Californium 是一款基于Java实现的Coap技术框架,该项目实现了Coap协议的各种请求响应定义,支持CON/NON不同的可靠性传输模式。
Californium 基于分层设计且高度可扩展,其内部模块设计及接口定义存在许多学习之处;
值得一提的是,在同类型的 Coap技术实现中,Californium的性能表现是比较突出的,如下图: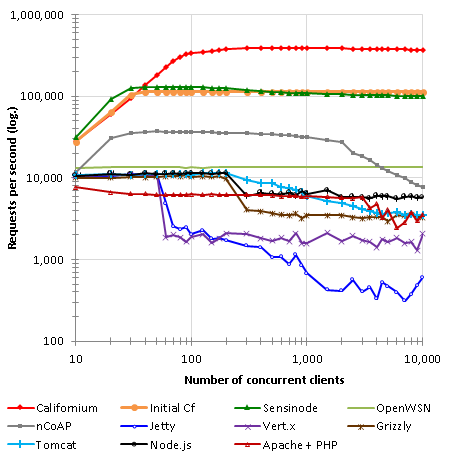
更多的数据可以参考Californium-可扩展云服务白皮书
本文以框架的源码分析为主,其他内容不做展开。
目前Californium 项目稳定版本为 2.0.0-M2,项目的托管地址在:
https://github.com/eclipse/californium
~.californium-core
californium 核心模块,定义了一系列协议栈核心接口,并提供了Coap协议栈的完整实现,
~.element-connector
从core模块剥离的连接器模块,用于抽象网络传输层的接口,使得coap可以同时运行于udp和tcp多种传输协议之上;
~.scandium-core
Coap over DTLS 支持模块,提供了DTLS 传输的Connector实现;
~.californium-osgi
californium 的osgi 封装模块;
~.californium-proxy
coap 代理模块,用于支持coap2coap、coap2http、http2coap的转换;
~.demo-xxx
样例程序;
其中,californium-core和element-connector是coap技术实现最关键的模块,后面的分析将围绕这两个模块进行。
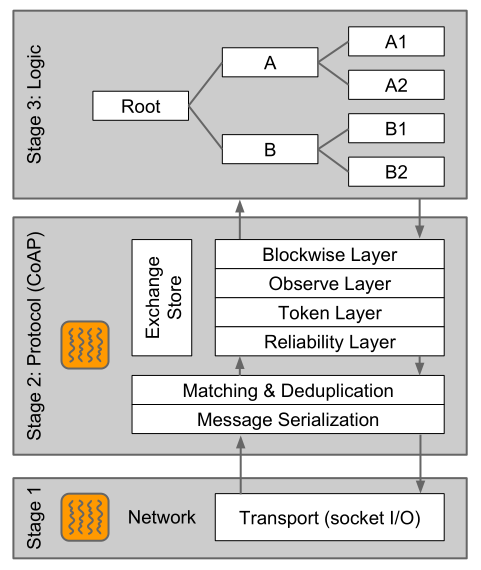
Californiium 定义了三层架构:
1 网络层,负责处理端口监听,网络数据收发;
2 协议层,负责Coap协议数据包解析及封装,实现消息的路由、可靠性传输、Token处理、观察者模型等等;
3 逻辑层,负责 Resource定义和映射,一个Resource 对应一个URL,可独立实现Coap 请求处理。
三层架构中都可以支持独立的线程池,其中网络层与协议层的线程池保持独立;
逻辑层可为每个Resource指定独立的线程池,并支持父级继承的机制,即当前Resource若没有定义则沿用父级Resource线程池;
若逻辑层未指定线程池,则默认使用协议层的线程池。
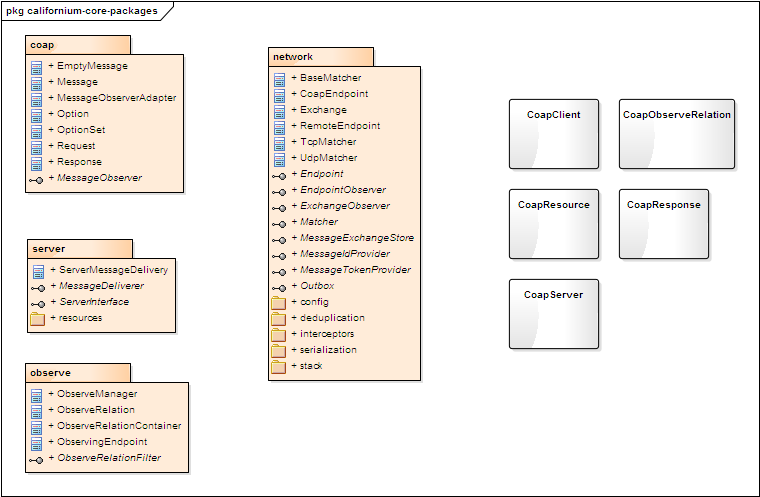
core 模块定义了协议栈相关的所有关键接口,根据功能职责的不同拆分为多个子 package;
