标签:tput 节点 0.12 字符 imp 创建索引 md5 编写 storage
对于日志来说,最常见的需求就是收集、存储、查询、展示,开源社区正好有相对应的开源项目:logstash(收集)、elasticsearch(存储+搜索)、kibana(展示),我们将这三个组合起来的技术称之为ELKStack,所以说ELKStack指的是Elasticsearch、Logstash、Kibana技术栈的结合。
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
NRT
elasticsearch是一个近似实时的搜索平台,从索引文档到可搜索有些延迟,通常为1秒。
集群
集群就是一个或多个节点存储数据,其中一个节点为主节点,这个主节点是可以通过选举产生的,并提供跨节点的联合索引和搜索的功能。集群有一个唯一性标示的名字,默认是elasticsearch,集群名字很重要,每个节点是基于集群名字加入到其集群中的。因此,确保在不同环境中使用不同的集群名字。一个集群可以只有一个节点。强烈建议在配置elasticsearch时,配置成集群模式。
节点
节点就是一台单一的服务器,是集群的一部分,存储数据并参与集群的索引和搜索功能。像集群一样,节点也是通过名字来标识,默认是在节点启动时随机分配的字符名。当然啦,你可以自己定义。该名字也蛮重要的,在集群中用于识别服务器对应的节点。
节点可以通过指定集群名字来加入到集群中。默认情况下,每个节点被设置成加入到elasticsearch集群。如果启动了多个节点,假设能自动发现对方,他们将会自动组建一个名为elasticsearch的集群。
索引
索引是有几分相似属性的一系列文档的集合。如nginx日志索引、syslog索引等等。索引是由名字标识,名字必须全部小写。这个名字用来进行索引、搜索、更新和删除文档的操作。
索引相对于关系型数据库的库。
类型
在一个索引中,可以定义一个或多个类型。类型是一个逻辑类别还是分区完全取决于你。通常情况下,一个类型被定于成具有一组共同字段的文档。如ttlsa运维生成时间所有的数据存入在一个单一的名为logstash-ttlsa的索引中,同时,定义了用户数据类型,帖子数据类型和评论类型。
类型相对于关系型数据库的表。
文档
文档是信息的基本单元,可以被索引的。文档是以JSON格式表现的。
在类型中,可以根据需求存储多个文档。
虽然一个文档在物理上位于一个索引,实际上一个文档必须在一个索引内被索引和分配一个类型。
文档相对于关系型数据库的列。
分片和副本
在实际情况下,索引存储的数据可能超过单个节点的硬件限制。如一个十亿文档需1TB空间可能不适合存储在单个节点的磁盘上,或者从单个节点搜索请求太慢了。为了解决这个问题,elasticsearch提供将索引分成多个分片的功能。当在创建索引时,可以定义想要分片的数量。每一个分片就是一个全功能的独立的索引,可以位于集群中任何节点上。
分片的两个最主要原因:
a、水平分割扩展,增大存储量
b、分布式并行跨分片操作,提高性能和吞吐量
分布式分片的机制和搜索请求的文档如何汇总完全是有elasticsearch控制的,这些对用户而言是透明的。
网络问题等等其它问题可以在任何时候不期而至,为了健壮性,强烈建议要有一个故障切换机制,无论何种故障以防止分片或者节点不可用。为此,elasticsearch让我们将索引分片复制一份或多份,称之为分片副本或副本。
副本也有两个最主要原因:
总之,每一个索引可以被分成多个分片。索引也可以有0个或多个副本。复制后,每个索引都有主分片(母分片)和复制分片(复制于母分片)。分片和副本数量可以在每个索引被创建时定义。索引创建后,可以在任何时候动态的更改副本数量,但是,不能改变分片数。
默认情况下,elasticsearch为每个索引分片5个主分片和1个副本,这就意味着集群至少需要2个节点。索引将会有5个主分片和5个副本(1个完整副本),每个索引总共有10个分片。
每个elasticsearch分片是一个Lucene索引。一个单个Lucene索引有最大的文档数LUCENE-5843, 文档数限制为2147483519(MAX_VALUE – 128)。 可通过_cat/shards来监控分片大小。
LogStash由JRuby语言编写,基于消息(message-based)的简单架构,并运行在Java虚拟机(JVM)上。不同于分离的代理端(agent)或主机端(server),LogStash可配置单一的代理端(agent)与其它开源软件结合,以实现不同的功能。
正是由于以上组件在LogStash架构中可独立部署,才提供了更好的集群扩展性。
Logstash是一个完全开源的工具,他可以对你的日志进行收集、分析,并将其存储供以后使用(如,搜索),您可以使用它。说到搜索,logstash带有一个web界面,搜索和展示所有日志。
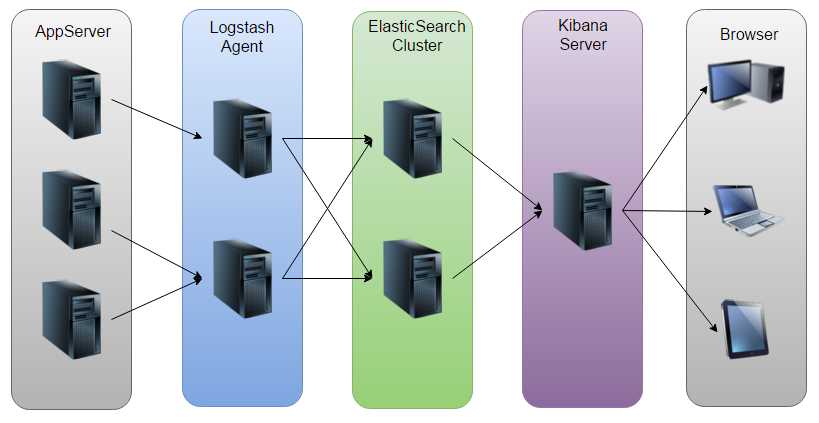
如图:Logstash收集AppServer产生的Log,并存放到ElasticSearch集群中,而Kibana则从ES集群中查询数据生成图表,再返回给Browser。
[root@server elasticsearch]# cat /etc/redhat-release
CentOS release 6.6 (Final)
[root@server elasticsearch]# uname -r
2.6.32-504.el6.x86_64
配置表:
|
主机名 |
IP |
安装软件 |
|
server.nulige.com |
192.168.30.129/24 |
Elasticsearch(存储+搜索)、Kibana(展示) |
|
node1.nulige.com |
192.168.30.130/24 |
Logstash(收集) |
