标签:viterbi merge 前言 java getter null value 动态 并且
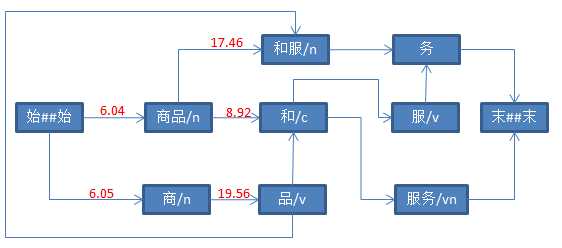
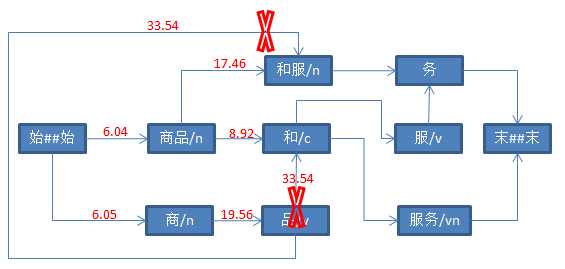
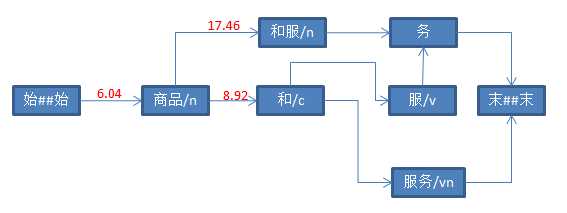
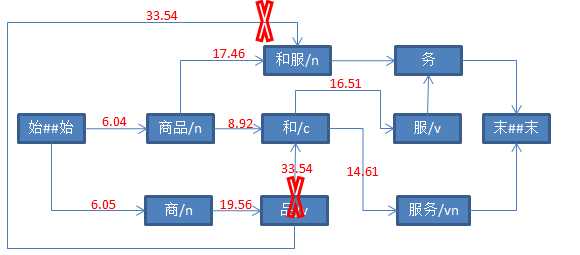
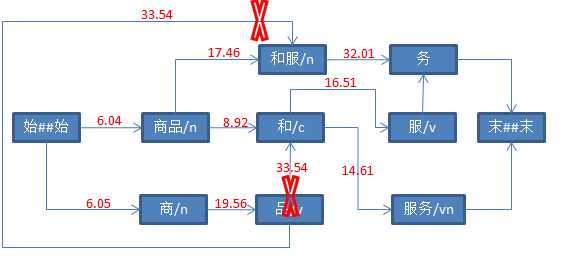
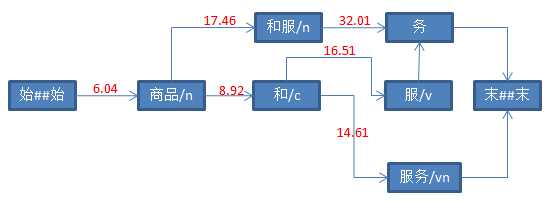
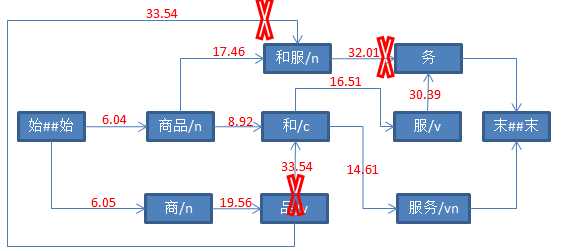
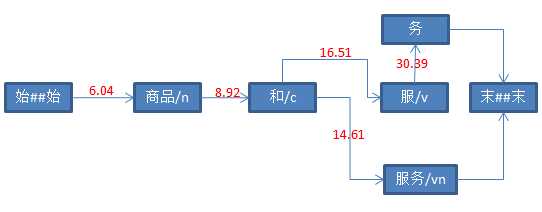
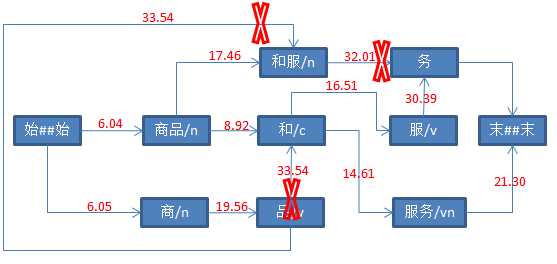
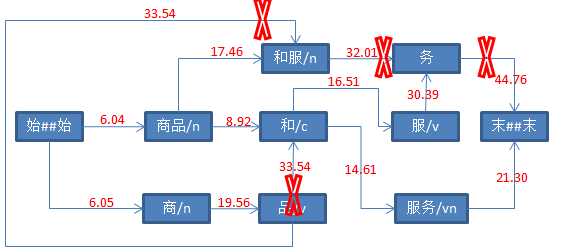
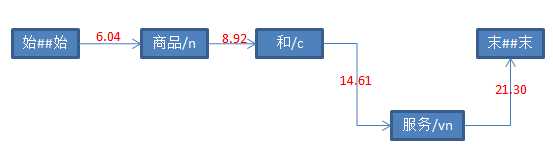
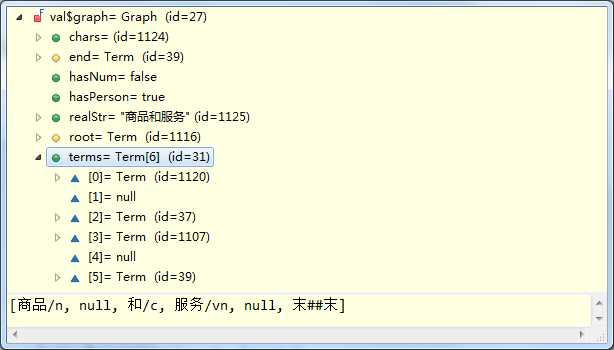
String str = "商品和服务" ; Result result = ToAnalysis.parse(str); System.out.println(result.getTerms());
