标签:use 不能 网站服务器 键值 信息采集 按钮 jruby alt 值类型
收集和分析日志是应用开发中至关重要的一环,互联网大规模、分布式的特性决定了日志的源头越来越分散,
产生的速度越来越快,传统的手段和工具显得日益力不从心。在规模化场景下,grep、awk 无法快速发挥作用,我们需要一种高效、灵活的日志分析方式,可以给故障处理,问题定位提供更好的支持。基于全文搜索引擎 Lucene 构建的 ELKstack 平台,是目前比较流行的日志收集方解决方案。
ELK系统的部署按照官方文档操作即可,相关资料也很多,这篇文章更多的关注三个组件的设计和实现,帮助大家了解这个流行的日志收集系统,
结合Logstash,ElasticSearch和Kibana三个组件,可以搭建一套高效的日志收集和分析系统。
ELK stack支持组件间的灵活组合,提供强大的开箱即用的日志收集和检索功能。
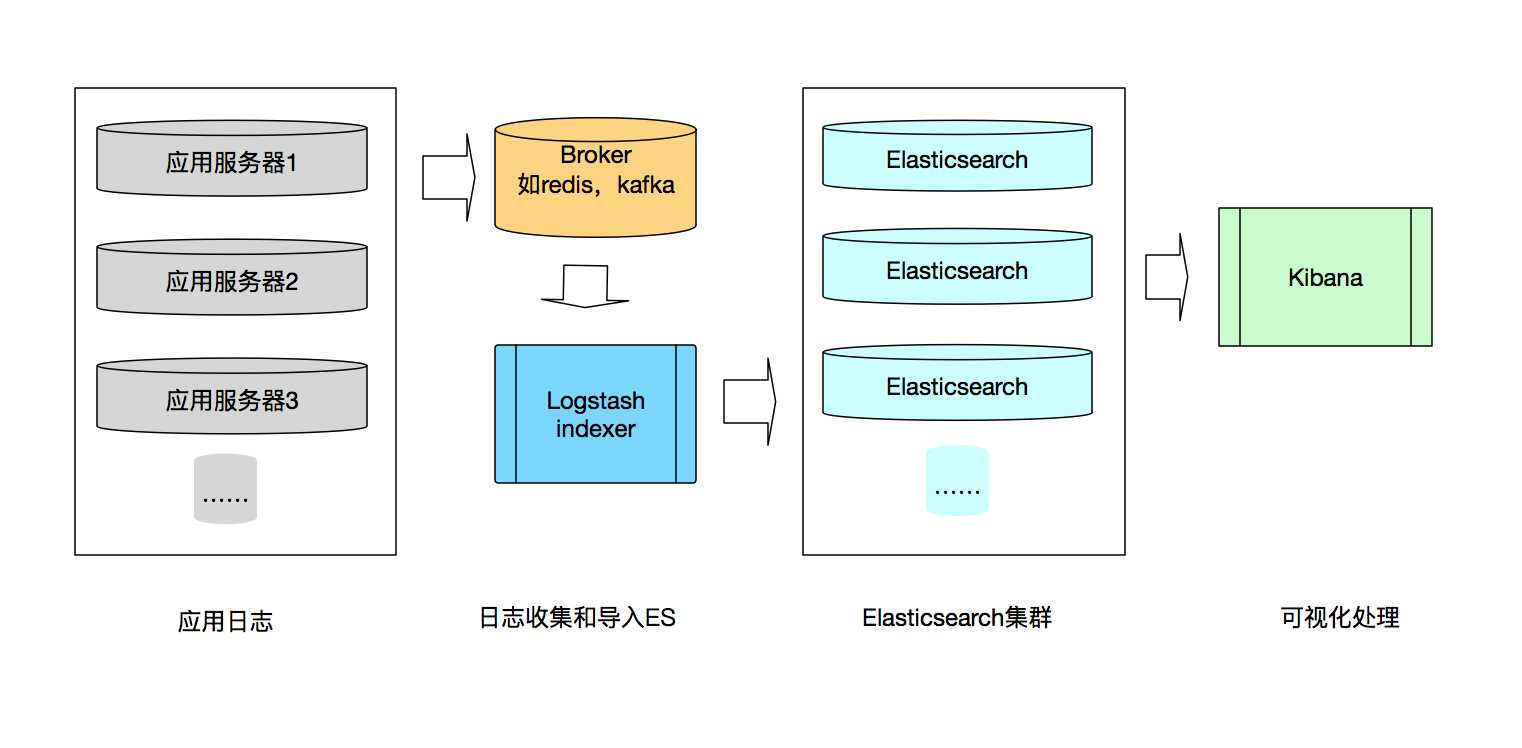
可以看到ELK系统进行日志收集的过程可以分为三个环节:
Logstash可以结合Redis或者kafka等收集应用服务器产生的日志,经过简单的过滤等操作后发送到ElasticSearch,ElasticSearch进行相关的索引处理,最后在Kibana进行相关的可视化操作。
Logstash 是一种功能强大的信息采集工具,类似于同样用于日志收集的 Flume。
Logstash通过配置文件规定 Logstash 如何处理各种类型的事件流,一般包含 input、filter、output 三个部分。
Logstash 为各个部分提供相应的插件,通过 input、filter、output 三类插件完成各种处理和转换,
另外 codec 类的插件可以放在 input 和 output 部分通过简单编码来简化处理过程。
Logstash使用Jruby语言编写,对于使用者来讲,Logstash本身是基于命令行界面,面向任务处理的。
Logstash的软件架构是一种带有“管道-过滤器”风格的插件式架构,作为一个开源软件,Logstash遵循Apache 2.0进行开源,第三方社区为其贡献了大量插件。
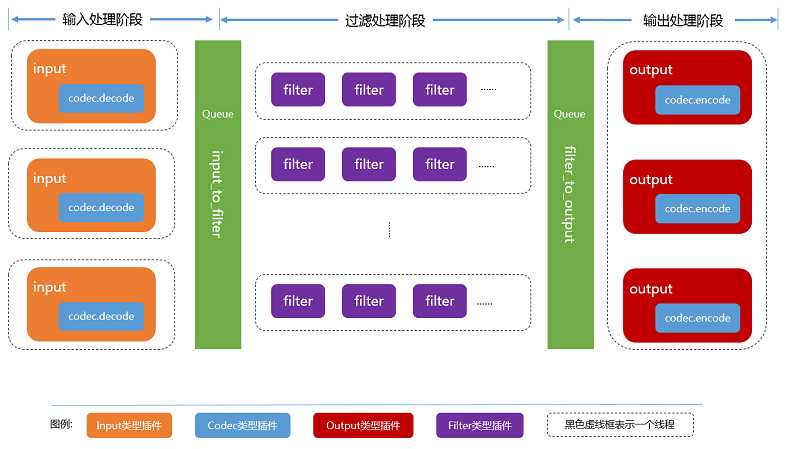
这张数据流图来自官方社区,可以看到Logstash的运行时数据处理会经历三个阶段:
输入阶段 接受不同来源的数据流入,可以配置codec插件进行简单的处理。
