标签:请求 upd 文件 自己 执行 术语 emc started 查找

ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
elasticsearch是一个近似实时的搜索平台,从索引文档到可搜索有些延迟,通常为1秒。
集群就是一个或多个节点存储数据,其中一个节点为主节点,这个主节点是可以通过选举产生的,并提供跨节点的联合索引和搜索的功能。集群有一个唯一性标示的名字,默认是elasticsearch,集群名字很重要,每个节点是基于集群名字加入到其集群中的。因此,确保在不同环境中使用不同的集群名字。一个集群可以只有一个节点。强烈建议在配置elasticsearch时,配置成集群模式。
节点就是一台单一的服务器,是集群的一部分,存储数据并参与集群的索引和搜索功能。像集群一样,节点也是通过名字来标识,默认是在节点启动时随机分配的字符名。当然啦,你可以自己定义。该名字也蛮重要的,在集群中用于识别服务器对应的节点。
节点可以通过指定集群名字来加入到集群中。默认情况下,每个节点被设置成加入到elasticsearch集群。如果启动了多个节点,假设能自动发现对方,他们将会自动组建一个名为elasticsearch的集群。
索引是有几分相似属性的一系列文档的集合。如nginx日志索引、syslog索引等等。索引是由名字标识,名字必须全部小写。这个名字用来进行索引、搜索、更新和删除文档的操作。
索引相对于关系型数据库的库。
在一个索引中,可以定义一个或多个类型。类型是一个逻辑类别还是分区完全取决于你。通常情况下,一个类型被定于成具有一组共同字段的文档。如ttlsa运维生成时间所有的数据存入在一个单一的名为logstash-ttlsa的索引中,同时,定义了用户数据类型,帖子数据类型和评论类型。
类型相对于关系型数据库的表。
文档是信息的基本单元,可以被索引的。文档是以JSON格式表现的。
在类型中,可以根据需求存储多个文档。
虽然一个文档在物理上位于一个索引,实际上一个文档必须在一个索引内被索引和分配一个类型。
文档相对于关系型数据库的列。
分片和副本
在实际情况下,索引存储的数据可能超过单个节点的硬件限制。如一个十亿文档需1TB空间可能不适合存储在单个节点的磁盘上,或者从单个节点搜索请求太慢了。为了解决这个问题,elasticsearch提供将索引分成多个分片的功能。当在创建索引时,可以定义想要分片的数量。每一个分片就是一个全功能的独立的索引,可以位于集群中任何节点上。
分片的两个最主要原因:
a、水平分割扩展,增大存储量
b、分布式并行跨分片操作,提高性能和吞吐量
分布式分片的机制和搜索请求的文档如何汇总完全是有elasticsearch控制的,这些对用户而言是透明的。
网络问题等等其它问题可以在任何时候不期而至,为了健壮性,强烈建议要有一个故障切换机制,无论何种故障以防止分片或者节点不可用。
为此,elasticsearch让我们将索引分片复制一份或多份,称之为分片副本或副本。
副本也有两个最主要原因:
高可用性,以应对分片或者节点故障。出于这个原因,分片副本要在不同的节点上。
提供性能,增大吞吐量,搜索可以并行在所有副本上执行。
总之,每一个索引可以被分成多个分片。索引也可以有0个或多个副本。复制后,每个索引都有主分片(母分片)和复制分片(复制于母分片)。分片和副本数量可以在每个索引被创建时定义。索引创建后,可以在任何时候动态的更改副本数量,但是,不能改变分片数。
默认情况下,elasticsearch为每个索引分片5个主分片和1个副本,这就意味着集群至少需要2个节点。索引将会有5个主分片和5个副本(1个完整副本),每个索引总共有10个分片。
每个elasticsearch分片是一个Lucene索引。一个单个Lucene索引有最大的文档数LUCENE-5843, 文档数限制为2147483519(MAX_VALUE – 128)。 可通过_cat/shards来监控分片大小。
LogStash由JRuby语言编写,基于消息(message-based)的简单架构,并运行在Java虚拟机(JVM)上。不同于分离的代理端(agent)或主机端(server),LogStash可配置单一的代理端(agent)与其它开源软件结合,以实现不同的功能。
? Shipper:发送事件(events)至LogStash;通常,远程代理端(agent)只需要运行这个组件即可;
? Broker and Indexer:接收并索引化事件;
? Search and Storage:允许对事件进行搜索和存储;
? Web Interface:基于Web的展示界面
正是由于以上组件在LogStash架构中可独立部署,才提供了更好的集群扩展性。
Kibana 也是一个开源和免费的工具,他可以帮助您汇总、分析和搜索重要数据日志并提供友好的web界面。他可以为 Logstash 和 ElasticSearch 提供的日志分析的 Web 界面
准备两台机器,以下是其中一台做为master的机器
