标签:style blog http os 使用 io strong for 数据
从互联网上寻找有用的信息越来越难,这催生了三类方法:信息检索、信息过滤和推荐系统。信息检索是指Google、百度这样的搜索引擎,这是一种被动的方式;信息过滤是指先对信息进行分类,再根据用户的偏好进行过滤,比如我们注册知乎/豆瓣/微博等时都会要求选择感兴趣的领域,之后会对我们选定领域的内容进行推送;推荐系统根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的信息和商品,推荐方法有基于内容的推荐、基于模型的推荐、关联规则以及协同过滤等等。
协同过滤算法的两个假设:
1. 用户一般会喜欢与自己相似的其他用户喜欢的物品
2. 用户一般会喜欢与自己喜欢物品相似的物品
基于用户的协同过滤的核心思想是把推荐分两步:
第一步,找到和你品位喜好相似的人;
第二步,把他们的喜欢的东西整理成排序列表推荐给你
Inputs:
l user-item matrix #M X N
l similarity="Euclidean_distance", "Cosine", "Pearson", "Adjust_cosine" #相似性计算方式
l K or threshold #fix-size neighborhoods or threshold neighborhoods,或者使用优化算法自动选择
l type="predict" or "recommend" # 预测评分还是推荐商品
l top-n #推荐top-n商品
l UID #需要做推荐的用户ID
Outputs:
l type="recommend", 为用户UID推荐的top-n个商品
l type="predict", 用户UID对 item的评分预测
Setp1:Calculate similarity( i , UID )
这里只计算特定用户UID和其他M-1个用户的相似性;也可以先计算M个用户之间的相似性—>MXM相似性矩阵,然后取UID那一行。
此处计算相似性分两种:
计算用户i和UID在all_items集合上的相似性
计算用户i和UID在共同评分过的items集合上的相似性(user-item不能是0-1矩阵,多用在评分预测中)
output1 : 此步得到的是一个vector or list(1 X M-1)
Step2:K-nearest-neighborhoods
l fixed K:降序排列,取前K个uid
l threshold:取similarity大于等于threshold的uid
注:K和threshold的选择可使用Cross-Validation优化
output2 : 这一步我们得到一个verctor( 1 X F )
Step3:Predict or Recommend
上一步我们得到和当前用户UID最相似的K个用户,这K个用户历史购买记录我们记为KNNSet_i(i=1,2,...,K)。
type="Recommend"
推荐主要针对user_item是0-1矩阵的情况,就是把邻居喜欢并且当前用户没有购买的物品推荐给用户。这里实现起来有两种方法,
第一种较简单,不考相似度,想法是这样的:把K个最近邻最经常购买过的物品推荐给当前用户。具体这样操作:
从原始User-Item matrix中提取KNNSet_i得到KNN-User-Item matrix(K X N)—>按列求和得到N个item的购买频率FV(1 X N)—>剔除当前用户已经购买的item—>按频率降序排列,取前n个item做推荐;
第二种思路上和第一种一致,只不过购买频率的计算考虑相似度,即加权的购买频率。在按列求和之前,需要在KNN-User-Item matrix的每一行乘以相应的相似度,其余步骤相同。
Type=”predict”
预测针对user_item是评分的情况,预测当前用户对某一个物品(电影\音乐\文章)的评分,思路依然是计算加权平均分。
(得到预测评分之后可以再进一步,对p(uid,i)降序排列,取前n个做推荐,这时候type=‘recommend‘)
基于物品的协同过滤算法的核心思想也是把推荐分两步:
第一步,找到和你历史购买物品相似的物品
第二步,把这些物品整理成排序列表推荐给你
Step1 : calculate similarity ( I1 , I2 )
For each item in product catalog, I1
For each customer C who purchased I1
For each item I2 purchased bycustomer C
Record that a customer purchased I1 and I2
For each item I2
Compute the similarity between I1 and I2
所有的用户都参与计算,而不仅仅是I1,I2都购买过的那些用户(在此情况下,这么计算没意义)。
Step2 : recommend
假设用户UID最近购买了商品I—>利用item-item-similarity矩阵找出商品I最相似的K个商品—>剔除已购买的—>取前n个推荐
Step1 : calculate similarity ( i , j )
这里计算相似度有所不同,只利用对item_i,item_j共同评价过的用户计算相似度。
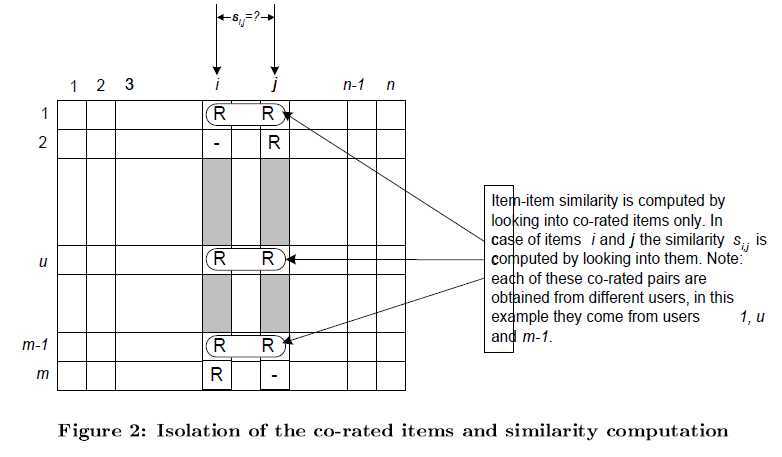
这一步得到N X N的item-item-similarity矩阵
Step2 : predict
?????
核心思想:用函数f(x)=x+b代替加权分,The free parameter b is then simply the average difference between the two items ratings.
HOW:
l 找出( item_T, item_i )之间的评分均差bi和共同评分的用户数ni
l
2. 时间权重
核心思想:传统协同过滤算法没有考虑用户兴趣变化的问题,当用户兴趣发生变化时将导致它的推荐质量较差。
HOW:
l 设计时间权重函数f(t)
l 用f(t)赋予每个评分一个时间权重
l 利用时间加权后的评分计算相似性,其他相同
3. 热门物品
核心思想:越是冷门的物品有同样的行为,就越能说明用户间的相似性,在计算用户相似性的时候需要降低热门物品的影响。
HOW:设计流行度权重1/N(i)。
4. 基于高分纪录
核心思想:推荐算法的目的多数情况下是为用户推荐他们最感兴趣的项,尝试找到在用户最感兴趣的领域中最相似的其他用户。
HOW:在相似性计算中只考虑那些高评价的记录,比如高于用户rating平均分的记录
数据挖掘算法修炼--协同过滤Collaborative Filtering
标签:style blog http os 使用 io strong for 数据
原文地址:http://www.cnblogs.com/SmallData/p/3932097.html