过滤阶段 对流入数据进行过滤等操作,传递给output,其中“输入”与“输出”是必须有的,“过滤”阶段是可选的。
输出阶段 将数据传递到消息队列,文件系统等进行进一步处理,在ELK的日志系统中,输出到ElasticSearch索引中。
三个阶段的处理任务是异步的,不存在跨阶段任务执行与同一个线程中的情况。
Logstash可以通过指定配置文件直接启动,下面是一份典型的配置示例:
# 读取access.log日志并输出到控制台
input { filex { path => ["/Users/bingyue/Work/workspace/access.log"] } } output { stdout { } }
ElasticSearch是一个开源搜索服务器项目,2010年2月发布至今,该项目已发展成为搜索和数据分析解决方案领域的主要一员。ES的实现和应用包括非常多的内容,这里我们只简单了解,从整体架构入手,做到对ES有一个初步的认识。
ElasticSearch基于Apache Lucene实现,Lucene是一个成熟的、高性能并且可扩展的搜索引擎包, ElasticSearch在Lucene之上封装了索引,查询,以及分布式相关的接口。
节点是集群中的一个 Elasticearch 实例。 集群是一组拥有共同的 cluster name 的节点。其中一个节点就是一个 ES 进程,多个节点组成一个集群。一般每个节点都运行在不同的操作系统上,配置好集群相关参数后 ES 会自动组成集群。集群内部通过 ES 的选主算法选出主节点,而集群外部则是可以通过任何节点进行操作,无主从节点之分,对外表现对等,去中心化,有利于客户端编程。
索引在ES中索引有两层含义, 作为动词,它指的是把一个文档保存到 ES 中的过程,索引一个文档后,我们就可以使用 ES 搜索到这个文档; 作为名词,它是指保存文档的地方,相当于关系数据库中的database概念,一个集群中可以包含多个索引。
ES 是一个分布式系统,它保存索引时会选择适合的“主分片”(Primary Shard),把索引保存到其中(我们可以把分片理解为一块物理存储区域)。分片的分法是固定的,而且是安装时候就必须要决定好的(默认是 5),后面就不能改变了。
既然有主分片,那肯定是有“从”分片的,在 ES 里称之为“副本分片”(Replica Shard)。副本分片主要有两个作用: 高可用:某分片节点挂了的话可走其他副本分片节点,节点恢复后上面的分片数据可通过其他节点恢复 负载均衡:ES 会自动根据负载情况控制搜索路由,副本分片可以将负载均摊