根级 package定义的是Coap应用的一些入口类,如Client/Server实现、包括应用层CoapResource的定义。
实现 coap协议 RFC7252 实体定义,包括消息类型、消息头、Observe机制等。
具体定义见下图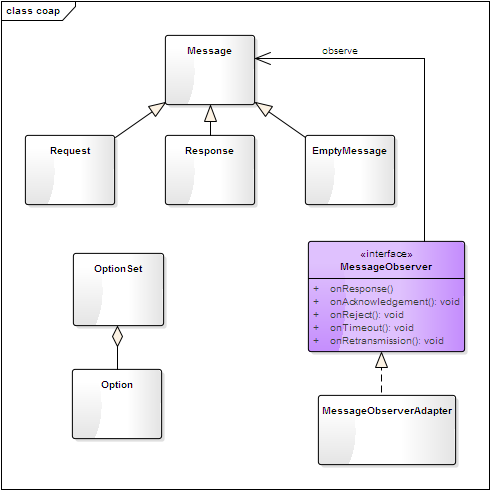
Coap 消息划分为Request/Response/EmptyMessage 三类;
MessageObserver 接口用于实现消息的状态跟踪,如重传、确认等。
network 是协议栈核心机制实现的关键模块,其涵盖了网络传输及协议层的定义及实现;
模块实现了一些关键接口定义,如将网络传输端点抽象为Endpoint,根据请求响应的关联模型定义了Exchange等。
协议栈的分层定义、消息编解码、拦截处理也由network包提供。
endpoins定义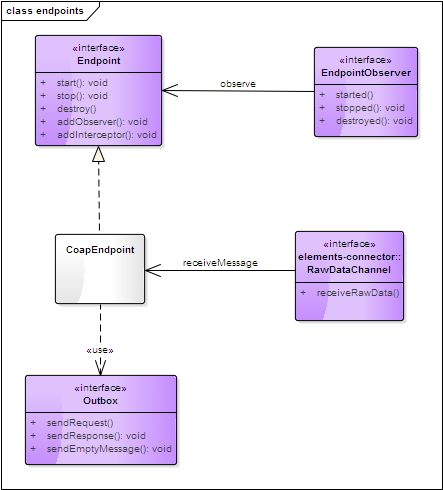
Endpoint 定义为一个端点,通常与一个IP和端口对应,其屏蔽了client和server交互时的网络传输细节。
对于client来说,Endpoint代表通讯的服务端地址端口;而对于server来说则代表了绑定监听的地址及端口。
CoapEndpoint实现了Endpoint接口,通过RawDataChannel(见elements-connector部分)接口实现消息接收,通过Outbox接口实现消息发送。
通常CoapEndpoint 会关联一个Connector,以实现传输层的收发;
CoapStack对应了协议栈接口,用于处理CoapEndpoint上层的消息链路;
除此之外,CoapEndpoint 还应该包括消息编解码、拦截处理等功能。
exchange定义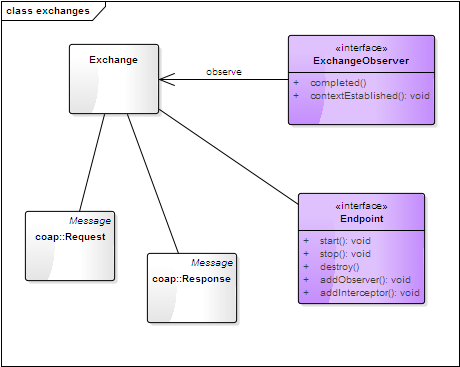
Exchange描述了请求-响应模型,一个Exchange会对应一个Request,相应的Response,以及当前的Endpoint;
ExchangeObserver用于实现对Exchange状态的变更监听;
Exchange 通常存在于两种场景:
1 发送请求后初始化并存储,当接收到对应的响应之后变更为completed(执行清理工作)。
2 接收请求后初始化并存储,当发送响应时执行清理;
matcher定义
Matcher 是用于实现Exchange 生成及销毁的模块,提供了几个收发接口;
用于消息在进入协议栈CoapStack处理之前完成配对处理;
messagetool定义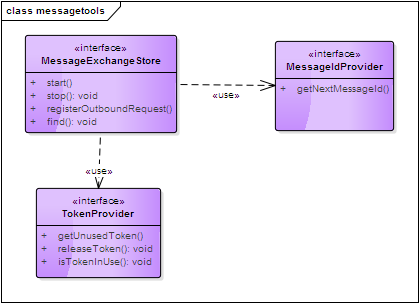
