标签:意义 alt 复杂度 com 顺序 自己 内容 训练 分类
再次声明,总结内容基本非原创,只是一个勤劳的搬运工,由于来源比较杂,只好一起感谢网上提供这些知识的人类们。
一、关于线性回归
线性回归比较简单,这里主要是对线性回归的一种理解,包括部分正则化的内容。
1.模型的概率解释

2.最大似然估计

即:
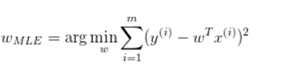
上面是线性回归最原始的最小平方损失函数,如果为了防止过拟合加入正则项,这里另一种理解就是加入先验分布。
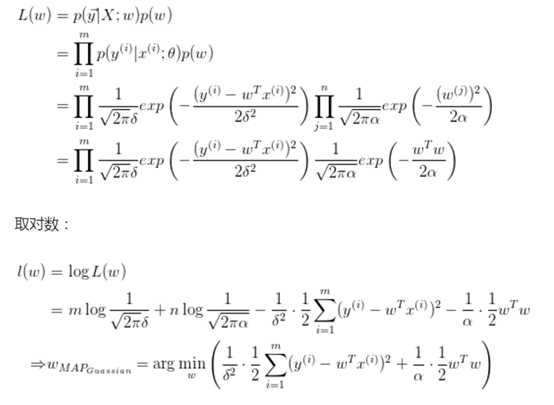
上式等价于: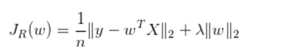 。可以看出相对于引入了高斯先验p(w)。
。可以看出相对于引入了高斯先验p(w)。
记忆一个结论:就是L2正则或者说ridge回归,即对参数引入高斯先验等于L2正则,对参数引入拉普拉斯分布等于引入L1正则。
了解这部分内容后大大加深了自己对正则的理解,具体可以参考下面知乎的一个问题。
参考:https://www.zhihu.com/question/23536142
二、Kmeans
1.缺点:(1)要求用户必须事先给出要生成的簇的数目k。(2)对初值敏感,对于不同的初始值,可能会导致不同的聚类结果。(3)对于"噪声"和孤立点数据敏感,少量的该类数据能够对平均值产生极大影响。
2.损失函数:
![]()
3.关于k的取值,可以用canopy算法来做,具体步骤如下,很简单的一个算法:
(1)设样本集合为S,确定两个阀值t1和t2,且t1>t2。
(2)任取一个样本点p,作为canopy,记为C,从S中移除p。
(3)计算S中所有点到p的距离dist
(4)若dist<t1,则将相应点归到C,作为弱相关。
(5)若dist<t2,则将 相应点移除S,作为强相关。
(6)重复(2)~(5),直到S为空。
自己语言总结下:就是顺序选点,把每个点和距离他一定距离之类的点当成一类,然后挖掉,剩下的再选。距离用欧式距离。这要看生成几类,每类中选一个作为起始的点,是一种解决K取值和点初始取值的方法。
4.选用欧式距离的时候要把指标标准化,算法停止条件:一般是目标函数达到最优或者达到最大的迭代次数即可终止。对于不同的距离度量,目标函数往往不同。当采用欧式距离时,目标函数一般为最小化对象到其簇质心的距离的平方和。当采用余弦相似度时,目标函数一般为最大化对象到其簇质心的余弦相似度和。
5.使用余弦距离时:对于特征向量归一化到模长为1。余弦距离和欧式距离才会等价。特征进行模长归一化为1,再将该训练数据丢到k-means里面去,即使使用欧式距离,那么也等价于使用了余弦距离。证明如下:余弦越大,距离越小。
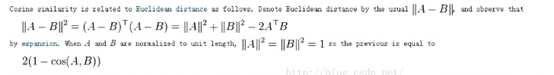
三、PageRank与PersonalRank
PageRank很著名不多说了,PersonalRank类似,也是用在图上计算节点相似度的一种方法,基于图的推荐可以用,还有simRank这些。给出PersonalRank公式如下:
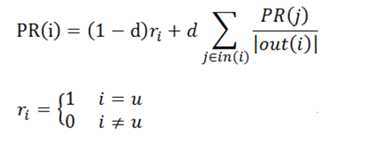
两个算法间的区别:Pagerank:确定概率随机跳转到随机网页,所以(1-a)/N,每个网页都有被跳到的概率。也可以理解为开始概率,而Personalrank不跳转,是停留,所以概率全留给了当前的这个网页,即只能从指定的用户u这个点开始。
四、关于GBDT
1.回归树与分类树的思路类似,但叶节点的数据类型不是离散型,而是连续型,对CART稍作修改就可以处理回归问题。CART算法用于回归时根据叶子是具体指还是另外的机器学习模型又可以分为回归树和模型树。但无论是回归树还是模型树,其适用场景都是:标签值是连续分布的,但又是可以划分群落的,群落之间是有比较鲜明的区别的,即每个群落内部是相似的连续分布,群落之间分布确是不同的。所以回归树和模型树既算回归,也称得上分类。
回归是为了处理预测值是连续分布的情景,其返回值应该是一个具体预测值。回归树的叶子是一个个具体的值,从预测值连续这个意义上严格来说,回归树不能称之为“回归算法”。因为回归树返回的是“一团”数据的均值,而不是具体的、连续的预测值(即训练数据的标签值虽然是连续的,但回归树的预测值却只能是离散的)。所以回归树其实也可以算为“分类”算法,其适用场景要具备“物以类聚”的特点,即特征值的组合会使标签属于某一个“群落”,群落之间会有相对鲜明的“鸿沟”。
2.而Gradient Boost与传统的Boost的区别是,每一次的计算是为了减少上一次的残差(residual),而为了消除残差,我们可以在残差减少的梯度(Gradient)方向上建立一个新的模型。所以说,在Gradient Boost中,每个新的模型的简历是为了使得之前模型的残差往梯度方向减少,与传统Boost对正确、错误的样本进行加权有着很大的区别。
3.且GBDT前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前N颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,思路更加合理,这应该也是用GBDT的原因。
4.GBDT 与逻辑回归的本质差别只在于 h 的不同。如果 h函数中的 x 为决策树,预测值通过决策树预测得到,那就是 GBDT;如果将 h 中的x变为一个权重向量,预测值为x与d的内积,则算法就变成了逻辑回归(LR)。
5.关于GBDT中Gardient的由来,以及网上说的有残差和梯度两个版本的的一些解释