ES支持RESTful访问,并且 ES 的 HTTP 接口不只是可以进行业务操作(索引/搜索),还可以进行一些配置等。
下面介绍几个很常用的接口:
/_cat/nodes?v:查集群状态 /_cat/shards?v:查看分片状态 /${index}/${type}/_search:搜索
我们也可以直接在所有索引所有类型上进行搜索:/_search。
除了上面这些,ES官方社区还给出了一些关键术语解释:
一个文档就是一个保存在 es 中的 JSON 文本,可以把它理解为关系型数据库表中的一行。每个文档都是保存在索引中的,拥有一种类型和 id。一个文档是一个 JSON 对象(一些语言中的 hash / hashmap / associative array)包含了 0 或多个字段(键值对)。原始的 JSON 文本在索引后将被保存在 _source 字段里,搜索完成后返回值中默认是包含该字段的。
Id 是用于标识文档的,一个文档的索引/类型/id 必须是唯一的。文档 id 是自动生成的(如果不指定)。
一个文档包含了若干字段,或称之为键值对。字段的值可以是简单(标量)值(例如字符串、整型、日期),也可以是嵌套结构,例如数组或对象。一个字段类似于关系型数据库表中的一列。每个字段的映射都有一个字段类型(不要和文档类型搞混了),它描述了这个字段可以保存的值类型,例如整型、字符串、对象。映射还可以让我们定义一个字段的值如何进行分析。
一个映射类似于关系型数据库中的模式定义。每个索引都存在一个映射,它定义了该索引中的每一种类型,以及索引相关的配置。映射可以显示定义,或者在文档被索引时自动创建。
ElasticSearch的应用场景主要发挥其强大的全文搜索功能,因为良好的分布式支持,一些公司也会使用ES作为文档型数据库,类似MongoDB等的应用。
Kibana应用在ElasticSearch之上,提供可视化的数据查询和分析等功能, 主要的版本有Kibana 3和Kibana 4,两者在设计上区别较大,这里主要介绍k4的应用。
要使用Kibana,就得告诉它想要探索的 Elasticsearch 索引是那些,需要配置一个或者多个索引模式。 默认情况下,Kibana 认为你要访问的是通过 Logstash 导入 Elasticsearch 的数据,这时候使用默认的 logstash-* 作为index pattern。 Kibana 数据展示需要一个包含了时间戳的索引字段,用来做基于时间的处理,如果是由logstash导入的日志,使用默认的@timestamp即可。