MessageExchangeStore 实现了Exchange的查询、存储;
MessageIdProvider 用于提供Coap消息的MID,一个MID代表了一个唯一的消息(在消息生命周期内);
TokenProvider 用于提供Coap消息的Token,而Request及Response通过Token实现匹配;
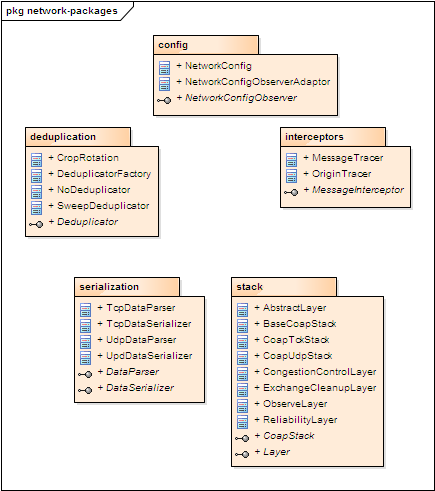
package-config
提供网络参数配置定义
package-deduplication
提供消息去重机制的实现
package-interceptors
提供消息传输拦截器定义
package-serialization
提供消息包的解析及编码实现
package-stack
提供协议栈分层定义及实现
应用层 server端实现的一些定义,包括Server接口、Resource定义。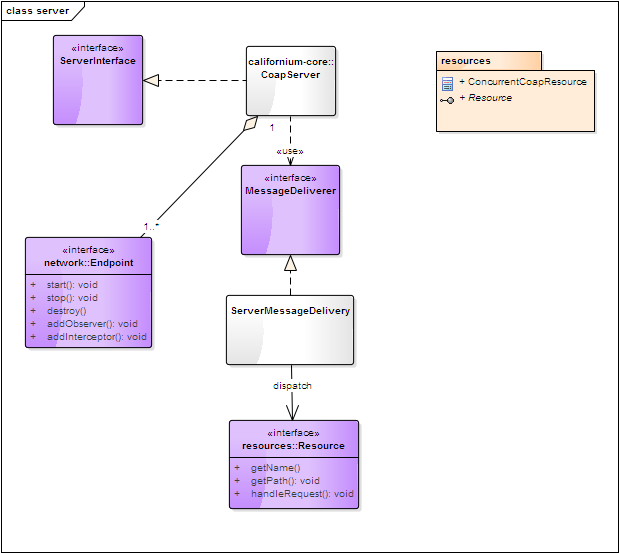
CoapServer 可包含多个Endpoint,体现为一个Coap服务可架设在多个传输端口之上;
MessageDeliverer 是消息路由的接口,ServerMessageDelivery 实现了根据uri 查找Resource的功能;
ConcurrentCoapResource则为Resource 提供了一个独立线程池的执行方式。
应用层 observe机制的定义,如下图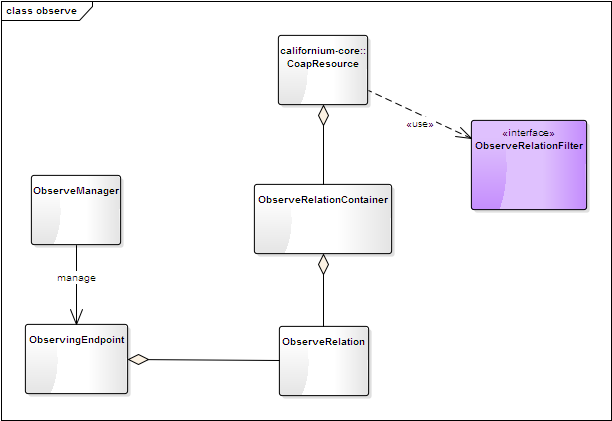
ObserveRelation 定义一个观察关系,对应一个观察者即观察目标Resource;
ObserveEndpoint 定义了一个观察者端点,并包含一个关系列表(一个观察者可以观察多个Resource);
ObserveManager 由CoapServer持有,用于管理观察者端点列表;
CoapResource 也会持有一个Relation集合以实现跟踪;其通过ObserveRelationFilter接口决定是否接受来自观察者的注册请求;
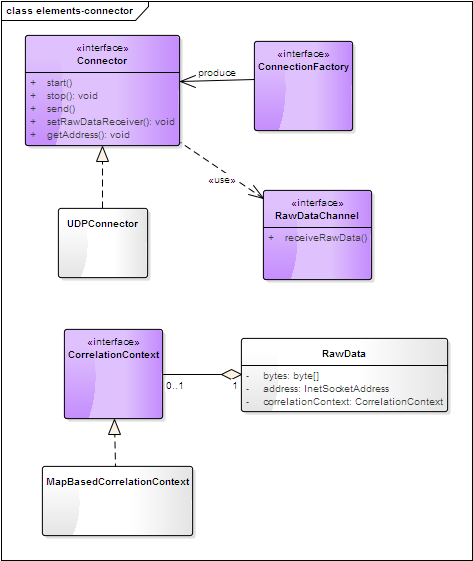
connector 模块由core模块剥离,用于实现网络传输层的抽象,这使得Coap协议可以运行于UDP、TCP、DTLS等多种协议之上。
Connector定义了连接器需实现的相关方法,包括启动停止、数据的收发;
RawData包含了网络消息包的原始字节数据,其解析和编码需要交由上层协议实现;
CorrelationContext 描述了上下文,用于支持传输协议的一些会话数据读写,如DTLS会话。