关于GBDT中残差和梯度的关系,为什么有两个版本有的叫梯度,有的叫残差:

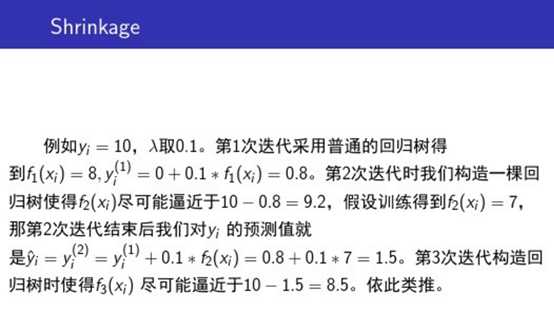
另外还有一个Shrinkage(收缩)的概念,举一个小例子:
6.关于调参:
树的个数 100~10000
叶子的深度 3~8
学习速率 0.01~1
叶子上最大节点树 20
训练采样比例 0.5~1
训练特征采样比例 sqrt(num)
7.优点:精度高,能处理非线性数据,能处理多特征类型,适合低维稠密数据。缺点:并行麻烦(因为上下两颗树有联系),多分类的时候 复杂度很大
标签:意义 alt 复杂度 com 顺序 自己 内容 训练 分类
原文地址:http://www.cnblogs.com/qingjiaowoyc/p/6699118.html