标签:wordcount name 本地 rmi truncate load data add 集合 orm



 Default数据库,默认的,优先级相对于其他数据库是最高的
Default数据库,默认的,优先级相对于其他数据库是最高的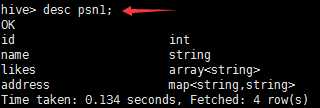
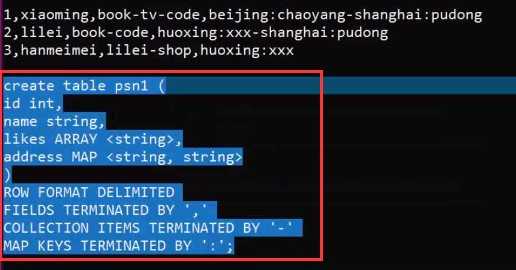
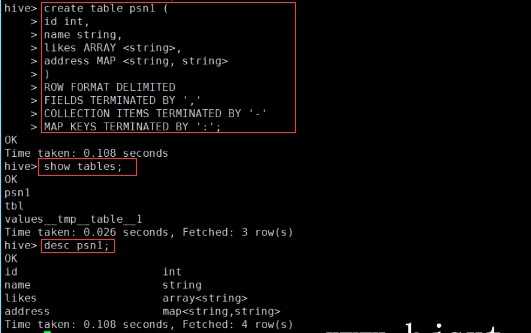
– create table person(– id int,– name string,– age int,– likes array<string>,– address map<string,string>–)– row format delimited– FIELDS TERMINATED BY ‘,‘– COLLECTION ITEMS TERMINATED BY ‘-‘– MAP KEYS TERMINATED BY ‘:‘– lines terminated by ‘\n‘;–Select address[‘city’] from person where name=‘zs’



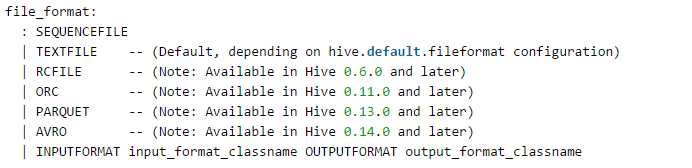
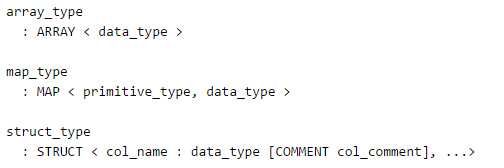
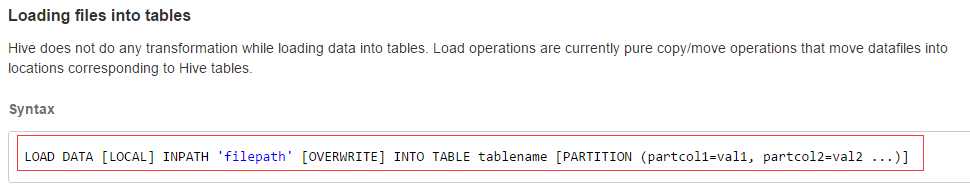
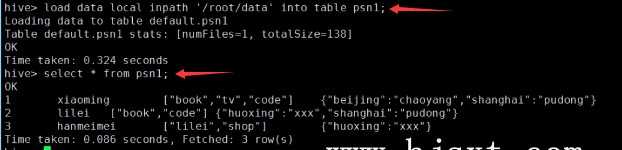
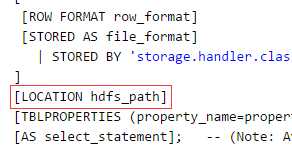
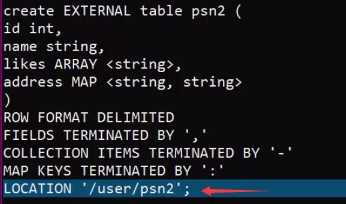


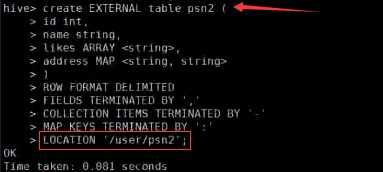
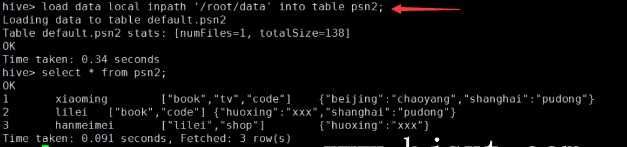

