标签:bst log 证明 boosting 判断 tin 自己 alt with

论文提出了一种loss:
![]()
x是原始数据,y是对应的label,h(x)是一个判别函数,r(x)相当于训练了一个信心函数,r(x)越大,代表对自己做的判断的信息越大,当r(x)<0的时候,就拒绝进行分类。那么这个loss函数分为前后两项,前面一项就是通常的分类错误的loss,后面一样是对不进行分类的惩罚,c(x)是进行惩罚的权重,作者设置为常数0.5。
作者指出,基于置信度的方法是这种方法的特例,也就是另r(x) = |h(x)|-gama。
评价:这个方法就是对决策边界的点不进行分类,因为这些点可能很混杂,本来就不好分类,那么干脆给个0.5的分错概率,避免分界面的来回震荡。
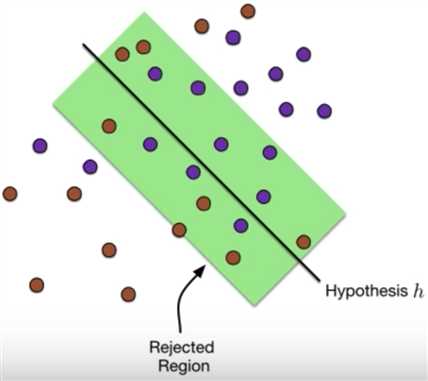
作者在论文中对他们的方法做了详细的证明,还没有看,待研究。
标签:bst log 证明 boosting 判断 tin 自己 alt with
原文地址:http://www.cnblogs.com/huangshiyu13/p/6690788.html