下面拟用一张关系图概括Californium 框架的全貌(部分内容未体现):
与分层设计对应,框架分为 transport 传输层、protocol 协议层、logic 逻辑层。
transport 传输层,由Connector 提供传输端口的抽象,UDPConnector是其主要实现;
数据包通过RawData对象封装;该层还提供了CorrelationContext 实现传输层会话数据的读写支持。
protocol 协议层,提供了Coap 协议栈机制的完整实现;CoapEndpoint是核心的操作类,数据的编解码通过
DataSerializer、DataParser实现,MessageInterceptor提供了消息收发的拦截功能,Request/Response的映射处理
由 Matcher实现,Exchange 描述了映射模型;协议栈CoapStack 是一个分层的内核实现,在这里完成分块、重传等机制。
logic 逻辑层,定义了CoapClient、CoapServer的入口,包括消息的路由机制,Resource的继承机制;
Observe机制的关系维护、状态管理由ObserveManager提供入口。
californium-core 采用了分层接口来定义协议栈,其中CoapStack 描述整个栈对象,Layer则对应分层的处理;
这相当于采用了过滤器模式,分层的定义使得特性间互不影响,子模块可保持独立的关注点;
CoapStack定义如下:
public interface CoapStack { // delegate to top
void sendRequest(Request request); // delegate to top
void sendResponse(Exchange exchange, Response response);
... // delegate to bottom
void receiveRequest(Exchange exchange, Request request); // delegate to bottom
void receiveResponse(Exchange exchange, Response response);接口包括了几个消息收发函数,而Layer也定义了一样的接口。
一个CoapUdpStack 包括的分层如下图: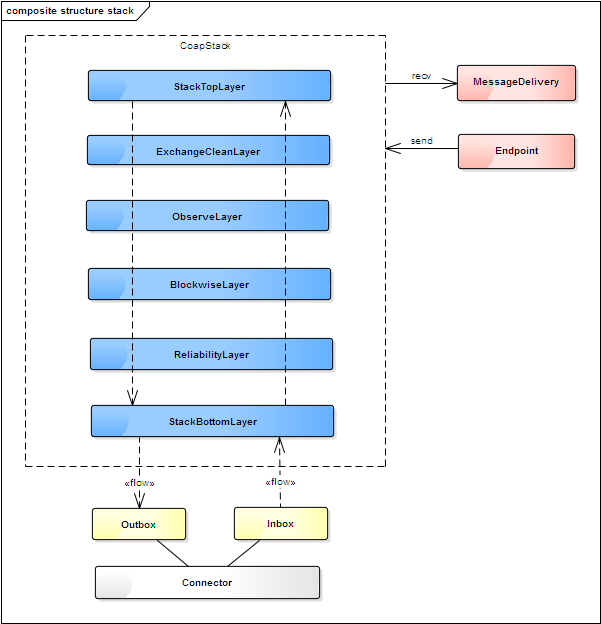
CoapUdpStack 构造函数与此对应:
public CoapUdpStack(final NetworkConfig config, final Outbox outbox) {
...
