标签:一对多 持久化 tom delete ann ota java 查询语句 retrieve
关联关系中的CRUD_Cascade_Fetch
1. hibernate_1700_one2many_many2one_bi_crud
2. 设定 cascade 可以设定在持久化时对于关联对象的操作(CUD,R归Fetch管)
3. cascade 仅仅是帮我们省了编程的麻烦而已,不要把它的作用看的太大
a) Cascade 的属性指明做什么操作的时候关联对象是绑在一起的
b) Merge = save + update
c) refresh = A 里面需要度 B 改过之后的数据
4. 铁律:双向关系在程序中要设定双向关联
5. 铁律:双向 mappedBy
6. fetch
a) 铁律:双向不要两边设置 eager(会有多余的查询语句发出)
b) 对多方设置 fetch 的时候要谨慎,结合具体应用,一般用 Lazy 不用 eager,特殊情况(多方数量不多的时候可以考虑,提高效率的时候可以考虑)
7. O/R Mapping 编程模型
a) 映射模型
i. jpa annotation
ii. hibernate annotation extension
iii. hibernate xml
iiii.jpa xml
b) 编程接口
i. jpa 的编程接口
ii. hibernate 的编程接口
c) 数据查询语言
i. HQL
ii. EJBQL(JPQL)
8. 要想删除或者更新,先做 load,出了精确知道 ID 之外
9. 如果象消除关联关系,先设定关系为 null,再删除对应记录,如果不删记录,该记录就变成垃圾数据
关系映射总结
1. 什么样的关系,设计什么样的表,进行什么样的映射
5. CRUD,按照自然的理解即可(动手测试)
以多对一为例:多个用户(User)对应一个组(Group)
User:

1 package com.bjsxt.hibernate; 2 3 import javax.persistence.Entity; 4 import javax.persistence.GeneratedValue; 5 import javax.persistence.Id; 6 import javax.persistence.JoinColumn; 7 import javax.persistence.ManyToOne; 8 import javax.persistence.Table; 9 10 @Entity 11 @Table(name="t_user") 12 public class User { 13 private Integer id; 14 15 private String name; 16 17 private Group group; 18 19 @Id 20 @GeneratedValue 21 public Integer getId() { 22 return id; 23 } 24 25 public void setId(Integer id) { 26 this.id = id; 27 } 28 29 public String getName() { 30 return name; 31 } 32 33 public void setName(String name) { 34 this.name = name; 35 } 36 37 @ManyToOne 38 @JoinColumn(name="group_ID") 39 public Group getGroup() { 40 return group; 41 } 42 43 public void setGroup(Group group) { 44 this.group = group; 45 } 46 }
Group:
1 package com.bjsxt.hibernate; 2 3 import java.util.HashSet; 4 import java.util.Set; 5 6 import javax.persistence.Entity; 7 import javax.persistence.GeneratedValue; 8 import javax.persistence.Id; 9 import javax.persistence.OneToMany; 10 import javax.persistence.Table; 11 12 @Entity 13 @Table(name="t_group") 14 public class Group { 15 private Integer id; 16 17 private String name; 18 19 private Set<User> users = new HashSet<User>(); 20 21 @Id 22 @GeneratedValue 23 public Integer getId() { 24 return id; 25 } 26 27 public void setId(Integer id) { 28 this.id = id; 29 } 30 31 public String getName() { 32 return name; 33 } 34 35 public void setName(String name) { 36 this.name = name; 37 } 38 39 @OneToMany(mappedBy="group") 40 public Set<User> getUsers() { 41 return users; 42 } 43 44 public void setUsers(Set<User> users) { 45 this.users = users; 46 } 47 }
保存顺序:逐个保存
1 @Test 2 public void testSaveUser(){ 3 User u = new User(); 4 u.setName("u1"); 5 Group g = new Group(); 6 g.setName("g1"); 7 u.setGroup(g); 8 Session session = sf.getCurrentSession(); 9 session.beginTransaction(); 10 session.save(g); 11 session.save(u); 12 session.getTransaction().commit(); 13 }
如果希望在保存 u 的时候顺带保存 g,则需要在User中设置 Cascade:
1 @ManyToOne(cascade=CascadeType.ALL) 2 @JoinColumn(name="group_ID") 3 public Group getGroup() { 4 return group; 5 }
然后再进行保存的代码:
1 @Test 2 public void testSaveUser(){ 3 User u = new User(); 4 u.setName("u1"); 5 Group g = new Group(); 6 g.setName("g1"); 7 u.setGroup(g); 8 Session session = sf.getCurrentSession(); 9 session.beginTransaction(); 10 // session.save(g); 11 session.save(u); 12 session.getTransaction().commit(); 13 }
设置Casecade的目的就是为了级联保存,如果嫌麻烦,就理清关系逐个保存就行了。
CRUD 操作:
C:Create 新增;
R:Retrieve 检索;
U:Update 更新;
D:Delete 删除。
cascade 负责 CUD(新增、修改、删除),fetch 负责 R(检索)。
用正常人的思维进行思考,然后再通过做实验验证,不要死记硬背。
查询多的一方(User),会自动带出一的一方(Group):
OneToMany 默认是 fetch=FetchType.LAZY
ManyToOne 默认是 fetch=FetchType.EAGER
@Test public void testGetUser(){ testSaveUser(); Session session = sf.getCurrentSession(); session.beginTransaction(); User u = (User) session.load(User.class, 1); System.out.println(u.getGroup().getName()); session.getTransaction().commit(); }
查询一的一方(Group),不会带出多的一方(User),因为这会导致非常严重的性能问题,hibernate也是根据这个思路设计的:
@Test public void testGetGroup(){ testSaveUser(); Session session = sf.getCurrentSession(); session.beginTransaction(); Group g = (Group) session.get(Group.class, 1); session.getTransaction().commit(); for(User u : g.getUsers()){ System.out.println(u.getName()); }
如果非要在查询一的一方的时候带出多的一方,需要在一的一方配置fetch注解:
FetchType 有两个值:
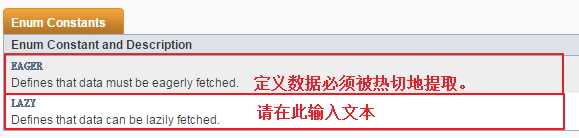
@OneToMany(mappedBy="group", cascade={CascadeType.ALL}, fetch=FetchType.EAGER ) public Set<User> getUsers() { return users; }
这样hibernate就会发出联合查询的sql语句了。
如果多对一和一对多都设置了fetchType=FetchType.EAGER,层次比较深的话,有时查询一行需要关联到很多查询,不利于效率。但有时也需要查询出所有将其放置到hibernate的缓存之中,这个需要根据实际的业务需要。
jar包链接: https://pan.baidu.com/s/1eSf3G1k 密码: bpxb
代码链接: https://pan.baidu.com/s/1cw6N5k 密码: 43im
标签:一对多 持久化 tom delete ann ota java 查询语句 retrieve
原文地址:http://www.cnblogs.com/ShawnYang/p/6755079.html
