标签:技术分享 未来 并行 经验 target images 基于 模型 调整
人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。
人工智能是对人的意识、思维的信息过程的模拟。人工智能不是人的智能,但能像人那样思考、也可能超过人的智能。
根据等人事件中判断人是否迟到了解什么是机器学习,具体参见地址:http://www.cnblogs.com/hellochennan/p/5423740.html
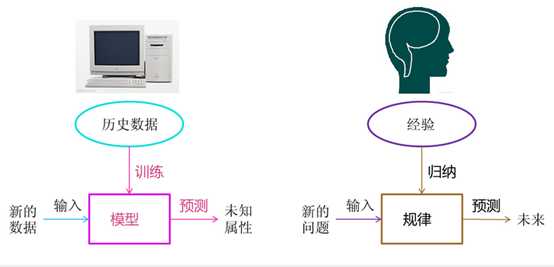
机器学习方法是计算机利用已有的数据(经验),得出了某种模型(迟到的规律),并利用此模型预测未来(是否迟到)的一种方法。
机器学习与人类思考的经验过程是类似的,不过它能考虑更多的情况,执行更加复杂的计算。事实上,机器学习的一个主要目的就是把人类思考归纳经验的过程转化为计算机通过对数据的处理计算得出模型的过程。经过计算机得出的模型能够以近似于人的方式解决很多灵活复杂的问题。
从广义上来说,机器学习是一种能够赋予机器学习的能力以此让它完成直接编程无法完成的功能的方法。但从实践的意义上来说,机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。
机器学习的过程与人类对历史经验归纳的过程做个比对。
其实,机器学习跟模式识别,统计学习,数据挖掘,计算机视觉,语音识别,自然语言处理等领域有着很深的联系。
从范围上来说,机器学习跟模式识别,统计学习,数据挖掘是类似的,同时,机器学习与其他领域的处理技术的结合,形成了计算机视觉、语音识别、自然语言处理等交叉学科。因此,一般说数据挖掘时,可以等同于说机器学习。同时,我们平常所说的机器学习应用,应该是通用的,不仅仅局限在结构化数据,还有图像,音频等应用。

1.模式识别=机器学习。两者的主要区别在于前者是从工业界发展起来的概念,后者则主要源自计算机学科。
2.数据挖掘=机器学习+数据库。
3.统计学习近似等于机器学习。统计学习是个与机器学习高度重叠的学科。因为机器学习中的大多数方法来自统计学,甚至可以认为,统计学的发展促进机器学习的繁荣昌盛。
4.计算机视觉=图像处理+机器学习。图像处理技术用于将图像处理为适合进入机器学习模型中的输入,机器学习则负责从图像中识别出相关的模式。
5.语音识别=语音处理+机器学习。语音识别就是音频处理技术与机器学习的结合。
6.自然语言处理=文本处理+机器学习。自然语言处理技术主要是让机器理解人类的语言的一门领域。在自然语言处理技术中,大量使用了编译原理相关的技术,例如词法分析,语法分析等等,除此之外,在理解这个层面,则使用了语义理解,机器学习等技术。
其主要的有:1.监督学习算法:线性回归、逻辑回归、神经网络、SVM;
2.无监督学习算法:聚类算法、降维算法;
3.特殊算法:推荐算法(既不属于监督学习,也不属于无监督学习)。
下面就神经网络和SVM进行对比:
SVM是最优秀、准确而健壮的算法之一,维度不敏感,可处理线性可分和线性不可分数据。分为SVC和SVR。
优势:分类性能好、稳定性高、算法更新快。
一般选择RBF作为核函数。
SVM分类决策中起决定作用的是支持向量。
关键优化参数:
C:惩罚系数,值越高,惩罚程度越大,误差容忍力越差。
Gamma:影响每个支持向量对应的高斯的作用范围,值越大,泛化性能越差。
限制:
计算的复杂性取决于支持向量的数目,大规模训练样本难以实现。
用SVM解决多分类问题存在困难。
神经网络是进行分布式并行信息处理的算法模型,依靠系统的复杂程度,通过调整内部大量节点之间相互相互连接的关系,达到处理信息的目的。
使用范围:只能预测二项式数据,数值型数据。
过程:复杂,输入层->隐藏层->输出层
参数:训练周期、学习速率、动量、衰减。
二者对比:二者都是“二标签”分类任务
神经网络:“黑匣子”,基于经验风险最小化,易陷入局部最优,适合大样本。
SVM:理论基础扎实,基于结构风险最小化,泛化能力较好,具有全局最优性,适合小样本。
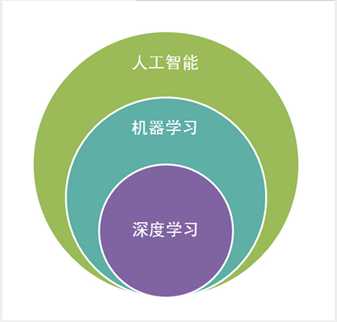
人工智能是机器学习的父类。深度学习则是机器学习的子类。如果把三者的关系用图来表明的话,则是下图:
标签:技术分享 未来 并行 经验 target images 基于 模型 调整
原文地址:http://www.cnblogs.com/ggYYa/p/6688728.html