[root@linux-node1 ~]# cat /etc/redhat-release CentOS Linux release 7.0.1406 (Core) [root@linux-node1 ~]# uname -a Linux linux-node1.example.com 3.10.0-123.el7.x86_64 #1 SMP Mon Jun 30 12:09:22 UTC 2014 x86_64 x86_64 x86_64 GNU/Linux [root@linux-node1 ~]# tail -2 /etc/hosts 192.168.230.128 linux-node1 linux-node1.example.com 192.168.230.129 linux-node2 linux-node2.example.com [root@linux-node1 ~]# ifconfig eth0|awk -F ‘[ :]+‘ ‘NR==2{print $3}‘ 192.168.230.128 [root@linux-node1~]# systemctl stop firewalld [root@linux-node1~]# getenforce 0 Disabled [root@linux-node1~ /]# systemctl disable firewalld.service
时间同步
echo "#time sync by zsq at $(date +%F)" >> /var/spool/cron/root echo "*/5 * * * * /usr/sbin/ntpdate time.nist.gov &>/dev/null" >>/var/spool/cron/root
重启crond
/sbin/service crond restart
理想实践是给2G内存,我这里给1.5G,elasticsearch做集群还需要一台相同的配置
[root@linux-node1 ~]# free -m total used free shared buffers cached Mem:146751894880142
最佳实践cpu给2颗
[root@linux-node1 ~]# cat /proc/cpuinfo |grep"physical id"|sort|uniq|wc -l 2
需要有java环境
[root@linux-node1 ~]# yum -y install java [root@linux-node1 ~]# java -version openjdk version "1.8.0_111" OpenJDK Runtime Environment (build 1.8.0_111-b15) OpenJDK 64-Bit Server VM (build 25.111-b15, mixed mode)
配置epel yum源
下载并安装EPEL
wget http://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
rpm -ivh epel-release-latest-7.noarch.rpm
下载并安装GPG key
[root@linux-node2 ~]# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
添加yum仓库
[root@linux-node1 ~]# vim /etc/yum.repos.d/elasticsearch.repo [elasticsearch-2.x] name=Elasticsearch repository for 2.x packages baseurl=http://packages.elastic.co/elasticsearch/2.x/centos gpgcheck=1 gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch enabled=1
安装elasticsearch
yum install -y elasticsearch
安装太慢直接用rpm包
root@linux-node1 ~]# rpm -ivh elasticsearch-2.4.3.rpm Preparing... ################################# [100%] Creating elasticsearch group... OK Creating elasticsearch user... OK Updating / installing... 1:elasticsearch-2.4.3-1 ################################# [100%] ### NOT starting on installation, please execute the following statements to configure elasticsearch service to start automatically using systemd sudo systemctl daemon-reload sudo systemctl enable elasticsearch.service ### You can start elasticsearch service by executing sudo systemctl start elasticsearch.service
再执行开机启动
systemctl daemon-reload
systemctl enable elasticsearch.service
启动
systemctl start elasticsearch.service
修改elasticsearch配置文件,并授权