备注:另外可以增添服务器组,集群。
Elasticsearch需要Java环境,可以直接使用yum安装。也可以从Oracle官网下载JDK进行安装。开始之前要确保JDK正常安装并且环境变量也配置正确。
[root@m01 ~]# yum install -y java [root@m01 ~]# java -version openjdk version "1.8.0_121" OpenJDK Runtime Environment (build 1.8.0_121-b13) OpenJDK 64-Bit Server VM (build 25.121-b13, mixed mode)
1、下载并安装GPG key
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
2、添加yum源 (或者直接从官网下载rpm包上传到服务器上面安装)
a、添加elasticsearch.repo
cat >/etc/yum.repos.d/elasticsearch.repo<<EOF [elasticsearch-2.x] name=Elasticsearch repository for 2.x packages baseurl=http://packages.elastic.co/elasticsearch/2.x/centos gpgcheck=1 gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch enabled=1 EOF
b、添加kibana.repo
cat >/etc/yum.repos.d/kibana.repo<<EOF [kibana-4.5] name=Kibana repository for 4.5.x packages baseurl=http://packages.elastic.co/kibana/4.5/centos gpgcheck=1 gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch enabled=1 EOF
3、安装elasticsearch 和 kibana
[root@m01 ~]# yum install -y elasticsearch [root@m01 ~]# yum install -y kibana
4、 修改 limits.conf
#在结尾添加如下两行代码 [root@server elasticsearch]#vi /etc/security/limits.conf elasticsearch soft memlock unlimited elasticsearch hard memlock unlimited #检查 [root@server elasticsearch]# tail -2 /etc/security/limits.conf elasticsearch soft memlock unlimited elasticsearch hard memlock unlimited
5、创建目录并授权
[root@m01 ~]# mkdir -p /data/es-data [root@m01 ~]# chown -R elasticsearch.elasticsearch /data/es-data/
6、配置Elasticsearch
cat >/etc/elasticsearch/elasticsearch.yml<<EOF cluster.name: elk-cluter node.name: server.nulige.com path.data: /data/es-data path.logs: /var/log/elasticsearch/ bootstrap.mlockall: true network.host: server.nulige.com http.port: 9200 EOF
#检查配置文件
[root@m01 ~]# grep ‘^[a-z]‘ /etc/elasticsearch/elasticsearch.yml cluster.name: elk-cluter # 集群的名称,判别节点是否是统计集群 node.name: server.nulige.com # 节点的名称 path.data: /data/es-data # 数据存放路径 path.logs: /var/log/elasticsearch/ # 日志路径 bootstrap.mlockall: true # 锁住内存,使内存不会在swap中使用 network.host:server.nulige.com # 允许访问的IP或域名 http.port: 9200 # 端口
备注:如果是用域名,请先做域名解析,否则无法访问成功。(不要用内网IP,无法访问成功,除非你用VPN)
#windows系统,在hosts文件里,配置域名解析 192.168.30.129 server.nulige.com
浏览器访问:
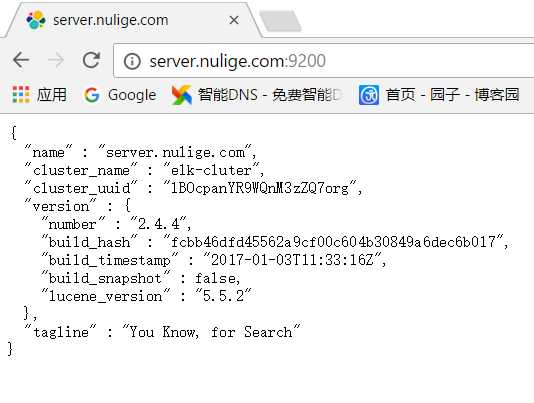
在线安装(若无法下载,请使用离线安装方法):
[root@m01 ~]# /usr/share/elasticsearch/bin/plugin install mobz/elasticsearch-head
[root@m01 ~]# wget https://github.com/mobz/elasticsearch-head/archive/master.zip
[root@m01 ~]# /usr/share/elasticsearch/bin/plugin install file:/root/master.zip
-> Installing from file:/root/master.zip...
