标签:用户访问 目标地址转换 支持 中继 检查 关联 负载均衡 直接路由 机房
首先我们要了解LVS的工作机制:
LVS里Director本身不响应请求,只是接受转发请求到后方,Realservers才是后台真正响应请求。
LVS 工作原理基本类似DNAT,又不完全相像,它是一种四层交换,默认情况下通过用户请求的地址和端口来判断用户的请求,从而转发到后台真正提供服务的主机,而判断这种请求的是通过套接字来实现,所以四层就可以实现。
而且这个转发的过程对用户而言是透明的(简单的讲,就是用户访问DR的IP,而DR转发给RSS,而用户不知道这个过程)
LVS的工作模式:
1.DNAT
2.直接路由(DR)
3.隧道(tunnel)
2、提供的优点:
1.高并发
2.高冗余
3.适用性,扩展服务器,缩减服务器,方便服务器扩展和收缩
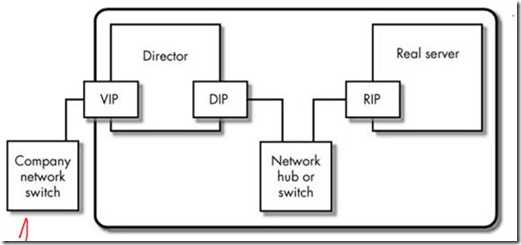
LVS 的IP地址类型
1.VIP:虚拟IP地址,并不提供服务,而是将用户的请求转发到后方(冗余网关的IP)
2 RIP:真正IP地址,客户端真正提供服务的IP地址(后端真实机的IP)
3.DIP:调度IP地址,通常是和RIP相连的LVS的IP地址(进行调度服务的IP)
4.CIP:客户端IP地址,用户请求时,用户的IP(客户端IP)
流程:如下图
LVS集群的类型:
1.LVS-NAT DNAT
2.LVS-DR 直接路由
3.LVS-TUN 隧道
下面我们详细说明这三种类型:
===============================================================================LVS-NAT模型=============================================================================================
LVS-NAT模型原理
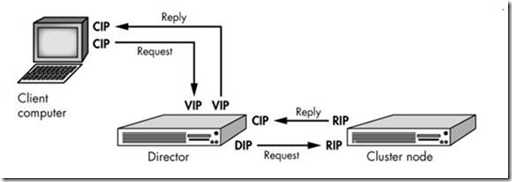
用户的请求和响应都需要经过Director
源地址,目标地址都需要经过转换,而目标地址转换是透明的
这种架构的扩展有限调度器,Director将处理所有的请求,压力比较大,扩展到10个结点就不行了
要求:
1.集群节点必须在同一个物理网络中,同一个子网或者VLAN
2.DIP和RIP只能在同一个网络(子网)中,不能跨越网段,跨网段的话 ,中间会断开,不能中继
3.RIP地址通常是私有地址,
4.所有的RIP,必须以DIP为网关(地址转换),
5.NAT的地址可以做端口转换(比如80--8080)
6.任何操作系统都可以做RIP,只要后端有服务
7.Director有可能成为整个系统的瓶颈
数据传输:
客户端访问VIP的服务(CIP->VIP),VIP根据调度算法把数据转发给一台后端RSS,进行数据包重写(IP头改为:VIP->RIP,MAC帧改为:Mvip->Mrip),RIP收到数据包后,进行解包,发现是给自己的,然后就根据收到的数据包中的内容进行回复,回复给VIP,同样进行数据包重写,给VIP后直接回复给CIP。
===============================================================================LVS-DR模型===============================================================================
LVS-DR模型原理
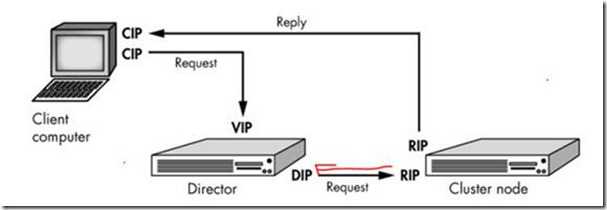
用户的请求必须经过Director,而realserver在响应的使用直接返回请求(图有问题,有可能设的网关不同,还存在一台路由器)
需要配置iptables规则,拒绝响应MAC地址转换,或者通过修改LINUX内核响应
优点:由于它比NAT少了一个地址转换,响应速度更快
特点
1.必须处于同一个物理网络中(连在同一个交换机上)
2.RIP可以使用公网地址(建议使用)
3.Director只转发请求,而realserver直接响应请求
4.集群节点的网关,不能指向DIP
5.不能做端口转换(不支持)
6.绝大多数的操作系统都可以实现realserver,而realserver需要同一个网卡配置多个Ip地址
7.DR模式的Director比NAT模式能够带动更多的节点
数据传输:
解决数据进入:
为了避免RS直接响应,给服务器的lo:0设置VIP地址,给本地网卡设置成CIP,这样RS就不会直接响应了,隐藏了RS
解决数据出去:
而默认情况下,Linux设置数据包从哪块网卡出去,源地址设为该网卡地址,通过添加一条特殊路由信息,如果目标地址是lo的VIP地址,那么出去的时候源地址设置为lo的地址。
路由信息的原理:
添加一条主机路由,将VIP的地址自己设置成一个网段,既子网掩码为255.255.255.255,这样VIP出去的时候没有比VIP更优的了,就成为最佳IP
在互联网上性能最佳的就是DR应用,但是有一个缺点,必须要求主机间距离比较近(比如一个机房),如果发生天灾人祸,集群就完了,所以我们为了实现异地分布,要采用隧道比如VPN
=========================================================================================LVS-TUN模型===============================================================================
LVS-TUN模型原理:
虚拟隧道实现:
1.专线(加密)
2.二层:在MAC之外再加一层MAC
3.三层:源IP目标IP之外再加一层IP
隧道目的: 隐藏意图,通过转换来(ip套ip)隐藏目的
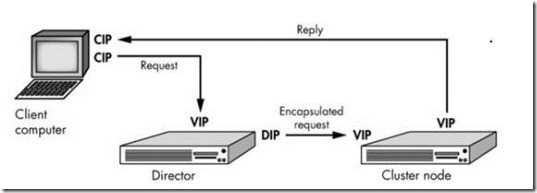
特征:
1.集群节点和Director不必在同一个网络,也可以位于不同网段。
2.RIP必须使用公网地址
3.Director只需要处理进来的请求,不需要处理出去的请求
4.响应的请求一定不能经过Direcor.
