标签:style blog http 使用 io 文件 数据 ar 2014
最近在工作之余的时间在阅读集体智慧编程这本书,在随书码字的过程中遇到的一些问题,就在这里记录一下:
(注:下面的页码针对于英文的非影印版)
chapter1 标题:
没什么说的,浏览下就好。
chapter2 提供推荐:
1.书上的源码是基于python 2.x,而在3.x中print是被当作一个函数处理,所以要自己加上括号;
2.在P42利用del.icio.us提供的rss订阅源构建数据集时,这本书发布时间较长的原因,python api pydelicious的
很多接口已经发生了改变,这个实验我最后跳过了,作了后面的MovieLens,书中数据的下载地址为:
http://grouplens.org/datasets/movielens/;
chapter3 发现群组:
仍然是数据集构建的问题,我们学习的主要重心在于数据的处理部分,而非数据的采集,所以可以采用将数据文件直接下载的方法,
我们将http://kiwitobes.com/clusters/feedlist变更为http://segaran.com/clusters/feelist,之后只要出现kiwitobes直接
替换为segaran就可以了;关于PIL的安装,不要采用python的easy_install或者pip install,直接下载对应
平台的可执行文件即可,在这里我下载的是PIL-1.1.7.win32-py2.7.exe,直接安装即可;
chpter4 搜索与排名:
1.关于数据库sqlite的安装在python2.x的版本中,是有包含sqlite的,所以大部分情况下自己也无需安装,具体可以可以在python
的安装路径python/Lib/下,如果找到sqlite3就表示可以直接使用,相应的导入包的语句变更为import sqlite3 as sqlite即可
2.在P85的部分是没有介绍函数addlinkref,有需要的同学需要自己到随书源码包中去查看
3.在calculatepagerank(self,iterations)函数中,初始化pagerank表时,书中的源码和随书源码是不同的,但书中源码的效率
较高

4.代码输出结果不同:
a.创建的searchindex.db,书中是27mb左右,自己生成的是22mb左右,这个原因主要是一些链接的失效
b.P103未训练之前getresult函数产生的结果应该是0.076,后面经过多次训练,以及本身数据集不同的原因,输出结果不同
是正常的现象。
c.需要注意一点,一般在创建好数据库和表时,第一次必须执行一次产生隐藏层节点的函数,generatehiddennode(wordids,urlids)
在nn.py中
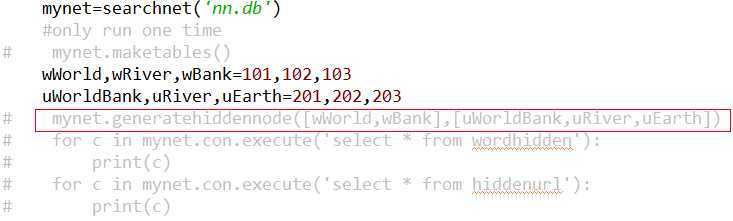
在searchengine.py中
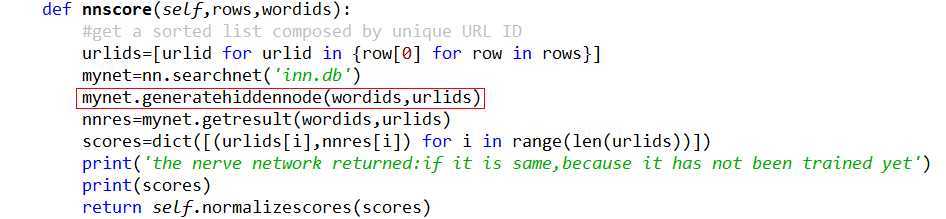
标签:style blog http 使用 io 文件 数据 ar 2014
原文地址:http://www.cnblogs.com/gachiman/p/3932656.html