标签:tree syslog ted 2.3 clock pen sch 生产环境 persist
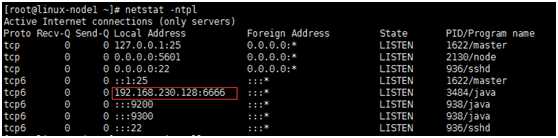
#Input plugins TCP插件 所需的配置选项 tcp { port =>... } [root@linux-node1 ~]# cat tcp.conf input { tcp { host =>"192.168.230.128" port =>"6666" } } output { stdout{ codec =>"rubydebug" } }
[root@linux-node1 ~]# /opt/logstash/bin/logstash -f tcp.conf
打开另外一个窗口,进行测试查看
[root@linux-node1 ~]# echo "hehe"|nc192.168.230.1286666 [root@linux-node1 ~]# echo "oldboy">/dev/tcp/192.168.230.128/6666 #伪终端 [root@linux-node1 ~]# nc 192.168.230.1286666</etc/resolv.conf #还可以追加文件 查看第一个窗口
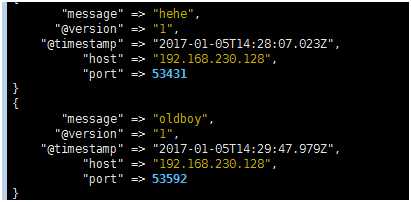
#TCP用于什么呢,在工作中用于这种要往哪个索引追加一些东西,它们之间漏掉了,通过某种方法写成文件,可以使用nc直接附加进去,也可以弄个文件再收一遍,但那个比较费劲 #如果文件较大,时间较长,可以使用screen
之前学习了Input Output 现在来学习Filter
Filter插件 grok filter插件有很多,在这里就学习grok插件,使用正则匹配日志里的域来拆分。在实际生产中,apache日志不支持jason,就只能使用grok插件匹配;mysql慢查询日志也是无法拆分,只能石油grok正则表达式匹配拆分。 在如下链接,github上有很多写好的grok模板,可以直接引用 https://github.com/logstash-plugins/logstash-patterns-core/blob/master/patterns/grok-patterns 官方链接地址 https://www.elastic.co/guide/en/logstash/2.3/plugins-filters-grok.html #Logstash附带120默认模式。你可以在这里找到 Logstash ships with about 120 patterns by default. You can find them here: https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns. You can add your own trivially. (See the patterns_dir setting) Examples: With that idea of a syntax and semantic, we can pull out useful fields from a sample log like this fictional http request log: 55.3.244.1 GET /index.html 158240.043 The pattern for this could be: 预定义的正则表达式,可以来引用 %{IP:client}%{WORD:method}%{URIPATHPARAM:request}%{NUMBER:bytes}%{NUMBER:duration} A more realistic example, let’s read these logs from a file: input { file{ path =>"/var/log/http.log" } } filter { grok { match =>{"message"=>"%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"} } } After the grok filter, the event will have a few extra fields in it: #使用filter grok后,会输出以下字段 client:55.3.244.1 method: GET request:/index.html bytes:15824 duration:0.043 我们来测试一下 [root@linux-node1 ~]# cat grok.conf input { stdin {} } filter { grok { match =>{"message"=>"%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"} } } output { stdout { codec =>"rubydebug" } } [root@linux-node1 ~]# /opt/logstash/bin/logstash -f grok.conf Settings: Default pipeline workers:2 Pipeline main started 55.3.244.1 GET /index.html 158240.043#输入这一行 { "message"=>"55.3.244.1 GET /index.html 15824 0.043", "@version"=>"1", "@timestamp"=>"2017-01-05T15:21:49.510Z", "host"=>"linux-node1.example.com", "client"=>"55.3.244.1",#自动引入了client "method"=>"GET", "request"=>"/index.html", "bytes"=>"15824", "duration"=>"0.043" } 那怎么自动引入的呢,系统在安装完软件的时候已经帮我们内置了 [root@linux-node1 patterns]# pwd #在这个目录下的grok-patterns文件 /opt/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-2.0.5/patterns
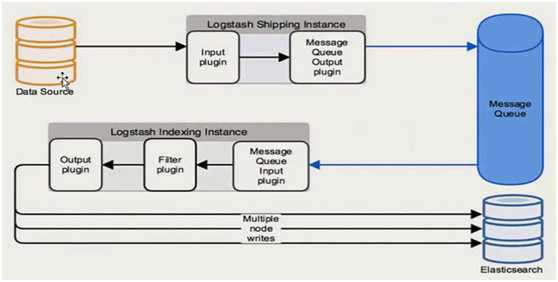
