标签:addclass 工具 date 函数 c++ table type 数学 活性
| 库名 | 主语言 | 从语言 | 速度 | 灵活性 | 文档 | 适合模型 | 平台 | 上手难易 | 开发者 | 模式 |
|---|---|---|---|---|---|---|---|---|---|---|
| Tensorflo | C++ | cuda/python/Matlab/Ruby/R | 中等 | 好 | 中等 | CNN/RNN | Linux,OSX | 难 | 分布式/声明式 | |
| Caffe | C++ | cuda/python/Matlab | 快 | 一般 | 全面 | CNN | 所有系统 | 中等 | 贾杨清 | 声明式 |
| PyTorc | python | C/C++ | 中等 | 好 | 中等 | - | – | 中等 | ||
| MXNet | c++ | cuda/R/julia | 快 | 好 | 全面 | CNN | 所有系统 | 中等 | 李沐和陈天奇等 | 分布式/声明式/命令式 |
| Torch | lua | C/cuda | 快 | 好 | 全面 | CNN/RNN | Linux,OSX | 中等 | 命令式 | |
| Theano | python | c++/cuda | 中等 | 好 | 中等 | CNN/RNN | Linux, OSX | 易 | 蒙特利尔理工学院 | 命令式 |
它有一个直观的结构 ,顾名思义它有 “张量流”,你可以轻松地可视每个图中的每一个部分。
轻松地在 cpu / gpu 上进行分布式计算
平台的灵活性 。可以随时随地运行模型,无论是在移动端、服务器还是 PC 上。尽管 TensorFlow 是强大的,它仍然是一个低水平库,例如,它可以被认为是机器级语言,但对于大多数功能,您需要自己去模块化和高级接口,如 keras
它仍然在继续开发和维护,这是多么??啊!
它取决于你的硬件规格,配置越高越好
不是所有变成语言能使用它的 API 。
TensorFlow 中仍然有很多库需要手动导入,比如 OpenCL 支持。
上面提到的大多数是在 TensorFlow 开发人员的愿景,他们已经制定了一个路线图,计划库未来应该如何开发建立一个计算图, 任何的数学运算可以使用 TensorFlow 支撑。
初始化变量, 编译预先定义的变量
创建 session, 这是神奇的开始的地方 !
在 session 中运行图, 编译图形被传递到 session ,它开始执行它。
关闭 session, 结束这次使用。TensorFlow入门一-小石头的码疯窝
TensorFlow之深入理解Neural Style
TensorFlow之深入理解AlexNet-小石头的码疯窝
TensoFlow之深入理解GoogLeNet-小石头的码疯窝
TensorFlow之深入理解VGG\Residual Network
TensorFlow之深入理解Fast Neural Style
风格画之最后一弹MRF-CNN-小石头的码疯窝
深度学习之Neural Image Caption
Caffe57是纯粹的C++/CUDA架构,支持命令行、Python和MATLAB接口;可以在CPU和GPU173直接无缝切换:
Caffe::set_mode(Caffe::GPU);1.上手快:模型与相应优化都是以文本形式而非代码形式给出。
2.Caffe给出了模型的定义、最优化设置以及预训练的权重,方便立即上手。
3.速度快:能够运行最棒的模型与海量的数据。
4.Caffe与cuDNN结合使用,测试AlexNet模型,在K40上处理每张图片只需要1.17ms.
5.模块化:方便扩展到新的任务和设置上。
6.可以使用Caffe提供的各层类型来定义自己的模型。
7.开放性:公开的代码和参考模型用于再现。
8.社区好:可以通过BSD-2参与开发与讨论。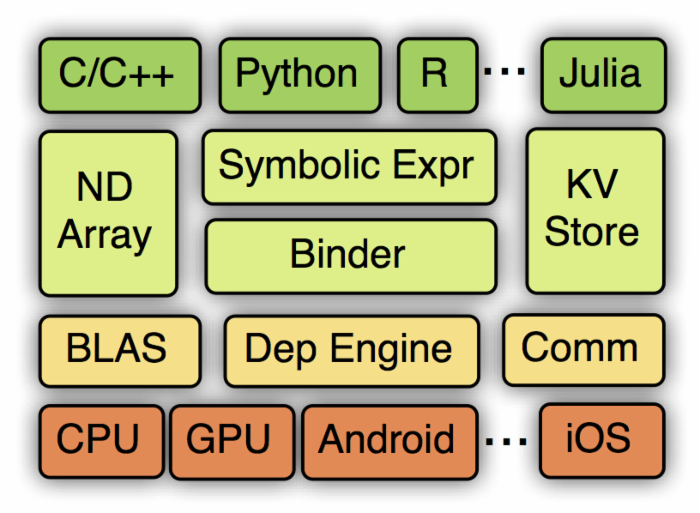
输入:一批图像和label (2和3)
输出:leveldb (4)
指令里包含如下信息:
conver_imageset (构建leveldb的可运行程序)
train/ (此目录放处理的jpg或者其他格式的图像)
label.txt (图像文件名及其label信息)
输出的leveldb文件夹的名字
CPU/GPU (指定是在cpu上还是在gpu上运行code)Imagenet_solver.prototxt (包含全局参数的配置的文件)
Imagenet.prototxt (包含训练网络的配置的文件)
Imagenet_val.prototxt (包含测试网络的配置文件)Caffe教程系列之安装配置
Caffe教程系列之LeNet训练
Caffe教程系列之元素篇
Caffe教程系列之Proto元素
Caffe教程系列之LMDB
pytorch,语法类似numpy,非常高效;基于pytorch开发深度学习算法,方便快速,适合cpu和gpu计算。pytorch支持动态构建神经网络结构,从而可以提升挽留过结构的重用性。
这是一个基于Python的科学计算包,其旨在服务两类场合:
1.替代numpy发挥GPU潜能
2.一个提供了高度灵活性和效率的深度学习实验性平台1.运行在 GPU 或 CPU 之上、基础的张量操作库,