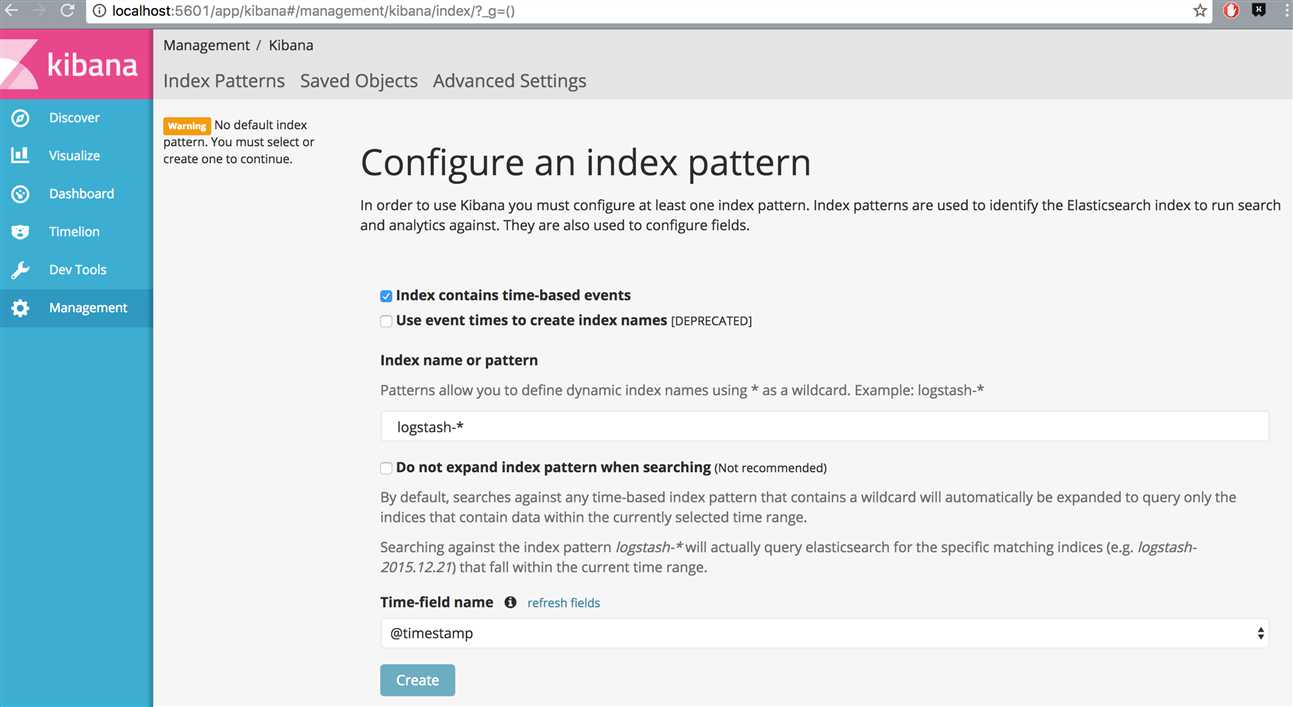
连接到Elasticsearch以后,就可以使用kibana进行数据的分析。
kibana的面板支持以下的功能:
Discover 标签页用于交互式探索数据。可以访问到匹配得上选择的索引模式的每个索引的每条记录。可以提交搜索请求,过滤搜索结果,然后查看文档数 据。还可以看到匹配搜索请求的文档总数,获取字段值的统计情况。如果索引模 式配置了时间字段,文档的时序分布情况会在页面顶部以柱状图的形式展示出来。
kibana支持Lucene格式的检索方式。包括:
比如,如果在搜索网站服务器日志,可以输入exception来搜索各字段中的exception单词。
搜索特定字段中的值,则在值前加上字段名。比如,可以输入 status:200 来限制搜索,要搜索一个值的范围,可以用范围查询语法,
要指定更复杂的搜索标准,可以用布尔操作符AND, OR和 NOT 。
Visualize 标签页用来设计可视化。 支持各种图表进行展示。
数据源可以选择新建或者读取一个已保存的搜索。搜索是和一个或者一系列索引相关联的。如果选择了在一个配置了多个索引的系统上开始新搜索,从可视化编辑器的下拉菜单里选择一个索引模式。
Kibana dashboard 能支持自由排列一组已保存的视图。然后可以保存这个仪表板,用来分享或者重载。
(1)创建新的仪表盘
第一次点击 Dashboard 标签的时候,Kibana 会显示一个空白的仪表板。 通过添加可视化的方式来构建仪表板。
要添加视图到仪表板上,点击工具栏面板上的 Add。从列表中选择一个已保存的视图。可以在 Visualization Filter 里输入字符串来过滤想要找的视图。 你选择的这个视图会出现在仪表板上的一个容器(container)里。
(2)修改仪表盘信息
仪表板里的可视化都存在可以调整大小的容器里,点击容器右上角的 Edit 按钮在 Visualize 页打开可视化编辑。
标签:use 不能 网站服务器 键值 信息采集 按钮 jruby alt 值类型
原文地址:http://www.cnblogs.com/binyue/p/6694098.html