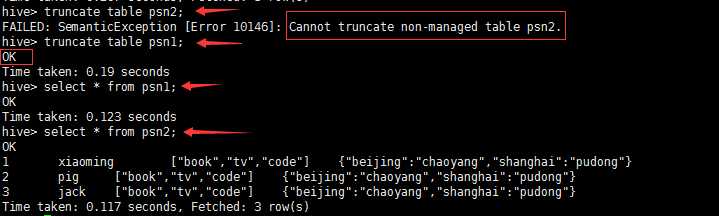
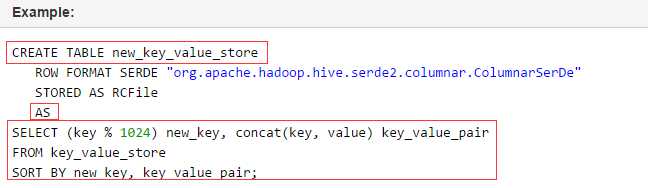
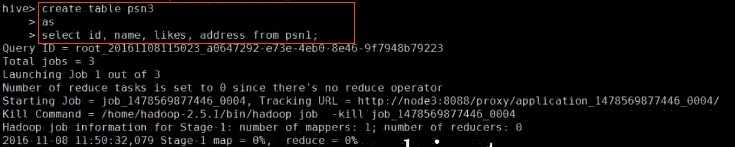
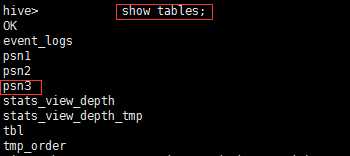
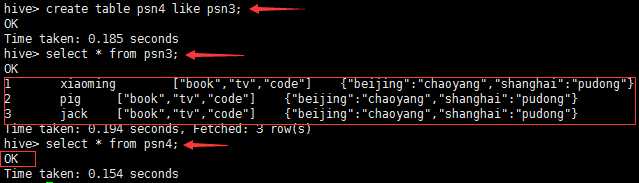
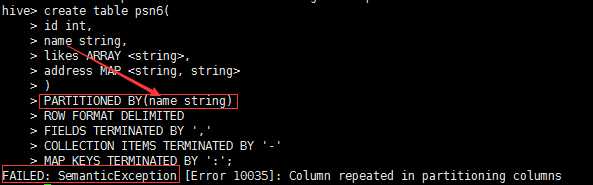
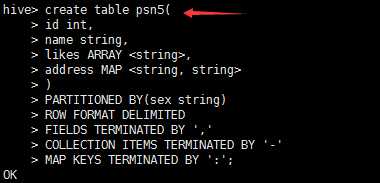





---分区_指定两个分区字段create table psn5(id int,name string,likes ARRAY <string>,address MAP <string, string>)PARTITIONED BY(sex string,age int)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ‘,‘COLLECTION ITEMS TERMINATED BY ‘-‘MAP KEYS TERMINATED BY ‘:‘;---创建分区后,再进行插入数据,就需要指定分区字段load data local inpath ‘/root/data‘ into table psn5 partition (sex=‘boy‘,age=1);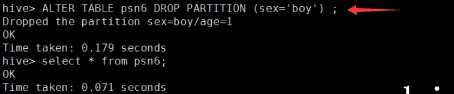
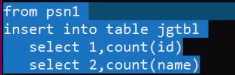
create table psn7 like psn1;from psn1insert into table psn7 select id, name, likes, address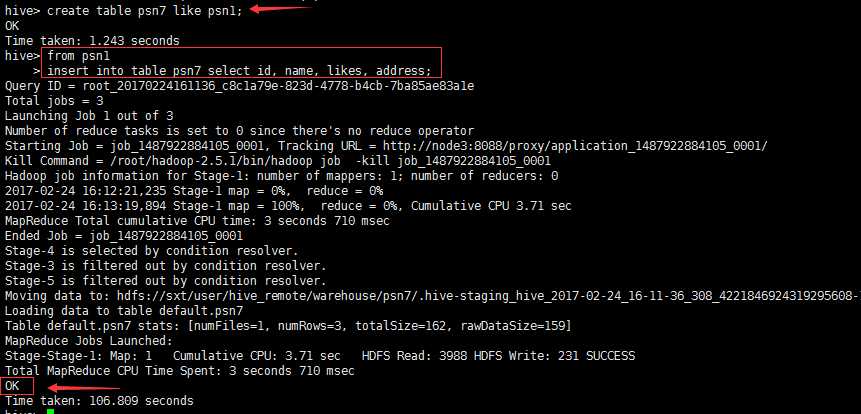
标签:wordcount name 本地 rmi truncate load data add 集合 orm
原文地址:http://www.cnblogs.com/jxhd1/p/6702235.html