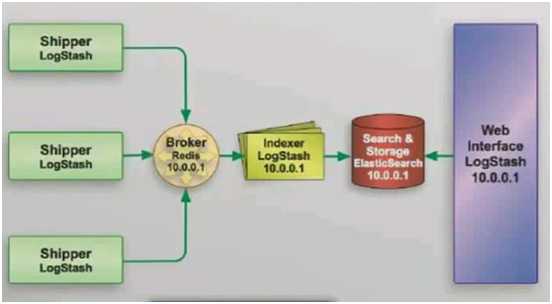
数据源Datasource把数据写到input插件中,output插件使用消息队列把消息写入到消息队列Message Queue中,Logstash indexing Instance启动logstash使用input插件读取消息队列中的信息,Fliter插件过滤后在使用output写入到elasticsearch中。
如果生产环境中不适用正则grok匹配,可以写Python脚本从消息队列中读取信息,输出到elasticsearch中
redis用来解耦
解耦,松耦合
解除了由于网络原因不能直接连elasticsearch的情况
方便架构演变,增加新内容
消息队列可以使用rabbitmq,zeromq等,也可以使用redis,kafka(消息不删除,但是比较重量级)等
引入redis到架构中
#安装redis yum-y install redis #修改下配置文件 [root@linux-node1 conf.d]# grep ‘^[a-z]‘/etc/redis.conf daemonize yes #修改这行为yes,改成在后台运行 pidfile /var/run/redis/redis.pid port 6379 tcp-backlog 511 bind 192.168.230.128#监听的IP [root@linux-node1 conf.d]# systemctl start redis [root@linux-node1 conf.d]# netstat -ntpl|grep6379 tcp 00192.168.230.128:63790.0.0.0:* LISTEN 2998/redis-server 1 #我们来测试一下 [root@linux-node1 conf.d]# cat redis-out.conf input { stdin{} } output { redis { host =>"192.168.230.128" port =>"6379" db =>"6" data_type =>"list"#数据类型为list key =>"demo" } } #启动配置文件输入信息 [root@linux-node1 conf.d]# /opt/logstash/bin/logstash -f redis-out.conf Settings: Default pipeline workers:4 Pipeline main started chuck #输入 sisi #开另外一个窗口连接,info查看 [root@linux-node1 conf.d]# redis-cli -h 192.168.230.128 192.168.230.128:6379> info # Server redis_version:2.8.19 redis_git_sha1:00000000 redis_git_dirty:0 redis_build_id:c0359e7aa3798aa2 redis_mode:standalone os:Linux 3.10.0-123.el7.x86_64 x86_64 arch_bits:64 multiplexing_api:epoll gcc_version:4.8.3 process_id:6518 run_id:3ab08fa2b91c79194b9f5c15b7c54680461f6e07 tcp_port:6379 uptime_in_seconds:165 uptime_in_days:0 hz:10 lru_clock:10407823 config_file:/etc/redis.conf # Clients connected_clients:2 client_longest_output_list:0 client_biggest_input_buf:0 blocked_clients:0 # Memory used_memory:2211840 used_memory_human:2.11M used_memory_rss:2895872 used_memory_peak:2211840 used_memory_peak_human:2.11M used_memory_lua:35840 mem_fragmentation_ratio:1.31 mem_allocator:jemalloc-3.6.0 # Persistence loading:0 rdb_changes_since_last_save:2 rdb_bgsave_in_progress:0 rdb_last_save_time:1486802666 rdb_last_bgsave_status:ok rdb_last_bgsave_time_sec:-1 rdb_current_bgsave_time_sec:-1 aof_enabled:0 aof_rewrite_in_progress:0 aof_rewrite_scheduled:0 aof_last_rewrite_time_sec:-1 aof_current_rewrite_time_sec:-1 aof_last_bgrewrite_status:ok aof_last_write_status:ok # Stats total_connections_received:2 total_commands_processed:3 instantaneous_ops_per_sec:0 total_net_input_bytes:316 total_net_output_bytes:13 instantaneous_input_kbps:0.00 instantaneous_output_kbps:0.00 rejected_connections:0 sync_full:0 sync_partial_ok:0 sync_partial_err:0 expired_keys:0 evicted_keys:0 keyspace_hits:0 keyspace_misses:0 pubsub_channels:0 pubsub_patterns:0 latest_fork_usec:0 # Replication role:master connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0 # CPU used_cpu_sys:0.25 used_cpu_user:0.02 