Layer layers[] = new Layer[] { new ExchangeCleanupLayer(), new ObserveLayer(config), new BlockwiseLayer(config),
reliabilityLayer };
setLayers(layers);
}StackTopLayer和StackBottomLayer由基础类BaseCoapStack提供,实现了协议栈顶层和底层逻辑;
MessageDeliver是胶合应用层的接口,其从StackTopLayer收到Coap消息之后将继续分发到Resource;
StackBottomLayer则胶合了传输层,通过Inbox/Outbox接口实现与Connector的交互。
其他Layer的功能
ExchangeCleanLayer 提供Exchange清理功能,当取消请求时触发Exchange的清理功能;
ObserveLayer 提供Coap Observe机制实现;
BlockwiseLayer 提供Coap 分块传输机制实现;
ReliabilityLayer 提供可靠性传输,实现自动重传机制;
Exchange对应于请求/响应模型,其生命周期也由交互模型决定,一般在响应结束之后Exchange便不再存活;
然而在Observe场景下例外,一旦启动了Observe请求,Exchange会一直存活直到Observe被取消或中断。
1 LocalExchange,即本地的Exchange, 对应于本地请求对方响应的交互。
BaseCoapStack.StackTopLayer实现了初始化:
public void sendRequest(final Request request) {
Exchange exchange = new Exchange(request, Origin.LOCAL);
...当接收响应时进行销毁,observe类型的请求在这里被忽略:
public void receiveResponse(final Exchange exchange, final Response response) { if (!response.getOptions().hasObserve()) {
exchange.setComplete();
}UdpMatcher 实现了销毁动作:
UdpMatcher-- public void sendRequest(final Exchange exchange, final Request request) {
exchange.setObserver(exchangeObserver);
exchangeStore.registerOutboundRequest(exchange); if (LOGGER.isLoggable(Level.FINER)) {这是在发送请求时为Exchange添加观察者接口,当exchange执行complete操作时触发具体的销毁工作:
UdpMatcher.ExchangeObserverImpl-- if (exchange.getOrigin() == Origin.LOCAL) { // this endpoint created the Exchange by issuing a request
KeyMID idByMID = KeyMID.fromOutboundMessage(exchange.getCurrentRequest());
KeyToken idByToken = KeyToken.fromOutboundMessage(exchange.getCurrentRequest());
exchangeStore.remove(idByToken); // in case an empty ACK was lost
exchangeStore.remove(idByMID);
...值得一说的是,californium大量采用了观察者设计模式,这种方法在设计异步消息机制时非常有用.
此外,request的取消、中断操作(RST信号)、传输的超时都会导致exchange生命周期结束。
LocalExchange的生命周期如下图:
2 RemoteExchange,即远程的Exchange,对应于本地接收请求并返回响应的交互。
UdpMatcher实现了远程Exchange的初始化:
UdpMatcher-- public Exchange receiveRequest(final Request request) {
...
KeyMID idByMID = KeyMID.fromInboundMessage(request); if (!request.getOptions().hasBlock1() && !request.getOptions().hasBlock2()) {
Exchange exchange = new Exchange(request, Origin.REMOTE);
Exchange previous = exchangeStore.findPrevious(idByMID, exchange); if (previous == null) {
exchange.setObserver(exchangeObserver);
...在发送响应时,Exchange被销毁,仍然由UdpMatcher实现:
UdpMatcher-- public void sendResponse(final Exchange exchange, final Response response) {
response.setToken(exchange.getCurrentRequest().getToken());
... // Only CONs and Observe keep the exchange active (CoAP server side)
if (response.getType() != Type.CON && response.isLast()) {
exchange.setComplete();
}注意到这里对response进行了last属性的判断,该属性默认为true,而ObserveLayer将其置为false,使得observe响应不会导致Exchange结束:
ObserveLayer-- public void sendResponse(final Exchange exchange, Response response) {
...