5.只能使用那些支持IP 隧道协议的操作系统做realserver
优点:LVS-TUN可以实现基于网络的集群,这样就脱离了LVS-DR和realserver之间的距离限制。
========================================================================================================调度算法介绍===============================================================================
LVS的负载均衡要依赖算法(Scheduling methods :调度方法)来实现,根据特点它们分为如下两类:
1.fiexd scheduling 静态(固定)
2.dnamic scheduling 动态
FIEXD SCHEDULING静态算法
特点:不考虑后端realserver的连接状态,而动态的要考虑后端的链接数为标准
1. Round-robin (RR) 轮询
既第一次访问A,第二次访问B,第三次再访问A…..循环下去
2. Weighted Round-Robin WRR
加强论调:提高后台服务器的响应能力
根据后方服务器的响应能力,来定义权重,根据权重来转发请求,权重大的优先访问
3.Destination hashing DH
目的:实现针对目标地址的请求做固定转发,基于目标
将来自同一个用户的特定请求转发到固定的指定的主机(比如提供web服务),以提高缓存(网页文件缓存)利用率(命中率)。
4.Souce hashing SH
目的:将来自同一个用户的地址,始终转发到router或者firewall,基于源
应用场景:
将用户的请求按照平均指定到不同的防火墙,实现平均内网负载,通过特定防火墙(网关)出去(上网)
静态算法的缺陷:不考虑后台real-server的负载,连接状态
动态算法:Dynamic Scheduling Mehtod
这里有两个概念:
活动连接:后台real-server当前处于活动状态(active)和ESTABLISHED state(想关联)的连接,像ssh,或者telnet会一直处于活动状态。
非活动连接:非活动的状态(inactive)或者非FIN的数据包,比如httpd(未开启keepalive), 而httpd除非启用keepalive, 发送完成后直接断开,处于inactive的状态
相关动态算法 :
1. LC least-connection 最少连接
LC同时检查一台主机上的活动连接数和非活动连接数,连接数最少(活动状态的连接数少)的将会接受下一个连接请求。
LC同时考察活动连接和非活动连接,它用活动连接*256+非活动连接作为 overhead 通过overhead谁的小,转发给谁
但是非活动链接也会影响连接,当活动连接的比数比较大的时候,会影响结果
2.WLC Weighted Least-Connection 加权最少连接数
加权按照机器的性能划分。Overhead/加权请求要转发给小得那个
加权算法,是集群应用上的最好的算法之一,比较公平
2. SED Shortest Expected Delay 最短延迟
在WLC基础上改进
Overhead = (ACTIVE+1)*256/加权
不再考虑非活动状态,把当前处于活动状态的数目+1来实现,数目最小的,接受下次请求
+1的目的是为了考虑加权的时候,非活动连接过多
缺陷:当权限过大的时候,会导致空闲服务器一直处于无连接状态
3.NQ算法永不排队
保证不会有一个主机很空闲。在SED基础上无论+几,第二次一定给下一个,保证不会有一个主机不会很空闲
不考虑非活动连接,才用NQ,SED要考虑活动状态连接
对于DNS的UDP不需要考虑非活动连接,而httpd的处于保持状态的服务就需要考虑非活动连接给服务器的压力
4.LBLC 基于本地的最少连接算法
和DH的区别:考虑后台的负载能力和连接情况
支持权重,它在WLC基础上改进
5.LBLCR 基于本地的带复制的最少连接数
是对LBLC的一个改进,能够在LBLC的基础上实现负载均衡
判断后端,到底谁的连接少,当A的连接很多,而B的很空闲,会将A的部分连接分配到B上(打破原有规则,避免大范围的不公平)
标签:用户访问 目标地址转换 支持 中继 检查 关联 负载均衡 直接路由 机房
原文地址:http://www.cnblogs.com/skyflask/p/6731044.html