used_cpu_sys_children:0.00 used_cpu_user_children:0.00 # Keyspace db6:keys=3,expires=0,avg_ttl=0#输出的内容,创建了这个db 6 ,里边有一个key 192.168.230.128:6379> select 6#选择db 6 OK 192.168.230.128:6379[6]> keys *#里边有个demo,选择demo这个key 1)"demo" 这是一个列表,怎么查看这个消息 192.168.230.128:6379[6]> LINDEX demo -1# -1表示最后一行,从内容上看已经写进去了(信息、主机、时间戳等) "{\"message\":\"sisi\",\"@version\":\"1\",\"@timestamp\":\"2017-01-26T13:14:37.766Z\",\"host\":\"linux-node1.example.com\"}" 192.168.230.128:6379[6]> LINDEX demo -2 "{\"message\":\"chuck\",\"@version\":\"1\",\"@timestamp\":\"2017-02-11T08:46:47.597Z\",\"host\":\"linux-node1.example.com\"}" 为了下一步写input插件到把消息发送到elasticsearch中,多在redis中写入写数据 [root@linux-node1 ~]# /opt/logstash/bin/logstash -f redis-out.conf Settings: Default filter workers:1 Logstash startup completed chuck sisi a b c d e f g h i j k l m n o p q r s t u v w x y z k l m n g s #查看redis中名字为demo的key长度 192.168.230.128:6379[6]> LLEN demo (integer)31 #使用redis发送消息到elasticsearch中 编写redis-in.conf [root@linux-node1 conf.d]# cp redis-out-conf redis-in-conf [root@linux-node1 conf.d]# cat redis-in-conf input { redis { host =>"192.168.230.128" port =>"6379" db =>"6" data_type =>"list" key =>"demo" } } output { elasticsearch { hosts =>["192.168.230.128:9200"] index =>"redis-demo-%{+YYY.MM.dd}" } } #启动配置文件 [root@linux-node1 conf.d]# /opt/logstash/bin/logstash -f redis-in-conf Settings: Default pipeline workers:4 Pipeline main started #不断刷新demo这个key的长度(读取很快,刷新一定要速度) 192.168.230.128:6379[6]> LLEN demo (integer)25 192.168.230.128:6379[6]> LLEN demo (integer)7#可以看到redis的消息正在写入到elasticsearch中 192.168.230.128:6379[6]> LLEN demo (integer)0
在elasticsearch中查看增加了redis-demo,由于在不同时间点添加的,所以有两个索引

将all.conf的内容改为经由redis 编写shipper.conf作为redis收集logstash配置文件 [root@linux-node1 conf.d]# cat shipper.conf input{ syslog { type=>"system-syslog" host =>"192.168.230.128" port =>"514" } file{ path =>"/var/log/nginx/access_json.log" codec => json start_position =>"beginning" type=>"nginx-log" } file{ path =>"/var/log/messages" type=>"system" start_position =>"beginning" } file{ path =>"/var/log/elasticsearch/check-cluster.log" type=>"es-error" start_position =>"beginning" codec => multiline { pattern =>"^\[" negate => true what =>"previous" } } } output{ if[type]=="system"{ redis { host =>"192.168.230.128" port =>"6379" db =>"6" data_type =>"list" key =>"system" } } if[type]=="es-error"{ redis { host =>"192.168.230.128" port =>"6379" db =>"6" data_type =>"list" key =>"es-error" } } if[type]=="system-syslog"{ redis { host =>"192.168.230.128" port =>"6379" db =>"6" data_type =>"list" key =>"system-syslog" } } if[type]=="nginx-log"{ redis { host =>"192.168.230.128" port =>"6379" db =>"6" data_type =>"list" key =>"nginx-log" } } } #在redis中查看keys 192.168.230.128:6379[6]> select 6 192.168.230.128:6379[6]> keys * 1)"system" 2)"system-syslog" 3)"es-error" 