标签:shuffle page 其他 ges map 通过 多线程 ted 重构
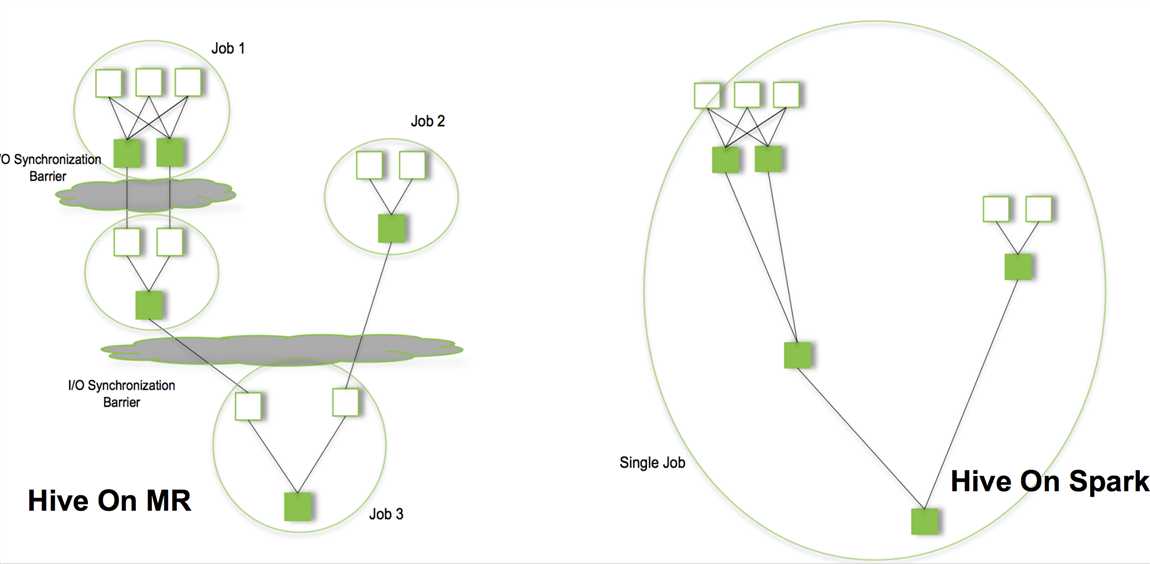
Spark比Mapreduce更加高效,主要原因是:
1内存计算引擎,提供Cache机制来支持需要反复迭代计算或者多次数据共享,减少数据读取的IO开销;
2DAG引擎,减少多次计算之间中间结果写到HDFS的开销;
3使用多线程池模型来减少task启动开稍,shuffle过程中避免不必要的sort操作以及减少磁盘IO操作.
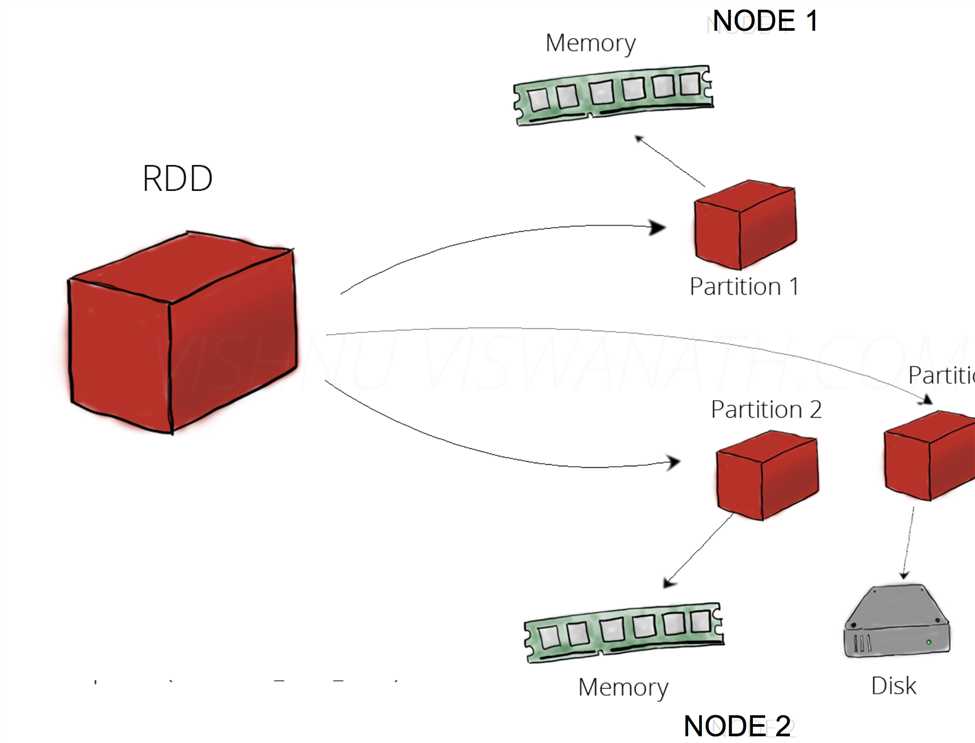
RDD:Resilient Distributed Datasets,弹性分布式数据集
定义:分布在集群中的只读对象集合。一个RDD可由多个Partition构成,分散存储在多个节点中。
弹性:可以存储在磁盘或内存中(多种存储级别)。一个RDD可以部分存在内存中,部分存在磁盘中。
转换:通过并行“转换”操作构造。例如一个RDD中所有数加1生成一个新的RDD。
容错性:失效后自动重构。记住各个RDD之间的转换关系,当一个RDD丢失后可由其他RDD推出丢失的RDD。
RDD与partition,节点的关系:
标签:shuffle page 其他 ges map 通过 多线程 ted 重构
原文地址:http://www.cnblogs.com/coldyan/p/6726632.html