2.内置的神经网络库
3.模型训练功能
3.支持共享内存的多进程并发(multiprocessing )库。PyTorch开发团队表示:这对数据载入和 hogwild 训练十分有帮助。
4.PyTorch 的首要优势是,它处于机器学习第一大语言 Python 的生态圈之中,使得开发者能接入广大的 Python 库和软件。因此,Python 开发者能够用他们熟悉的风格写代码,而不需要针对外部 C 语言或 C++ 库的 wrapper,使用它的专门语言。雷锋网(公众号:雷锋网)获知,现有的工具包可以与 PyTorch 一起运行,比如 NumPy、SciPy 和 Cython(为了速度把 Python 编译成 C 语言)。
4.PyTorch 还为改进现有的神经网络,提供了更快速的方法——不需要从头重新构建整个网络1.torch :类似 NumPy 的张量库,强 GPU 支持
2.torch.autograd :基于 tape 的自动区别库,支持 torch 之中的所有可区分张量运行。
3.torch.nn :为最大化灵活性未涉及、与 autograd 深度整合的神经网络库
4.torch.optim:与 torch.nn 一起使用的优化包,包含 SGD, RMSProp, LBFGS, Adam 等标准优化方式
5.torch.multiprocessing: python 多进程并发,进程之间 torch Tensors 的内存共享。
6.torch.utils:数据载入器。具有训练器和其他便利功能。 Trainer and other utility functions for convenience
7.torch.legacy(.nn/.optim) :处于向后兼容性考虑,从 Torch 移植来的 legacy 代码。PyTorch深度学习:60分钟入门(Translation)
1.速度快省显存。在复现一个caffe
2.支持多语言
3.分布式1. API文档差。这个问题很多人也提过了,很多时候要看源码才能确定一个函数具体是做什么的,看API描述有时候并不靠谱,因为文档有点过时。
2. 缺乏完善的自定义教程。比如写data iter的时候,train和validation的data shape必须一致,这是我当时找了半天的一个bug。
3.代码小bug有点多。mxnet的大神们开发速度确实是快,但是有的layer真的是有bug,暑假我们就修了不少。
从上到下分别为各种主语言的嵌入,编程接口(矩阵运算,符号表达式,分布式通讯),两种编程模式的统一系统实现,以及各硬件的支持。接下一章我们将介绍编程接口,然后下一章介绍系统实现。之后我们给出一些实验对比结果,以及讨论MXNet的未来。
##4.2 MXNet编程接口
1.Symbol : 声明式的符号表达式
2.NDArray :命令式的张量计算
3.KVStore :多设备间的数据交互
4.读入数据模块
5.训练模块
##4.3 MXNet教程
安装GPU版mxnet并跑一个MNIST手写数字识别
用MXnet实战深度学习之二:Neural art
#5. Torch框架
##5.1 Torch诞生
Torch诞生已经有十年之久,但是真正起势得益于去年Facebook开源了大量Torch的深度学习模块和扩展。Torch另外一个特殊之处是采用了不怎么流行的编程语言Lua(该语言曾被用来开发视频游戏)。
1)Facebook力推的深度学习框架,主要开发语言是C和Lua
2)有较好的灵活性和速度
3)它实现并且优化了基本的计算单元,使用者可以很简单地在此基础上实现自己的算法,不用浪费精力在计算优化上面。核心的计算单元使用C或者cuda做了很好的优化。在此基础之上,使用lua构建了常见的模型
4)速度最快,见convnet-benchmarks
5)支持全面的卷积操作:
时间卷积:输入长度可变,而TF和Theano都不支持,对NLP非常有用;
3D卷积:Theano支持,TF不支持,对视频识别很有用1)是接口为lua语言,需要一点时间来学习。
2)没有Python接口
3)与Caffe一样,基于层的网络结构,其扩展性不好,对于新增加的层,需要自己实现(forward, backward and gradient update)1)2008年诞生于蒙特利尔理工学院,主要开发语言是Python
2)Theano派生出了大量深度学习Python软件包,最著名的包括Blocks和Keras
3)Theano的最大特点是非常的灵活,适合做学术研究的实验,且对递归网络和语言建模有较好的支持
4)是第一个使用符号张量图描述模型的架构
5)支持更多的平台
6)在其上有可用的高级工具:Blocks, Keras等1)编译过程慢,但同样采用符号张量图的TF无此问题
2)import theano也很慢,它导入时有很多事要做
3)作为开发者,很难进行改进,因为code base是Python,而C/CUDA代码被打包在Python字符串中Theano 官方中文教程(翻译)(三)——多层感知机(MLP)
Theano官方中文教程(翻译)(四)—— 卷积神经网络(CNN)
标签:addclass 工具 date 函数 c++ table type 数学 活性
原文地址:http://blog.csdn.net/baihuaxiu123/article/details/70194566