标签:index wan 倒序 函数 erro 唯一值 创建 src 针对
索引创建
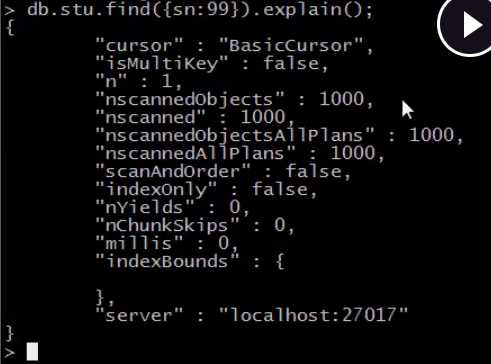
在学习索引之前,我们先看一下,如果没有添加索引时,我们用explain()函数,查看查询计划是什么样的。

发现使用的是BasicCursor,那么就代表我们没有索引,当我们查某一个数据的时候,就是从头到尾的扫一遍

a) 新增一条数据的同时,还会新增索引文件,所以会降低写入和更改速度,所以需要权衡字段,没必要添加太多的索引
2.在mongodb中,索引可以按字段升序(1)/降序(-1)来创建,便于排序
-1:磁盘上,二叉树倒序排序,由大到小,我们人眼是看不出来的
3.默认是用btree来组织所以文件,2.4版本以后,也允许建立hash索引
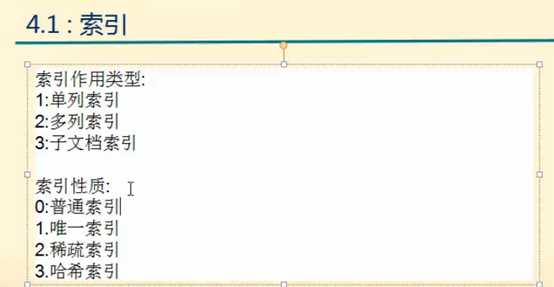
索引的分类:
常用命令:
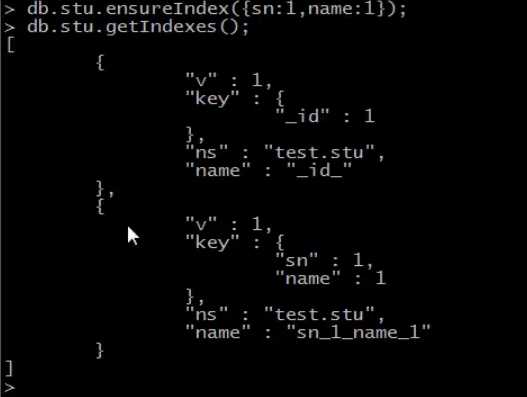
我们如何优化mysql的时候,有多人说,为where语句常用的字段添加索引,但是仔细想想,这么说实际上是错误的,因为我们的where语句,经常会好几个字段一起用,但是只能有一个索引起作用。所以应该建立多列索引。在mongo中也是这样的
多列索引和为每一个列都建立索引是不一样的,多列索引是把多个列看成一个整体,进行索引。如果两个列经常放在一起查,那么,使用多列索引要比在每一个列上加索引效率要高。
4.创建子文档索引:db.collection.ensureIndex(field.subfield:1/-1);
我们插入的数据为:
db.shop.insert({name:’Nokia’,spc:{weight:120,area:’taiwan’}});
{weight:120,area:’taiwan’}是子文档,如何在子文档中添加索引?使用点’.’,如下图
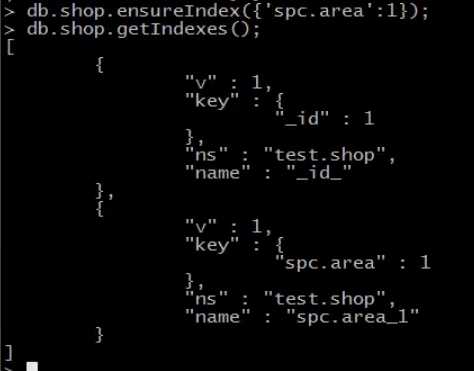
5.创建唯一索引:db.collection.ensureIndex({field.subfield:1/-1},{unique:true});

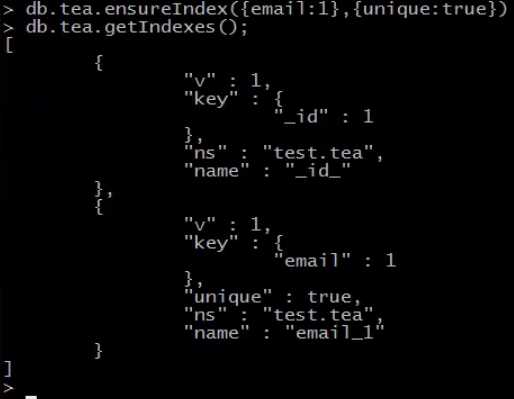
注意:唯一索引,这个列上的值不能重复,下图中,我们在添加了唯一索引的列email中,添加两条相同的值,会报error

