标签:实例 集中 其他 ict 操作 tail conf 查看 诸葛亮
随机森林模型是一种数据挖掘模型,常用于进行分类预测。随机森林模型包含多个树形分类器,预测结果由多个分类器投票得出。 决策树相当于一个大师,通过自己在数据集中学到的知识对于新的数据进行分类。俗话说得好,一个诸葛亮,玩不过三个臭皮匠。随机森林就是希望构建多个臭皮匠,希望最终的分类效果能够超过单个大师的一种算法。
参考资料:
目录:
相关概念
预测效果影响因素
估值过程
oob error
R实现
> remove(list=ls()) > > #检验包是否安装 > valiate <- any(grepl("randomForest",installed.packages())) > if (valiate == FALSE) + { + install.packages("randomForest") + } > library(randomForest) > > head(iris) Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.3 0.2 setosa 4 4.6 3.1 1.5 0.2 setosa 5 5.0 3.6 1.4 0.2 setosa 6 5.4 3.9 1.7 0.4 setosa > str(iris) ‘data.frame‘: 150 obs. of 5 variables: $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ... $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ... $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ... $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ... $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...
> #选择最优mtry参数值 > n <- ncol(iris) -1 > errRate <- c(1) > for (i in 1:n){ + m <- randomForest(Species~.,data=iris,mtry=i,proximity=TRUE) + err<-mean(m$err.rate) + errRate[i] <- err + } > print(errRate) [1] 0.05462878 0.04320072 0.04302654 0.04316091 > #选择平均误差最小的m > m= which.min(errRate) > print(m) [1] 3
#选择最优ntree参数值 rf_ntree <- randomForest(Species~.,data=iris) plot(rf_ntree)
结果图如下:
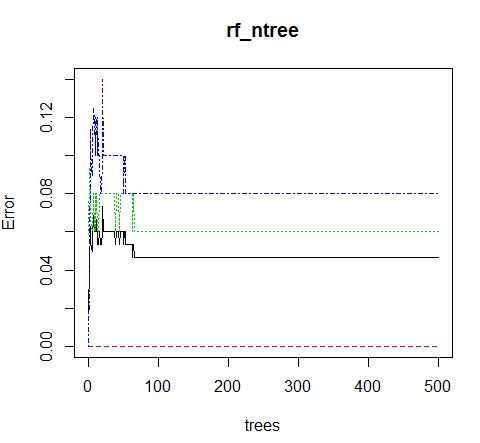
> m <- randomForest(Species~.,data=traindata,mtry=3,ntree=100, proximity=TRUE) > print(m) Call: randomForest(formula = Species ~ ., data = traindata, mtry = 3, ntree = 100, proximity = TRUE) Type of random forest: classification Number of trees: 100 No. of variables tried at each split: 3 OOB estimate of error rate: 5.41% Confusion matrix: setosa versicolor virginica class.error setosa 39 0 0 0.00000000 versicolor 0 33 3 0.08333333 virginica 0 3 33 0.08333333
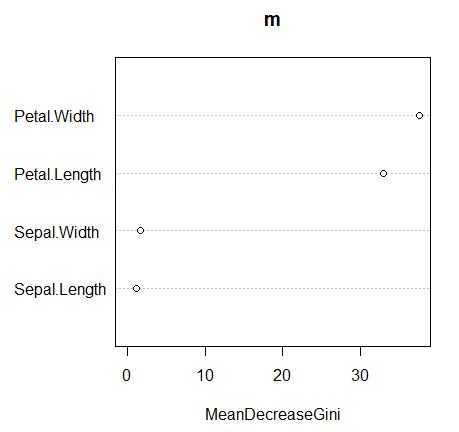
importance()函数:用于计算模型变量的重要性
> # importance()函数用于计算模型变量的重要性 > importance(m) MeanDecreaseGini Sepal.Length 1.201101 Sepal.Width 1.685455 Petal.Length 32.926760 Petal.Width 37.559478 > varImpPlot(m)
图例:
标签:实例 集中 其他 ict 操作 tail conf 查看 诸葛亮
原文地址:http://www.cnblogs.com/tgzhu/p/6708947.html