Trying file:/root/master.zip ...
Downloading .........DONE
Verifying file:/root/master.zip checksums if available ...
NOTE: Unable to verify checksum for downloaded plugin (unable to find .sha1 or .md5 file to verify)
Installed head into /usr/share/elasticsearch/plugins/head
插件安装帮助信息:
[root@m01 ~]# /usr/share/elasticsearch/bin/plugin install -h
NAME
install - Install a plugin
SYNOPSIS
plugin install <name or url>
DESCRIPTION
This command installs an elasticsearch plugin. It can be used as follows:
Officially supported or commercial plugins require just the plugin name:
plugin install analysis-icu
plugin install shield
Plugins from GitHub require ‘username/repository‘ or ‘username/repository/version‘:
plugin install lmenezes/elasticsearch-kopf
plugin install lmenezes/elasticsearch-kopf/1.5.7
Plugins from Maven Central or Sonatype require ‘groupId/artifactId/version‘:
plugin install org.elasticsearch/elasticsearch-mapper-attachments/2.6.0
Plugins can be installed from a custom URL or file location as follows:
plugin install http://some.domain.name//my-plugin-1.0.0.zip
plugin install file:/path/to/my-plugin-1.0.0.zip
OFFICIAL PLUGINS
The following plugins are officially supported and can be installed by just referring to their name
- analysis-icu
- analysis-kuromoji
- analysis-phonetic
- analysis-smartcn
- analysis-stempel
- cloud-aws
- cloud-azure
- cloud-gce
- delete-by-query
- discovery-multicast
- lang-javascript
- lang-python
- mapper-attachments
- mapper-murmur3
- mapper-size
OPTIONS
-t,--timeout Timeout until the plugin download is abort
-v,--verbose Verbose output
-h,--help Shows this message
-b,--batch Enable batch mode explicitly, automatic confirmation of security permissions
http://172.16.1.61:9200/_plugin/head/
[root@m01 ~]# /usr/share/elasticsearch/bin/plugin install lmenezes/elasticsearch-kopf
-> Installing lmenezes/elasticsearch-kopf...
Trying https://github.com/lmenezes/elasticsearch-kopf/archive/master.zip ...
Downloading ......................................................................................................................................................................................................DONE
Verifying https://github.com/lmenezes/elasticsearch-kopf/archive/master.zip checksums if available ...
NOTE: Unable to verify checksum for downloaded plugin (unable to find .sha1 or .md5 file to verify)
Installed kopf into /usr/share/elasticsearch/plugins/kopf
在线无法安装?使用离线安装:
[root@m01 ~]# /usr/share/elasticsearch/bin/plugin install file:/root/elasticsearch-kopf-master.zip
-> Installing from file:/root/elasticsearch-kopf-master.zip...
Trying file:/root/elasticsearch-kopf-master.zip ...
Downloading ......................DONE
Verifying file:/root/elasticsearch-kopf-master.zip checksums if available ...
