标签:htm 内容 文档 mooc beautiful nbsp ble request img
1 基本信息
Beautiful Soup是用于处理解析页面信息的
具体的说, Beautiful Soup库是解析, 遍历, 维护"标签树"的功能库
安装方法
pip install beautifulsoup4
最基本的使用
import requests
from bs4 import BeautifulSoup
r = requests.get("http://www.baidu.com")
soup = BeautifulSoup(r.content, ‘html.parser‘)
print(soup.prettify())
2 基本元素
Beautiful Soup处理的内容文档一般是HTML页面
HTML页面是标签对形成的
这些标签对最终会形成标签树, 这些标签树实际上是Beautiful Soup类
也就是 HTML文档<---->标签树<---->Beautiful Soup类
Beautiful Soup的解析器

最主要的还是是用 html.parser解析器
Beautiful Soup类的基本元素

使用方法如下:
1) Tag标签
使用方法
BS对象.标签名字
soup.a soup.title
其中如果该标签在页面存在多个, 那么只返回第一个
2) name
使用方法
BS对象.标签名字.name
3) attrs
使用方法
其中attrs获得的是一个字典类型的值
通过属性名字得到的就是列表类型
BS对象.标签名字.attrs
BS对象.标签名字.attrs[‘某个属性的名字‘]
soup.a.sttrs soup.a.attrs[‘class‘]
4) NavigableString
表示的是标签内非属性的字符串, 使用如下
其中string如果该标签内存在别的标签嵌套, 获得的就是嵌套内部的string
因此, NavigableString可以跨越多个层次
BS对象.标签名字.string
5) Comment
标签内注释部分
获取方法和NavigableString相同, 都是通过string来获得
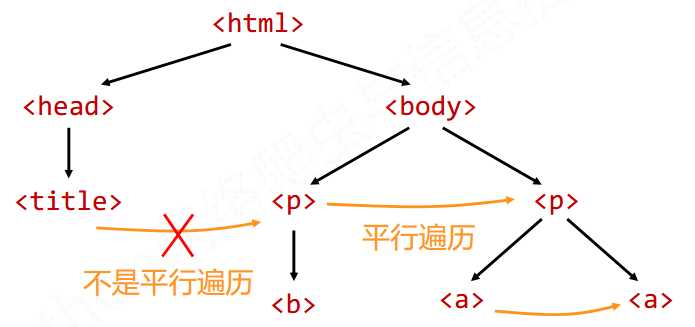
3 标签树的遍历
遍历分为 下行遍历, 上行遍历, 平行遍历
上行遍历的主要有: contents, children, descendants
其中contens获得的是标签的所有内容
children或的是contents的具体的列表, 其中‘\n‘会被当做一个元素
descendants和children都是生成器, descendants会逐步往下遍历打印出所有子孙节点
上行遍历主要有: parent, parents
parent获得的是父亲节点, 获得的父亲节点包括该节点内的所有内容, 是一个很丰富的节点
parents是一个生成器, 倒数第二个是<html>标签. 最后一个是整个文档
平行遍历主要有: next_sibling, previous_sibling, next_siblings, previous_siblings
注意: 平行是指的在一个父节点下的子节点间的
标签:htm 内容 文档 mooc beautiful nbsp ble request img
原文地址:http://www.cnblogs.com/weihuchao/p/6701201.html