response.setLast(false);连接中断(RST信号)、传输超时会导致Exchange的结束,此外由客户端发起的observe取消请求也会产生一样的结果。
RemoteExchange的生命周期如下图所示: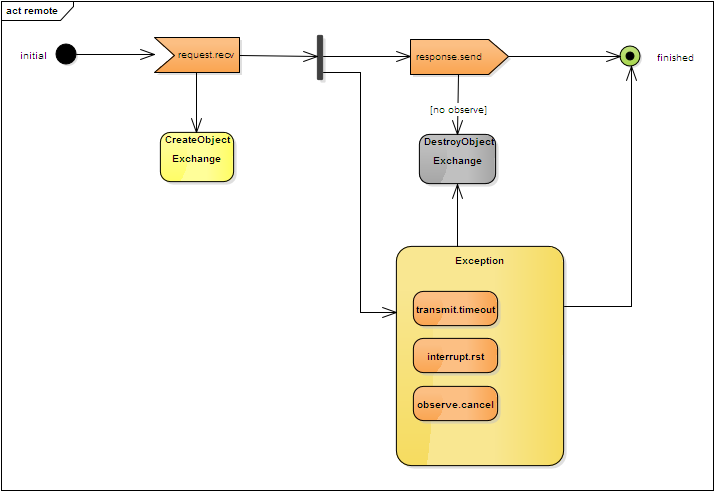
分块传输一般用于发送较大的请求体或接受较大的响应体,比如上传下载固件包场景,由于受到MTU的限制,需要实现分块传输;
Coap定义了分块传输的方式,采用Block1/Block2机制
Option选项
BlockOption是用于描述分块信息的选项类型,选项值为0-3个字节,编码包含了3个字段:当前分块编号;是否结束;当前分块大小。
为区分请求和响应的不同,分别有block1和block2 两个选项:
block1:用于发送POST/PUT请求时传输较大的内容体;
block2:用于响应GET/POST/PUT请求时传输较大的内容体;
size1:指示请求体的总大小;
size2:指示响应体的总大小;
配置选项
maxMessageSize:消息大小阈值,当发送的消息大于该阈值时需采用分块传输,该值必须小于MTU;
preferredBlockSize:用于指示分块的大小;
maxResourceBodySize:最大资源内容体大小,用于限制接收的请求或响应的总大小,若超过将提示错误或取消处理;
blockLifeTime:分块传输的生命周期时长,若超过该时长分块传输未完成则视为失败;
BlockwiseLayer实现了分块传输的完整逻辑,其中sendRequest的代码片段:
public void sendRequest(final Exchange exchange, final Request request) {
BlockOption block2 = request.getOptions().getBlock2(); if (block2 != null && block2.getNum() > 0) { //应用层指定的分块..
} else if (requiresBlockwise(request)) { //自动计算分块
startBlockwiseUpload(exchange, request);
} else { //不需要分块
exchange.setCurrentRequest(request);
lower().sendRequest(exchange, request);
}
}
...//实现分块阈值判断private boolean requiresBlockwise(final Request request) { boolean blockwiseRequired = false; if (request.getCode() == Code.PUT || request.getCode() == Code.POST) {
blockwiseRequired = request.getPayloadSize() > maxMessageSize;
}
...//startBlockwiseUpload实现了request分块逻辑,通过在请求的Option中加入Block1作为标识private void startBlockwiseUpload(final Exchange exchange, final Request request) {
BlockwiseStatus status = findRequestBlockStatus(exchange, request); final Request block = getNextRequestBlock(request, status);
block.getOptions().setSize1(request.getPayloadSize());
...
lower().sendRequest(exchange, block);
}接收端检测Request的Block1选项,返回continue响应码,直到所有分块传输完成后进行组装交由上层处理:
private void handleInboundBlockwiseUpload(final BlockOption block1, final Exchange exchange, final Request request) {
//检查是否超过限制 if (requestExceedsMaxBodySize(request)) {
Response error = Response.createResponse(request, ResponseCode.REQUEST_ENTITY_TOO_LARGE);
error.setPayload(String.format("body too large, can process %d bytes max", maxResourceBodySize));
error.getOptions().setSize1(maxResourceBodySize);
lower().sendResponse(exchange, error);
} else {
... if (block1.getNum() == status.getCurrentNum()) { if (status.hasContentFormat(request.getOptions().getContentFormat())) { status.addBlock(request.getPayload()); status.setCurrentNum(status.getCurrentNum() + 1);
if ( block1.isM() ) {
//存在后面的block,返回Continue响应
Response piggybacked = Response.createResponse(request, ResponseCode.CONTINUE);
piggybacked.getOptions().setBlock1(block1.getSzx(), true, block1.getNum());
piggybacked.setLast(false);
exchange.setCurrentResponse(piggybacked);
lower().sendResponse(exchange, piggybacked);
} else {
...