[root@linux-node1 ~]# grep -n ‘^[a-Z]‘ /etc/elasticsearch/elasticsearch.yml 17:cluster.name: check-cluster #集群节点 23:node.name: linux-node1 #节点名字 33:path.data: /data/es-data #数据路径 37:path.logs: /var/log/elasticsearch/ #自身log 43:bootstrap.memory_lock: true #是否锁定内存 54:network.host: 0.0.0.0 #默认是所有网段 58:http.port: 9200 #端口 [root@linux-node1 ~]# mkdir -p /data/es-data [root@linux-node1 ~]# chown elasticsearch.elasticsearch /data/es-data/
启动elasticsearch
[root@linux-node1 ~]# systemctl start elasticsearch
检查
[root@linux-node1 ~]# netstat -ntpl|grep 9200 tcp6 0 0 :::9200 :::* LISTEN 2042/java
访问:
1.安装Elasticsearch集群管理插件
[root@linux-node1 ~]# /usr/share/elasticsearch/bin/plugin install mobz/elasticsearch-head -> Installing mobz/elasticsearch-head... Trying https://github.com/mobz/elasticsearch-head/archive/master.zip ... Downloading ..........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................DONE Verifying https://github.com/mobz/elasticsearch-head/archive/master.zip checksums if available ... NOTE: Unable to verify checksum for downloaded plugin (unable to find .sha1 or .md5 file to verify) Installed head into /usr/share/elasticsearch/plugins/head
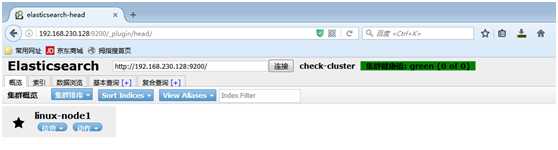
访问head集群插件:http://ES_IP:9200/_plugin/head/
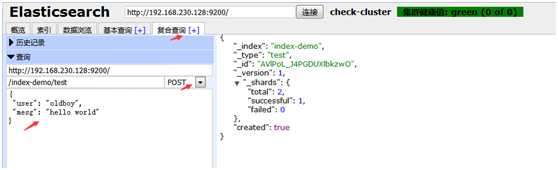
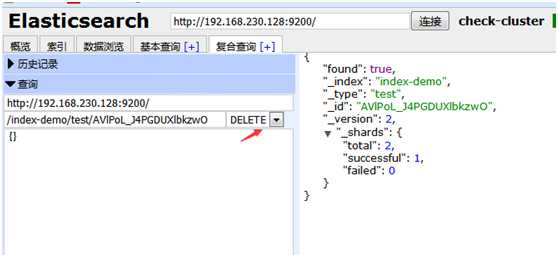
写点数据, 写一个/index-demo/test的索引,方法post,点击提交请求
{ "user": "oldboy", "mesg": "hello world" }
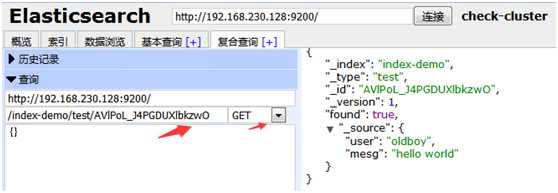
get提交id,id就是右边提示的_id信息,查询到_soure里的内容
如果删除用delete删除
部署第二台,集群部署
[root@linux-node2 /]# java -version openjdk version "1.8.0_111" OpenJDK Runtime Environment (build 1.8.0_111-b15) OpenJDK 64-Bit Server VM (build 25.111-b15, mixed mode) [root@linux-node2 /]# rz -E rz waiting to receive. [root@linux-node2 /]# rpm -ivh elasticsearch-2.4.3.rpm warning: elasticsearch-2.4.3.rpm: Header V4 RSA/SHA1 Signature, key ID d88e42b4: NOKEY Preparing... ################################# [100%] Creating elasticsearch group... OK Creating elasticsearch user... OK Updating / installing... 1:elasticsearch-2.4.3-1 ################################# [100%] ### NOT starting on installation, please execute the following statements to configure elasticsearch service to start automatically using systemd sudo systemctl daemon-reload sudo systemctl enable elasticsearch.service ### You can start elasticsearch service by executing sudo systemctl start elasticsearch.service [root@linux-node2 /]# systemctl daemon-reload [root@linux-node2 /]# systemctl enable elasticsearch.service Created symlink from /etc/systemd/system/multi-user.target.wants/elasticsearch.service