标签:.com 节点 判断 左右 3.3 mil 哈夫曼树 ade 之间
本博客的代码的思想和图片参考:好大学慕课浙江大学陈越老师、何钦铭老师的《数据结构》
将百分制的考试成绩转换成五分制的成绩,程序如下:
if( score < 60 ) grade =1;
else if( score < 70 ) grade =2;
else if( score < 80 ) grade =3;
else if( score < 90 ) grade =4;
else grade =5;
那么上面这个其实是一棵判断树:
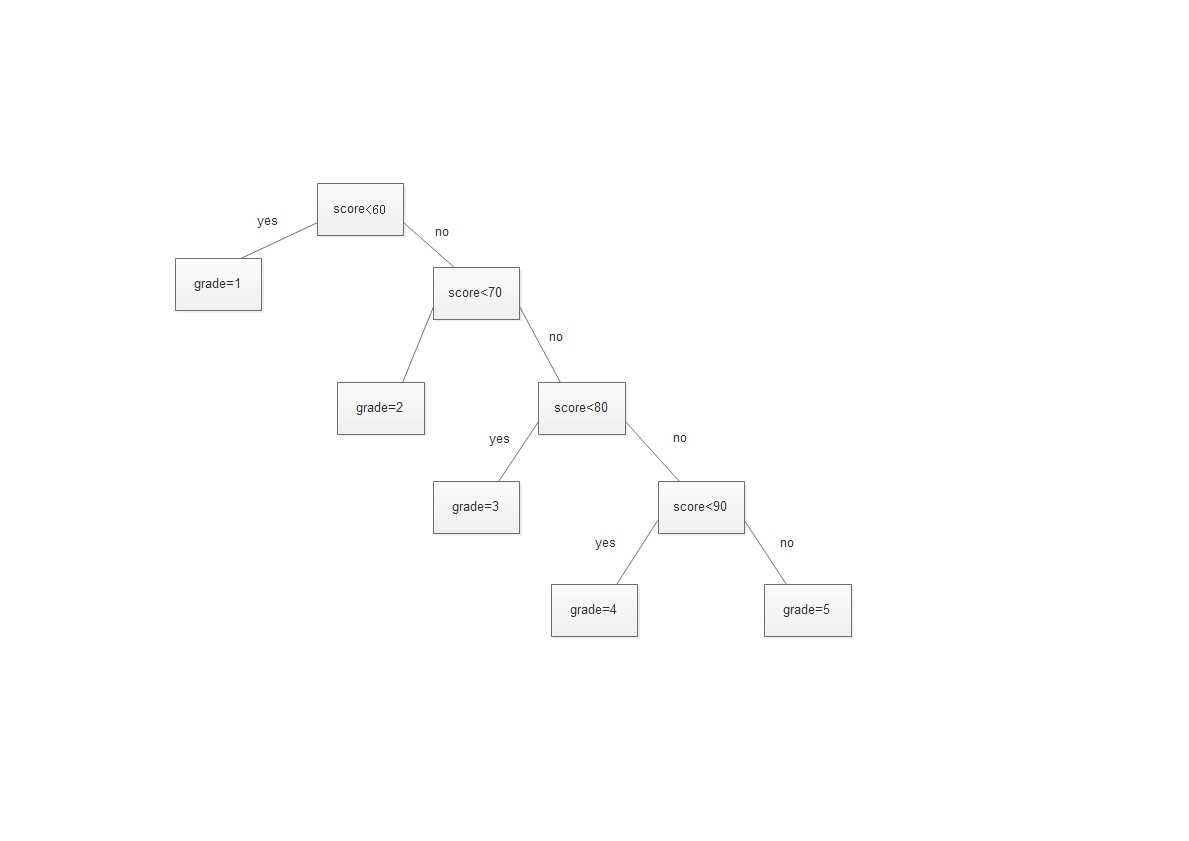 我们发现,在这个判断树中,60分以下的需要查找一次,60-69的需要查找两次
我们发现,在这个判断树中,60分以下的需要查找一次,60-69的需要查找两次
70-79需要查找三次,80-89的需要查找四次,90以上的需要查找五次
如果全部的分数集中在70—80之间,那么这棵树就不够优化。
如果我们考虑学生的成绩分布情况,如下表所示:
