标签:str group sample rand original methods result lin rem
Resampling methods involve repeatedly drawing samples from a training set and refitting a model of interest on each sample in order to obtain additional information about the fitted model.
In this chapter, we discuss two of the most commonly used resampling methods, cross-validation and the bootstrap.
5.1 Cross-Validation
5.1.1 The Validation Set Approach
It involves randomly dividing the available set of samples into two parts, a training set and a validation set or hold-out set. The model is fit on the training set, and the fitted model is used to predict the responses for the observations in the validation set.
5.1.2 Leave-one-out cross-validation (LOOCV)
Like the validation set approach, LOOCV involves splitting the set of observations into two parts. However, instead of creating two subsets of comparable size, a single observation (x1,y1) is used for the validation set, and the remaining observations {(x2, y2), . . . , (xn, yn)} make up the training set.
5.1.3 k-Fold Cross-Validation
An alternative to LOOCV is k-fold CV. This approach involves randomly dividing the set of observations into k groups, or folds, of approximately equal size. The first fold is treated as a validation set, and the method is fit on the remaining k ? 1 folds.
5.1.4 Bias-Variance Trade-Off for k-Fold Cross-Validation
The test error estimate resulting from LOOCV tends to have higher variance than does the test error estimate resulting from k-fold CV.
Typically, one performs k-fold cross-validation using k = 5 or k = 10.
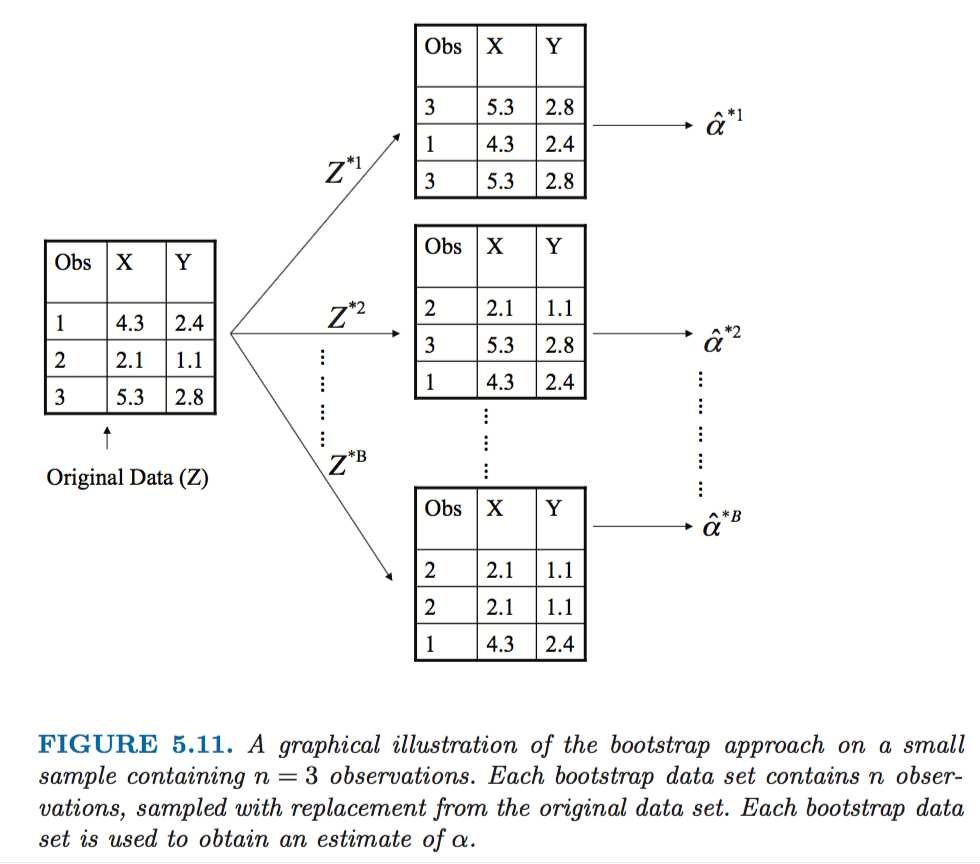
5.2 The Bootstrap
Each bootstrap data set contains n observations, sampled with replacement from the original data set.
标签:str group sample rand original methods result lin rem
原文地址:http://www.cnblogs.com/sheepshaker/p/6664008.html