编写indexer.conf作为redis发送elasticsearch配置文件 [root@linux-node2 /]# cat indexer.conf input{ redis { type=>"system" host =>"192.168.230.128" port =>"6379" db =>"6" data_type =>"list" key =>"system" } redis { type=>"es-error" host =>"192.168.230.128" port =>"6379" db =>"6" data_type =>"list" key =>"es-error" } redis { type=>"system-syslog" host =>"192.168.230.128" port =>"6379" db =>"6" data_type =>"list" key =>"system-syslog" } redis { type=>"nginx-log" host =>"192.168.230.128" port =>"6379" db =>"6" data_type =>"list" key =>"nginx-log" } } output{ if[type]=="system"{ elasticsearch { hosts =>["192.168.230.128:9200"] index =>"system-%{+YYY.MM.dd}" } } if[type]=="es-error"{ elasticsearch { hosts =>["192.168.230.128:9200"] index =>"es-error-%{+YYY.MM.dd}" } } if[type]=="system-syslog"{ elasticsearch { hosts =>["192.168.230.128:9200","192.168.230.129:9200"] index =>"system-syslog-%{+YYY.MM.dd}" } } if[type]=="nginx-log"{ elasticsearch { hosts =>["192.168.230.128:9200","192.168.230.129:9200"] index =>"nginx-log-%{+YYY.MM.dd}" } } } #启动shipper.conf [root@linux-node1 conf.d]# /opt/logstash/bin/logstash -f shipper.conf Settings: Default pipeline workers:4 Pipeline main started 由于日志量小,很快就会全部被发送到elasticsearch,key也就没了,所以多写写数据到日志中 [root@linux-node1 conf.d]# for n in `seq 10000`;doecho$n>>/var/log/nginx/access_json.log;done [root@linux-node1 conf.d]# for n in `seq 10000`;doecho$n>>/var/log/messages;done [root@linux-node1 conf.d]# for n in `seq 10000`;doecho$n>>/var/log/elasticsearch/check-cluster.log;done 查看key的长度看到key在增长 192.168.230.128:6379[6]> LLEN nginx-log (integer)2450 192.168.230.128:6379[6]> LLEN nginx-log (integer)2680 192.168.230.128:6379[6]> LLEN nginx-log (integer)2920 #启动indexer.conf [root@linux-node1 conf.d]# /opt/logstash/bin/logstash -f indexer.conf Settings: Default pipeline workers:4 Pipeline main started #查看key的长度看到key在减小 192.168.230.128:6379[6]> LLEN nginx-log (integer)20000 192.168.230.128:6379[6]> LLEN nginx-log (integer)19875 192.168.230.128:6379[6]> LLEN nginx-log (integer)19875 192.168.230.128:6379[6]> LLEN nginx-log (integer)19750 192.168.230.128:6379[6]> LLEN nginx-log (integer)19750
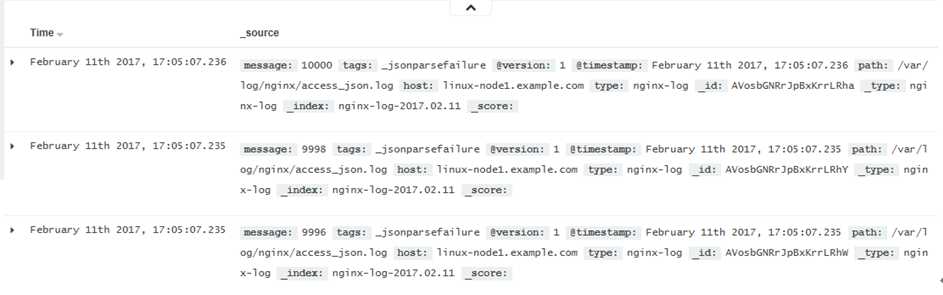
kibana查看nginx-log索引
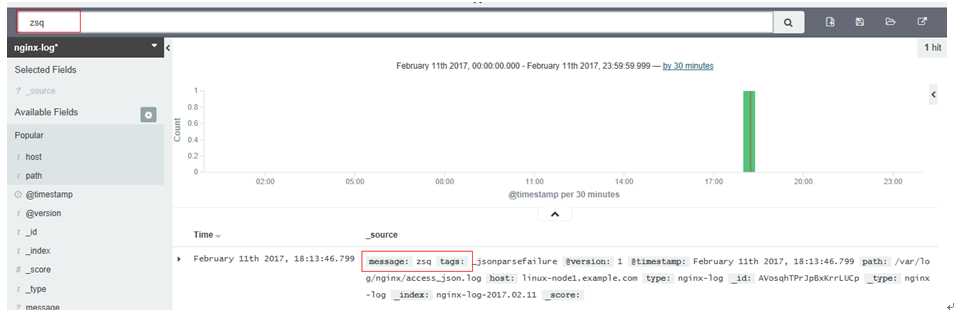
实时写入测试,节点1启动shipper.conf [root@linux-node1 conf.d]# /opt/logstash/bin/logstash -f shipper.conf Settings: Default pipeline workers:4 Pipeline main started #在节点2上启动indexer.conf [root@linux-node2 /]# /opt/logstash/bin/logstash -f indexer.conf OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N Settings: Default pipeline workers:1 Pipeline main started #在nginx log上增加点东西 [root@linux-node1 conf.d]# for n in `echo zsq`;doecho$n>>/var/log/nginx/access_json.log;done
Kibana搜索查看关键字
标签:tree syslog ted 2.3 clock pen sch 生产环境 persist
原文地址:http://www.cnblogs.com/w787815/p/6676338.html