|
分数段 |
0-59 |
60-69 |
70-79 |
80-89 |
90以上 |
|
比例 |
0.05 |
0.15 |
0.40 |
0.30 |
0.10 |
根据上面的判断树和学生成绩的分布情况,那么我们计算平均的查找效率:
0.05*1+0.15*2+0.40*3+0.30*4+0.10*4=3.15
如何我们重新设计程序,让频率高优先判定,那么就会减少判定的次数,我们重新设计判断程序和判断树
if(score<80){
if(score<70){
if(score<60){
grade=1;
}else{
grade=2;
}
}else{
grade=3;
}
}else{
if(score<90){
grade=4;
}else{
grade=5;
}
}
这样的判断树就如下所示:
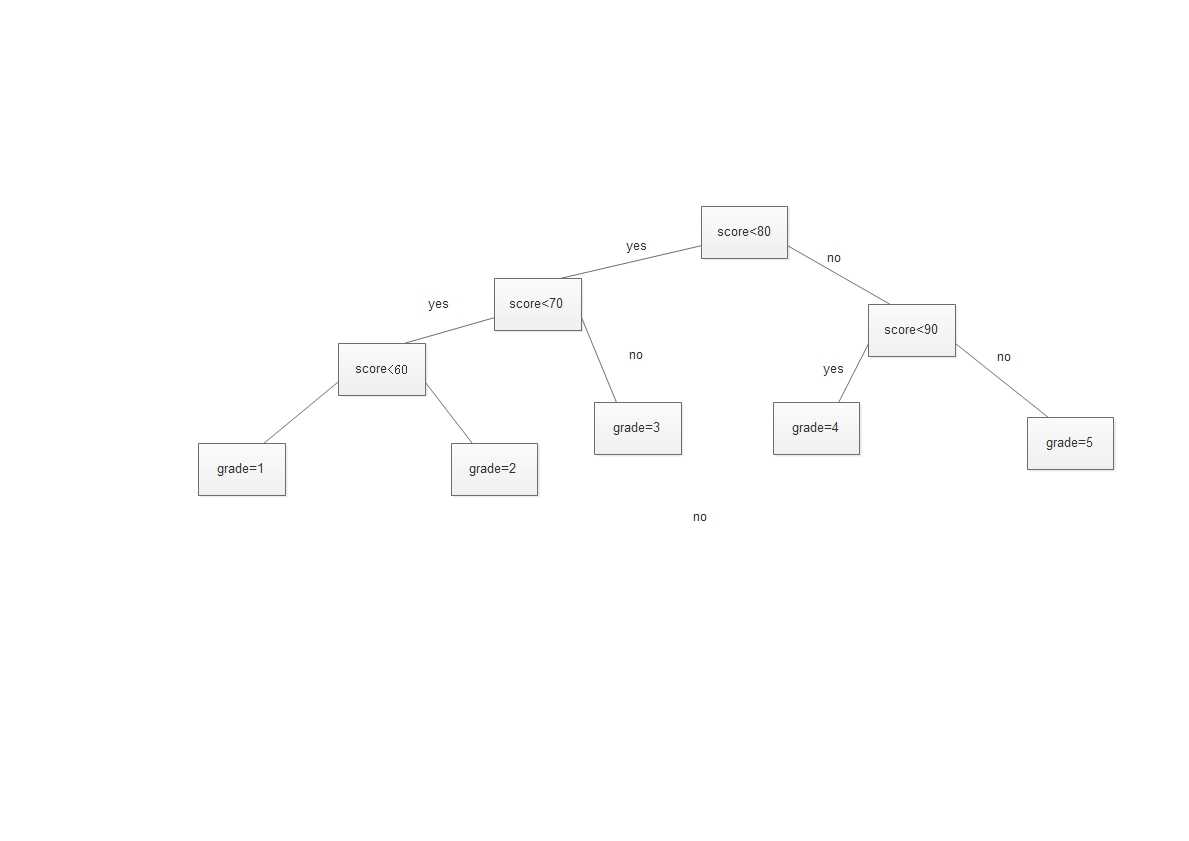
|
分数段 |
0-59 |
60-69 |
70-79 |
80-89 |
90以上 |
|
比例 |
0.05 |
0.15 |