to /usr/lib/systemd/system/elasticsearch.service. [root@linux-node2 /]# systemctl start elasticsearch.service [root@linux-node2 /]# netstat -ntpl|grep "9200" tcp6 0 0 127.0.0.1:9200 :::* LISTEN 2546/java tcp6 0 0 ::1:9200 :::* LISTEN 2546/java [root@linux-node2 data]# grep -n ‘^[a-Z]‘ /etc/elasticsearch/elasticsearch.yml 17:cluster.name: check-cluster 23:node.name: linux-node2 33:path.data: /data/es-data 37:path.logs: /var/log/elasticsearch/ 43:bootstrap.memory_lock: true 54:network.host: 0.0.0.0 58:http.port: 9200 [root@linux-node2 ~]# mkdir -p /data/es-data [root@linux-node2 ~]# chown elasticsearch.elasticsearch /data/es-data/
启动elasticsearch
[root@linux-node2 ~]# systemctl start elasticsearch
检查
[root@linux-node2 ~]# netstat -ntpl|grep 9200 tcp6 0 0 :::9200 :::* LISTEN 2042/java
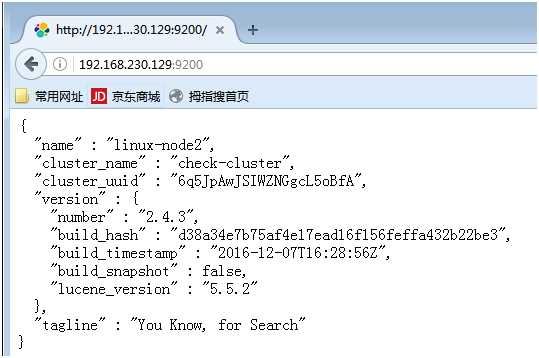
浏览器访问
查看日志,/etc/security/limits.conf,配置文件需要追加内容# allow user ‘elasticsearch‘ mlockall
下的两行
[2017-01-03 20:56:02,486][WARN ][bootstrap ] These can be adjusted by modifying /etc/security/limits.conf, for example: # allow user ‘elasticsearch‘ mlockall elasticsearch soft memlock unlimited elasticsearch hard memlock unlimited
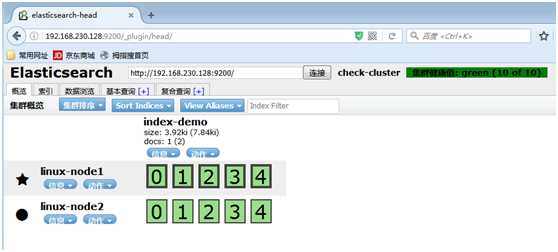
浏览器下访问,点击概览,已经有一台集群节点,要稍微等会,添加另外一台
通过组播进行通信,会通过cluster进行查找,如果无法通过组播查询,修改成单播即可,配置文件中指定,图中的有*号代表主节点
# Pass an initial list of hosts to perform discovery when new node is started: # The default list of hosts is ["127.0.0.1", "[::1]"] discovery.zen.ping.unicast.hosts: ["192.168.230.128", "192.168.230.129"]#把同一集群的节点添加到这里,方便它们互相认识
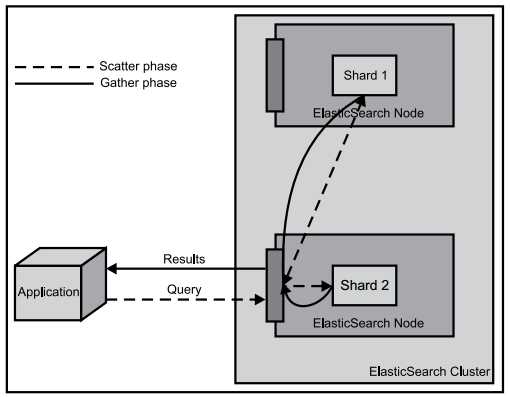
在浏览器中查看分片信息,一个索引默认被分成了5个分片,每份数据被分成了五个分片(可以调节分片数量),外围带绿色框的为主分片,不带框的为副本分片,主分片丢失,副本分片会复制一份成为主分片,起到了高可用的作用,主副分片也可以使用负载均衡加快查询速度,但是如果主副本分片都丢失,则索引就是彻底丢失。
[root@linux-node1 /]# /usr/share/elasticsearch/bin/plugin install lmenezes/elasticsearch-kopf
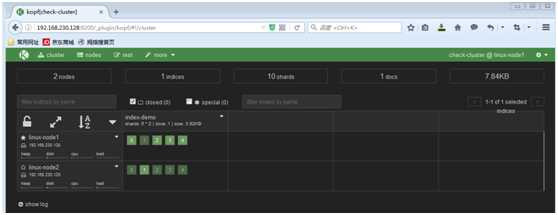
访问kopf监控插件:http://ES_IP:9200/_plugin/kopf
从下图可以看出节点的负载,cpu适应情况,java对内存的使用(heap usage),磁盘使用,启动时间
另一个监控插件bigdesk很强大,但是bigdesk目前还不支持2.1!!!安装bigdesk的方法如下
/usr/share/elasticsearch/bin/plugin install lukas-vlcek/bigdesk
当第一个节点启动,它会组播发现其他节点,发现集群名字一样的时候,就会自动加入集群。随便一个节点都是可以连接的,并不是主节点才可以连接,连接的节点起到的作用只是汇总信息展示
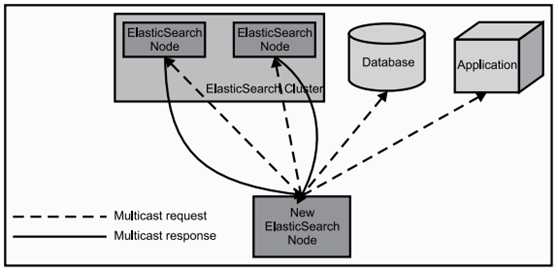
最初可以自定义设置分片的个数,分片一旦设置好,就不可以改变。主分片和副本分片都丢失,数据即丢失,无法恢复,可以将无用索引删除。有些老索引或者不常用的索引需要定期删除,否则会导致es资源剩余有限,占用磁盘大,搜索慢等。如果暂时不想删除有些索引,可以在插件中关闭索引,就不会占用内存了。
标签:请求 upd 文件 自己 执行 术语 emc started 查找
原文地址:http://www.cnblogs.com/w787815/p/6676335.html