6.创建稀疏索引:
稀疏索引的特点----如果针对field做索引,针对不含field列的文档,将不建立索引,与之相对,普通索引,会把该文档的field列的值认为NULL,并建立索引
适宜于:小部分文档含有某列时
db.collection.ensureIndex({field:1/-1},{sparse:true});
创建非稀疏索引:结果如下:
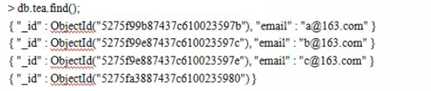
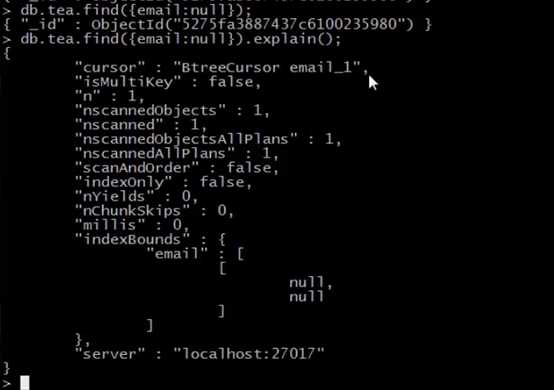
删除索引之后,再添加稀疏索引,结果如下


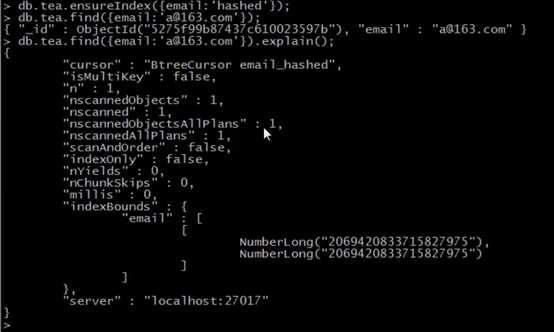
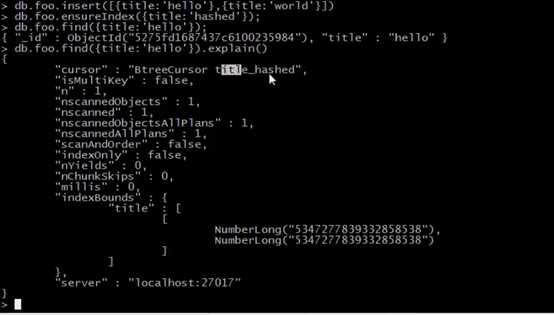
7.创建哈希索引(2.4新增的)
哈希索引速度比普通索引要快,但是无法对范围查询进行优化,适宜于—随机性强的散列
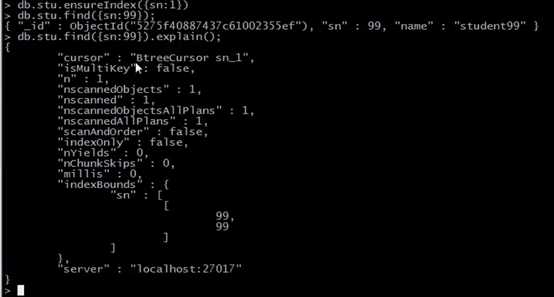
简要介绍一下哈希索引:哈希索引是通过把key给哈希函数,然后通过哈希函数计算出一个唯一值,从而决定了这个数据存放在磁盘的什么位置上。所以值的存储是散列的,没有可循的规律性,当我们要查找一个数据的时候,比如查找学号为99的学生,我们可以这样。但是我们要查找200-500这样一个范围内的所有学生,哈希索引显然就不合适了。因为它的存储不是连续的,在这种情况普通索引就要好很多。
db.collection.ensureIndex({field:’hashed’});
8.删除单个索引
db.collection.dropIndex({field:1/-1});//字段,和排序方式(1/-1)都需要指明

删除所有索引
db.collection.dropIndexes();

9.重建索引

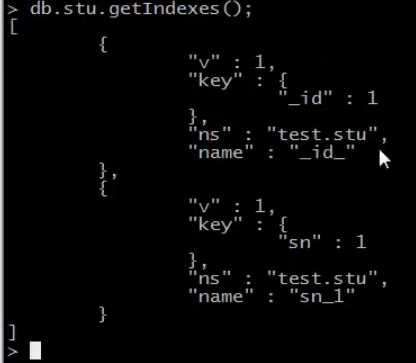
_id索引是自带的,必须会有的

email_1 升序排列
标签:index wan 倒序 函数 erro 唯一值 创建 src 针对
原文地址:http://www.cnblogs.com/mrxiaohe/p/6700536.html