0.40 |
0.30 |
0.10 |
那么我们再根据判断树和分数的频率来计算平均查找效率:
0.05*3+0.15*3+0.4*2+0.3*2+0.10*2=2.2
平均查找效率明星变高了。
思考:如果根据节点的频率不同,构造更高效率的搜索树
定义:带权路径长度(WPL):设二叉树有n个叶子节点,每个节点带有权值,从根节点到每个叶子节点的长度为,则每个叶子的带权路径之和为
最优二叉树或者哈夫曼数:WPL值最小
现有五个叶子节点,他们的权值为{1,2,3,4,5},用此权值序列可以构造多个不同形状的二叉树。
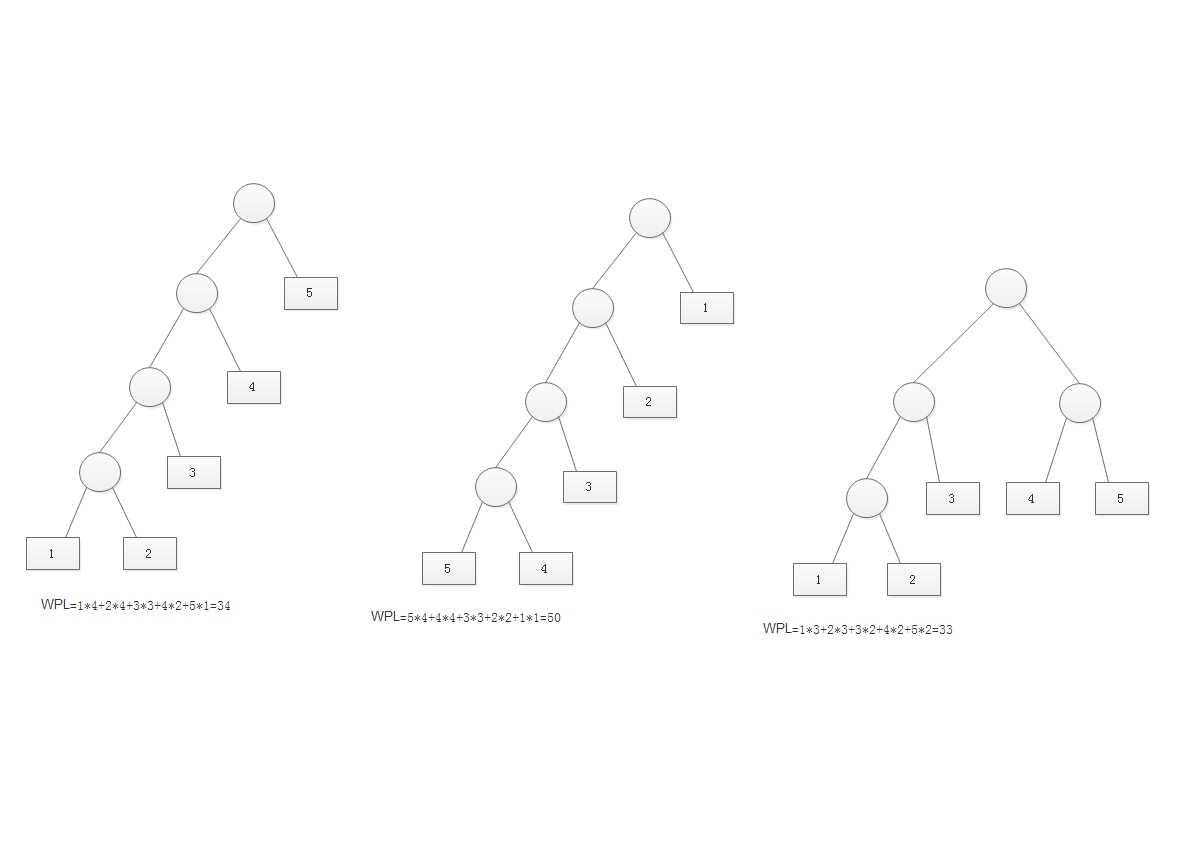
给定一段字符串,如何对字符进行编码,可以使得该字符串的
存储空间最少?
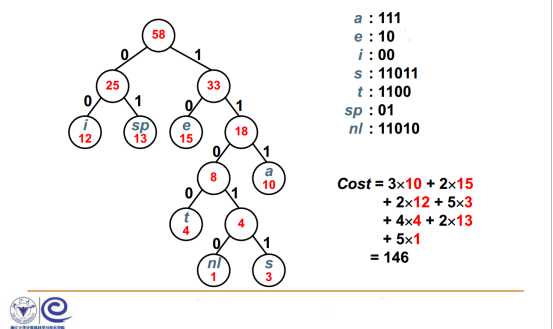
[例] 假设有一段文本,包含58个字符,并由以下7个字符构: a,
s, t,空格( sp),换行( nl);这7个字符出现的次数不同。如
这7个字符进行编码,使得总编码空间最少?