NOTE: Unable to verify checksum for downloaded plugin (unable to find .sha1 or .md5 file to verify)
Installed kopf into /usr/share/elasticsearch/plugins/kopf
实例2-1 浏览器实例:
如果要配置集群,另外配置集群名相同的节点,通过组播进行通信,会通过cluster进行查找,如果无法通过组播查询,修改成单播即可。
配置文件参考如下:
## grep "^[a-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: elk-cluter
node.name: 22222
path.data: /data/es-data
path.logs: /var/log/elasticsearch/
bootstrap.mlockall: true
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.90.201","192.168.90.202"] #单播(配置一台即可,生产可以使用组播方式)
### 修改配置文件之后,启动服务,可在m01集群管理插件页面查到相关信息。
和Elasticsearch一样,在开始部署LogStash之前也需要你的环境中正确的安装的JDK。可以下载安装Oracle的JDK或者使用 yum安装openjdk。
yum install -y java
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
cat >/etc/yum.repos.d/logstash.repo<<EOF
[logstash-2.3]
name=Logstash repository for 2.3.x packages
baseurl=https://packages.elastic.co/logstash/2.3/centos
gpgcheck=1
gpgkey=https://packages.elastic.co/GPG-KEY-elasticsearch
enabled=1
EOF
yum install -y logstash
启动一个logstash,-e:在命令行执行;input输入,stdin标准输入,是一个插件;output输出,stdout:标准输出
[root@web01 ~]# /opt/logstash/bin/logstash -e ‘input { stdin {} } output { stdout{codec => rubydebug} }‘
Settings: Default pipeline workers: 1
Pipeline main started
what?
{
"message" => "what?",
"@version" => "1",
"@timestamp" => "2016-10-24T11:11:13.606Z",
"host" => "web01"
}
使用rubydebug显示详细输出,codec为一种编码器
使用logstash讲信息写入到Elasticsearch:
[root@web01 ~]# /opt/logstash/bin/logstash -e ‘input { stdin{} } output { elasticsearch { hosts => ["172.16.1.61:9200"] } }‘
Settings: Default pipeline workers: 1
Pipeline main started
yjj
elastic
每一条输出的内容称为一个事件,多个相同的输出的内容合并到一起称为一个事件
修改nginx日志格式为json
log_format json ‘{ "@timestamp": "$time_local", ‘
‘"@fields": { ‘
‘"remote_addr": "$remote_addr", ‘
‘"remote_user": "$remote_user", ‘
‘"body_bytes_sent": "$body_bytes_sent", ‘
‘"request_time": "$request_time", ‘
‘"status": "$status", ‘
‘"request": "$request", ‘
‘"request_method": "$request_method", ‘
‘"http_referrer": "$http_referer", ‘
‘"body_bytes_sent":"$body_bytes_sent", ‘
‘"http_x_forwarded_for": "$http_x_forwarded_for", ‘
‘"http_user_agent": "$http_user_agent" } }‘;
yum install kibana -y
[root@m01 ~]# egrep -v "^$|#" /opt/kibana/config/kibana.yml
server.port: 5170
server.host: "0.0.0.0"
elasticsearch.url: "http://172.16.1.61:9200"
kibana.index: ".kibana"
[root@m01 ~]# /etc/init.d/kibana start
网页配置:index name
[access_nginx-]YYYY.MM.DD
yum install -y java
yum install -y elasticsearch
grep -qc "elasticsearch soft memlock unlimited" /etc/security/limits.conf||echo "elasticsearch soft memlock unlimited" >>/etc/security/limits.conf
nlimited" >>/etc/security/limits.conf
grep -qc "elasticsearch hard memlock unlho "elasticsearch hard memlock unlimited" >>/etc/security/limits.conf
管理linux-node2的elasticsearch
将节点1 的配置文件拷贝到node2中,修改配置文件并授权
配置文件中cluster.name的名字一定要一致,当集群内节点启动的时候,默认使用组播(多播),寻找集群中的节点,如果没有搜索到,改成单播即可
mkdir -p /data/es-data
chown -R elasticsearch.elasticsearch /data/es-data/
cat >/etc/elasticsearch/elasticsearch.yml<<-EOF
cluster.name: elk-cluter
node.name: elk-node2
path.data: /data/es-data
path.logs: /var/log/elasticsearch/
bootstrap.mlockall: true
network.host: 172.16.1.7
http.port: 9200
discovery.zen.ping.unicast.hosts: ["172.16.1.7", "172.16.1.61"] ### 单播
EOF
[root@elk-node2 ~]# grep ‘^[a-z]‘ /etc/elasticsearch/elasticsearch.yml
cluster.name: elk-cluter
node.name: elk-node2
path.data: /data/es-data
path.logs: /var/log/elasticsearch/
bootstrap.mlockall: true
network.host: 172.16.1.7
http.port: 9200
discovery.zen.ping.unicast.hosts: ["172.16.1.7", "172.16.1.61"]
[root@elk-node2 ~]# /etc/init.d/elasticsearch restart
在浏览器中查看分片信息,一个索引默认被分成了5个分片,每份数据被分成了五个分片(可以调节分片数量),下图中外围带绿色框的为主分片,不带框的为副本分片,主分片丢失,副本分片会复制一份成为主分片,起到了高可用的作用,主副分片也可以使用负载均衡加快查询速度,但是如果主副本分片都丢失,则索引就是彻底丢失。
标签:tput 节点 0.12 字符 imp 创建索引 md5 编写 storage
原文地址:http://www.cnblogs.com/nulige/p/6680336.html