graph.walkPath();
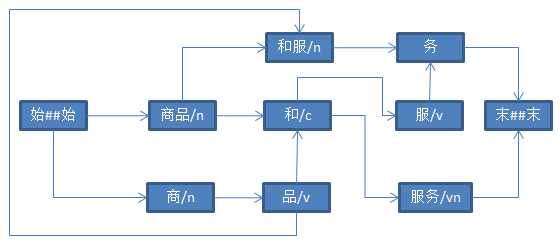
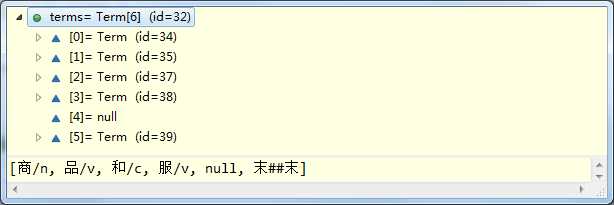
char c = chars[to];
TermNatures tn = DATDictionary.getItem(c).termNatures;
if (tn == null || tn == TermNatures.NULL) {
tn = TermNatures.NULL;
}
terms[to] = new Term(String.valueOf(c), to, tn);
double value = -Math.log(dSmoothingPara * frequency / (MAX_FREQUENCE + 80000) + (1 - dSmoothingPara) * ((1 - dTemp) * nTwoWordsFreq / frequency + dTemp));
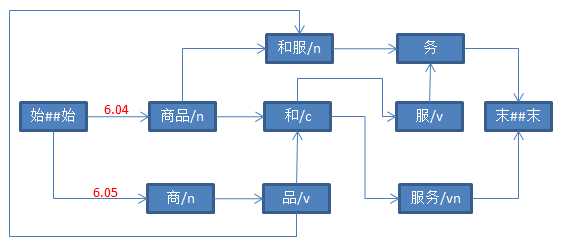
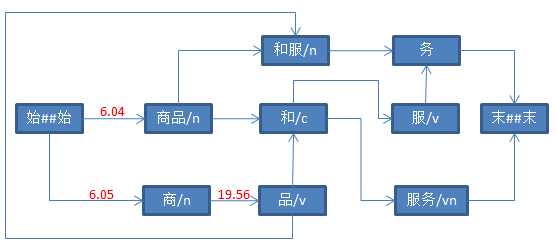
标签:viterbi merge 前言 java getter null value 动态 并且
原文地址:http://www.cnblogs.com/royhoo/p/6653538.html