【 分析】
( 1)用等长ASCII编码: 58 ×8 = 464位;
( 2)用等长3位编码: 58 ×3 = 174位;
( 3)不等长编码:出现频率高的字符用的编码短些,出现频率低
的字符则可以编码长些?
例如:
a:1
e:0
s:10
t:11
那么1011是什么编码
aeza:1101
aet:1101
st:1011
这样就产生了编码的二义性。
那么如何避免二义性呢?使用前缀码
前缀码(prefix code):任何字符的编码都不是另一个字符编码的前缀,就可以无二义的解码
使用二叉树进行编码:
a):左右分支表示0,1
b)字符只在叶子节点上
四个字符的频率:
a:4,u:1,x:2,z:1
那么我们可以使用二叉树进行编码
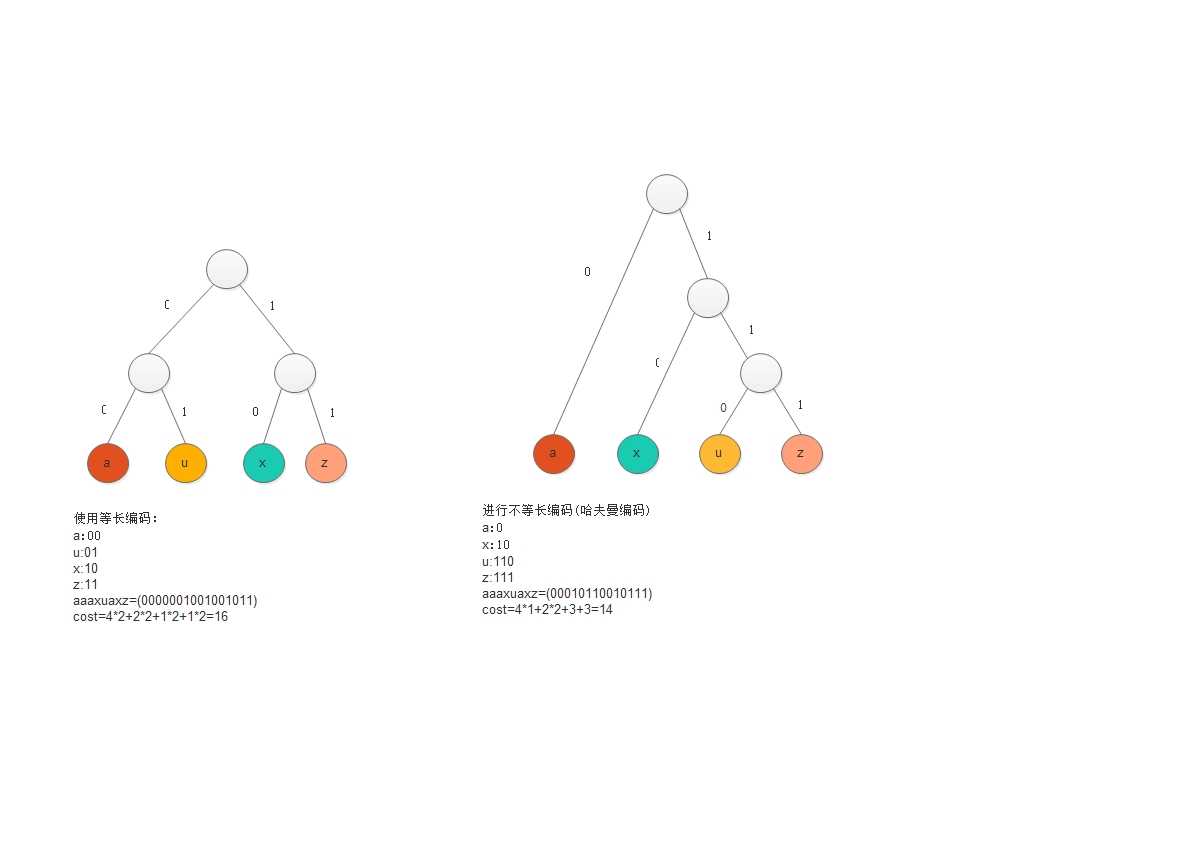
可以看出,使用二叉树进行哈夫曼编码可以减少编码的总长度
该例子出自于:慕课浙江大学数据结构陈越老师何钦铭老师
需求:

二叉树的哈夫曼编码
标签:.com 节点 判断 左右 3.3 mil 哈夫曼树 ade 之间
原文地址:http://www.cnblogs.com/yghjava/p/6751582.html