//已经完成,组装后交由上层处理
Request assembled = new Request(request.getCode());
assembled.setSenderIdentity(request.getSenderIdentity());
assembleMessage(status, assembled);
upper().receiveRequest(exchange, assembled);
}因此,一个请求体分块传输流程如下图所示: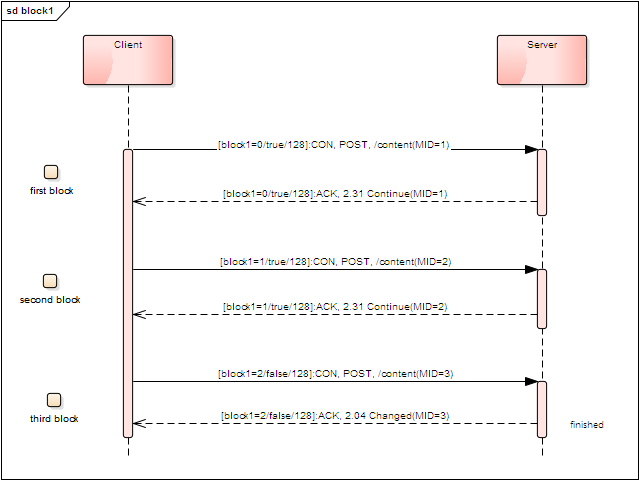
响应体分块传输的逻辑与此类似,交互流程如下图: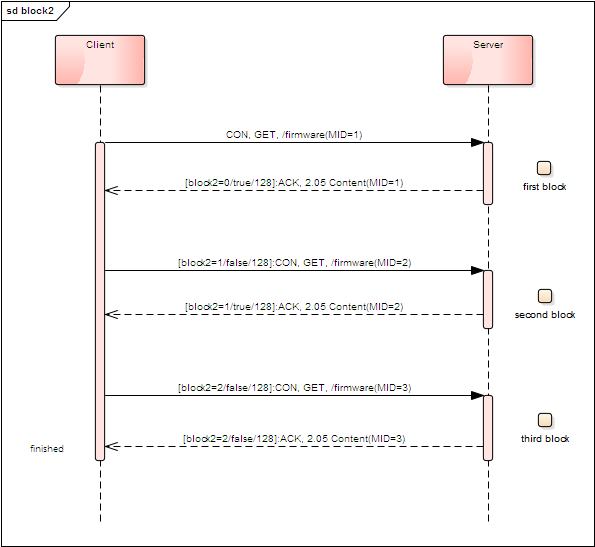
Coap消息支持重传机制,当发送CON类型的消息时,要求接收端响应对应的ACK消息;如果在指定时间内没有收到响应,则进行重传。
基础消息重传由ReliabilityLayer实现,sendRequest 代码片段:
if (request.getType() == null) {
request.setType(Type.CON);
} if (request.getType() == Type.CON) {
prepareRetransmission(exchange, new RetransmissionTask(exchange, request) { public void retransmit() {
sendRequest(exchange, request);
}
});
}
lower().sendRequest(exchange, request);当发送CON类型消息时,通过 prepareRetransmission函数实现重传准备:
int timeout; if (exchange.getFailedTransmissionCount() == 0) {
timeout = getRandomTimeout(ack_timeout, (int) (ack_timeout * ack_random_factor));
} else {
timeout = (int) (ack_timeout_scale * exchange.getCurrentTimeout());
}
exchange.setCurrentTimeout(timeout);
ScheduledFuture<?> f = executor.schedule(task, timeout, TimeUnit.MILLISECONDS);
exchange.setRetransmissionHandle(f);exchange.getFailedTransmissionCount() 返回0 代表第一次传输,采用的超时时间是:
**timeout = random(ack_timeout, act_timeout*ack_random_factor)**
//其中ack_timeout(超时起始值)、ack_random_factor(随机因子)由配置文件提供;
后续的重传时间将由上一次的timeout和ack_timeout_scale系数决定:
timeout = timeout * ack_timeout_scale
当接收ACK时,有必要取消重传处理,看看receiveResponse的实现:
@Override
public void receiveResponse(final Exchange exchange, final Response response) {
exchange.setFailedTransmissionCount(0);
exchange.getCurrentRequest().setAcknowledged(true);
exchange.setRetransmissionHandle(null);
...可以看到,接收到响应之后,将Request标记为ack状态,exchange.setRestransmissionHandler会导致上一次的重传schedu任务被取消。
最终重传任务由RetransmissionTask实现:
int failedCount = exchange.getFailedTransmissionCount() + 1;
exchange.setFailedTransmissionCount(failedCount); if (message.isAcknowledged()) { return;
} else if (message.isRejected()) { return;
