标签:启动 名称 序列 标准 front 控制 访问控制列表 结构 连接
Zookeeper是一个分布式协调服务;就是为用户的分布式应用程序提供协调服务
管理(存储,读取)用户程序提交的数据;
并为用户程序提供数据节点监听服务;
半数机制:集群中半数以上机器存活,集群可用。
zookeeper适合装在奇数台机器上!!!
1、Zookeeper:一个leader,多个follower组成的集群
2、全局数据一致:每个server保存一份相同的数据副本,client无论连接到哪个server,数据都是一致的
3、分布式读写,更新请求转发,由leader实施
4、更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行
5、数据更新原子性,一次数据更新要么成功,要么失败
6、实时性,在一定时间范围内,client能读到最新数据
1、层次化的目录结构,命名符合常规文件系统规范(见下图:数据结构图)
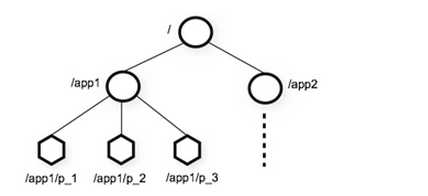
2、每个节点在zookeeper中叫做znode,并且其有一个唯一的路径标识
3、节点Znode可以包含数据和子节点(但是EPHEMERAL类型的节点不能有子节点)
4、客户端应用可以在节点上设置监视器
1、Znode有两种类型:
短暂(ephemeral)(断开连接自己删除)
持久(persistent)(断开连接不删除)
2、Znode有四种形式的目录节点(默认是persistent )
PERSISTENT
PERSISTENT_SEQUENTIAL(持久序列/test0000000019 )
EPHEMERAL
EPHEMERAL_SEQUENTIAL
3、创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护
4、在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序
运行 zkCli.sh –server <ip>进入命令行工具
1、使用 ls 命令来查看当前 ZooKeeper 中所包含的内容:
[zk: 202.115.36.251:2181(CONNECTED) 1] ls /
2、创建一个新的 znode ,使用 create /zk myData 。这个命令创建了一个新的 znode 节点“ zk ”以及与它关联的字符串:
[zk: 202.115.36.251:2181(CONNECTED) 2] create /zk "myData“
3、我们运行 get 命令来确认 znode 是否包含我们所创建的字符串:
[zk: 202.115.36.251:2181(CONNECTED) 3] get /zk
4、下面我们通过 set 命令来对 zk 所关联的字符串进行设置:
[zk: 202.115.36.251:2181(CONNECTED) 4] set /zk "zsl“
5、下面我们将刚才创建的 znode 删除:
[zk: 202.115.36.251:2181(CONNECTED) 5] delete /zk
6、删除节点:rmr
[zk: 202.115.36.251:2181(CONNECTED) 5] rmr /zk
org.apache.zookeeper.Zookeeper是客户端入口主类,负责建立与server的会话
它提供了表 1 所示几类主要方法 :
|
功能 |
描述 |
|
create |
在本地目录树中创建一个节点 |
|
delete |
删除一个节点 |
|
exists |
测试本地是否存在目标节点 |
|
get/set data |
从目标节点上读取 / 写数据 |
|
get/set ACL |
获取 / 设置目标节点访问控制列表信息 |
|
get children |
检索一个子节点上的列表 |
|
sync |
等待要被传送的数据 |
Zookeeper的监听器工作机制
监听器是一个接口,我们的代码中可以实现Wather这个接口,实现其中的process方法,方法中即我们自己的业务逻辑
监听器的注册是在获取数据的操作中实现:
getData(path,watch?)监听的事件是:节点数据变化事件
getChildren(path,watch?)监听的事件是:节点下的子节点增减变化事件
某分布式系统中,主节点可以有多台,可以动态上下线
任意一台客户端都能实时感知到主节点服务器的上下线
Zookeeper虽然在配置文件中并没有指定master和slave
但是,zookeeper工作时,是有一个节点为leader,其他则为follower
Leader是通过内部的选举机制临时产生的
以一个简单的例子来说明整个选举的过程.
假设有五台服务器组成的zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的.假设这些服务器依序启动,来看看会发生什么.
那么,初始化的时候,是按照上述的说明进行选举的,但是当zookeeper运行了一段时间之后,有机器down掉,重新选举时,选举过程就相对复杂了。
需要加入数据id、leader id和逻辑时钟。
数据id:数据新的id就大,数据每次更新都会更新id。
Leader id:就是我们配置的myid中的值,每个机器一个。
逻辑时钟:这个值从0开始递增,每次选举对应一个值,也就是说: 如果在同一次选举中,那么这个值应该是一致的 ; 逻辑时钟值越大,说明这一次选举leader的进程更新.
选举的标准就变成:
1、逻辑时钟小的选举结果被忽略,重新投票
2、统一逻辑时钟后,数据id大的胜出
3、数据id相同的情况下,leader id大的胜出
根据这个规则选出leader。
标签:启动 名称 序列 标准 front 控制 访问控制列表 结构 连接
原文地址:http://www.cnblogs.com/atomicbomb/p/6666608.html