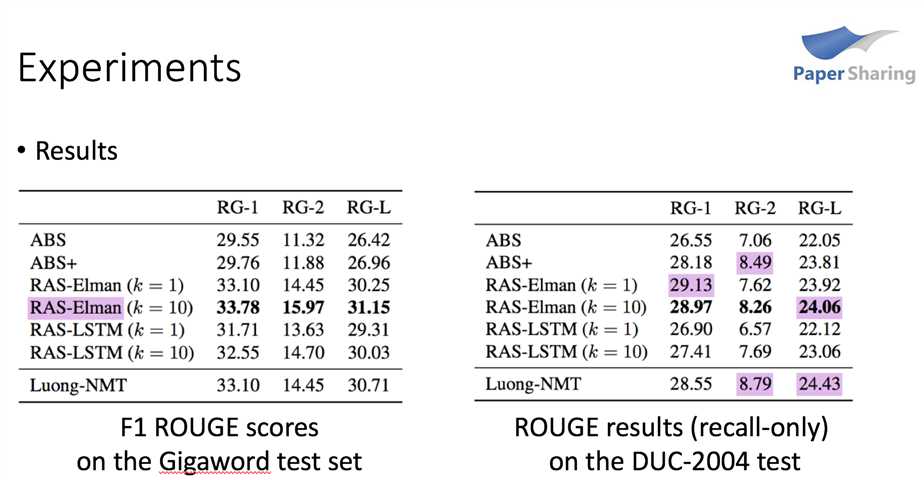
文章使用的训练语料是Gigaword,包含了400万个新闻-标题对儿;测试数据使用两种,一种是从Gigaword里随机选了2000个出来(没有用在训练),另一种是评测数据DUC-2004,包含500个。模型的调参是在验证集上用perplexity这个指标,文章对比了 [1] 的三种encoder和本文的两种encoder(Simple RNN和带LSTM的RNN),结果表明Simple RNN的困惑度是最低的。
下面是测试集上的指标。ABS+就是[1]中的模型,RAS是本文的模型。左边是Gigaword上的测试结果,表明即便是 $k=1$ 这种贪心搜索的情况,RAS也要好于ABS+;而右边是DUC评测上的结果,优势有所削弱,可能是因为训练语料和评测语料的差异。
文章中给出的几个示例。前两个例子表明了RAS对于ABS+的提升,而第三个例子则表明RAS对于比喻句的情况就没有正确理解语义。

四、使用attention机制,生成基于用户查询的抽取式摘要:同时处理句子显著性与查询相关性
下面介绍一篇抽取式摘要的文章,生成的是基于用户查询的摘要。
[3] AttSum: Joint Learning of Focusing and Summarization with Neural Attention,2016COLING
从这篇文章主要可以看到,attention不仅可以用在encoder-decoder的场景,只要是想把两个因素联系起来的场景其实都可以用。
传统的方案是先对句子的显著性进行打分,再对句子和查询的相关性进行打分,二者合并得到最终打分;而这篇文章的核心idea是将两个打分合并在一起:首先将句子、查询都用CNN表示成向量,然后使用attention给出文档中的句子权重,然后基于此将句子向量加权得到文档向量,再计算文档向量和句子向量的相似度,给出句子打分。最后用MMR去冗余。此外,训练时采用了pairwise的方式,并且用的是hinge loss。如果去掉句子权重,那这个过程就相当于只对句子显著性进行了打分。
先放上slides,以后有时间的话再补充文字吧。。。



五、总结
总的来说,用seq2seq做自动摘要主要沿袭了神经机器翻译的“模样”,但二者又有显著不同,例如翻译是要尽可能不损失信息,而摘要是只保留最关键信息;翻译的输出序列长度正比于输入序列长度,而摘要的输出序列长度要短于输入序列长度;从遇到的问题来说,翻译中存在过翻、漏翻,而摘要则面临生成的词在语料中是罕见词等问题。因此,用于这两个任务的辅助机制既有共同点(如最小风险训练),更有区别(翻译有Coverage机制,摘要有CopyNet机制)。
参考资料:
[1] A Neural Attention Model for Abstractive Sentence Summarization,2015EMNLP
[2] Abstractive Sentence Summarization with Attentive Recurrent Neural Networks,2016NAACL
[3] AttSum: Joint Learning of Focusing and Summarization with Neural Attention,2016COLING
[4] 《统计自然语言处理》
DL4NLP —— seq2seq+attention机制的应用:文档自动摘要(Automatic Text Summarization)
标签:存在 位置 http arch pip 保留 分享 图形 play
原文地址:http://www.cnblogs.com/Determined22/p/6577394.html