} else if (message.isCanceled()) { return;
} else if (failedCount <= max_retransmit) {
// Trigger MessageObservers message.retransmitting();
// MessageObserver might have canceled if (!message.isCanceled()) {
retransmit();
}
} else {
exchange.setTimedOut(); message.setTimedOut(true);
}满足重传的条件:
1 消息未被确认(收到ACK)或拒绝(收到RST)
2 消息未被取消;
3 消息未超过重传次数限制;
其中重传次数max_retransmit由配置提供,当超过该次数限制时消息将发生传输超时。
默认参数配置
ack_timeout=2sack_random_factor=1.5ack_timeout_scale=2max_retransmit=4
由于存在重传机制,加上UDP传输的不稳定性,传输两端很可能会受到重复的消息包;
通常重复消息的检测要求实现消息容器以记录和匹配重复消息ID,然而执行时间越长,消息会越来越多,
因此消息容器必须具备清除机制,基于此点不同,californium 提供了两种实现机制:
清除器维持一个消息容器,每个消息都保持一个初始的时间戳;
清除器定时进行扫描,发现太老的消息则将其清除。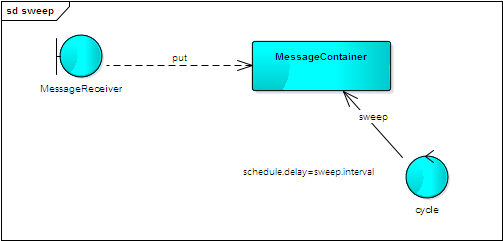
SweepDeduplicator 提供了实现,清除代码片段:
private void sweep() { final long oldestAllowed = System.currentTimeMillis() - exchangeLifetime; final long start = System.currentTimeMillis(); for (Map.Entry<?, Exchange> entry : incomingMessages.entrySet()) {
Exchange exchange = entry.getValue(); if (exchange.getTimestamp() < oldestAllowed) {
incomingMessages.remove(entry.getKey());
}
}
...其中incomingMessage采用了ConcurrentHashMap数据结构,这是一个并发性良好的线程安全集合;
然而从上面的代码也可以发现,sweep在这里是一个遍历操作,定时清除的老化时间默认为247s,假设1s内处理1000条消息,
那么每次清除时驻留的消息数量为247000,即需要遍历这么多的次数,对于CPU来说存在一定的开销。
采用这种方式,消息的存活时间基本上由exchangeLifetime参数和扫描间隔决定。
清除器维持三个消息容器,保持1、2、3三个索引分别指向相应消息容器,其中索引1、2代表了活动的消息容器,
索引3 代表老化的消息容器,如下图所示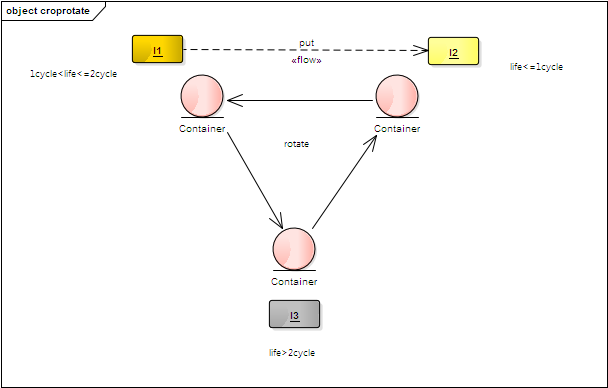
消息索引首次会往 I1容器写入,同时也会往 I2容器存入拷贝;
查找消息时主要从I1 容器查找;
每个周期会执行一次翻转,几个容器指针发生置换(I1->I2,I2->I3,I3->I1),之后I3 指向的容器会被清理;
CropRotation 实现了翻转的逻辑,代码如下:
private void rotation() { synchronized (maps) { int third = first;
first = second;
second = (second+1)%3;
maps[third].clear();
}基于上述的算法分析,I2容器的消息存活时间会小于一个周期,I1容器的消息则存活一个周期到两个周期之间,I3 容器则超过2个周期,是最老的容器;
基于这样的逻辑,翻转清除机制的消息存活时间是1-2个周期之间,而该机制相比标记清除的优点在于清除机制是整个容器一块清除,而不需要遍历操作,然而缺点是增加了存储开销。
JVM的垃圾回收机制也存在类似的设计,相信californium的开发者借鉴了一些思路。
至此,Californium框架的基本全貌已经分析完毕。如果希望对框架有更深入的理解,那么建议你直接在项目中直接使用它,并针对自己感兴趣的几个问题进行源码分析或调试,相信收获会更多。
原文地址:http://hzz333.blog.51cto.com/12844012/1919910