Zookeeper是一个很好的集群管理工具,被大量用于分布式计算。如Hadoop以及Storm系统中。
Apache ZooKeeper是一个为分布式应用所设计开源协调服务,其设计目是为了减轻分布式应用程序所承担的协调任务。可以为用户提供同步、配置管理、分组和命名服务。
在三台装有centos6.5(64位)服务器上安装ZooKeeper,官网建议至少3个节点,本次实验3台
(主机数:3(要求3+,且必须是奇数,因为ZooKeeper选举算法))。
需要提前安装jdk,选择版本是jdk-8u111-linux-x64。
下载ZooKeeper,选择稳定版
解压
$ tar -zxvf zookeeper-3.4.6.tar.gz //将文件移动到/usr/cloud/$ mv zookeeper-3.4.6 /usr/cloud/zookeeper
配置环境变量
# vim /etc/profile//最后一行追加# set zookeeper environmentexport ZOOKEEPER_HOME=/usr/cloud/zookeeperexport PATH=$PATH:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf
使环境变量立即生效$ source /etc/profile
集群部署
在Zookeeper集群环境下只要一半以上的机器正常启动了,那么Zookeeper服务将是可用的。因此,集群上部署Zookeeper最好使用奇数台机器,这样如果有5台机器,只要3台正常工作则服务将正常使用。
下面我们将对Zookeeper的配置文件zoo.cfg的参数进行设置:
$ cd /usr/cloud/zookeeper/conf$ cp zoo_sample.cfg zoo.cfg$ vim zoo.cfg
参数可以参考下图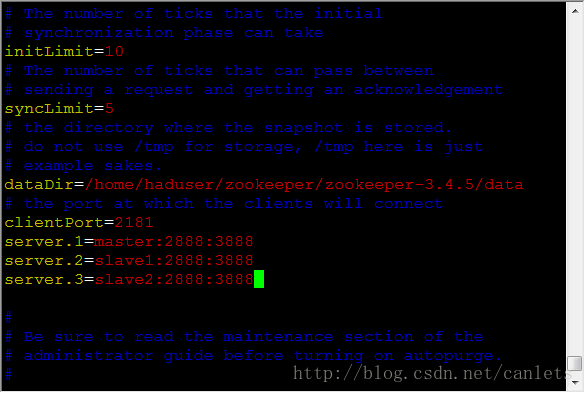
注意上图的配置中master,slave1分别为主机名,具体的对应的主机可参见之前的Hadoop的安装与配置的博文。
在上面的配置文件中server.id=host:port:port中的第一个port是从机器(follower)连接到主机器(leader)的端口号,第二个port是进行leadership选举的端口号。
接下来在dataDir所指定的目录下创建一个文件名为myid的文件,文件中的内容只有一行,为本主机对应的id值,也就是上图中server.id中的id。例如:在服务器1中的myid的内容应该写入1。
参数说明
①tickTime:心跳时间,毫秒为单位。
②initLimit:这个配置项是用来配置 Zookeeper 接受客户端(这里客户端不是用户连接 Zookeeper服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 10 个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 102000=20 秒。
③syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime时间长度,总时间长度就是 5*2000=10 秒。
④dataDir:存储内存中数据库快照的位置。
⑤clientPort:监听客户端连接的端口
⑥server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
dataDir目录下创建myid文件,将内容设置为上⑥中A值,用来标识不同的服务器。
将安装文件复制到其它节点
$ scp -r /home/hadoop/zookeeper hadoop@slave1:/home/hadoop/$ scp -r /home/hadoop/zookeeper hadoop@slave1:/home/hadoop/
修改对应机器上的myid
$ echo "1" > /home/hadoop/zookeeper/data/myid $ cat /home/hadoop/zookeeper/data/myid
在ZooKeeper集群的每个结点上,执行启动ZooKeeper服务的脚本,如下所示:
各节点上启动 (这里启动顺序为master > slave1 > slave2 )
启动顺序:Hadoop——>Zookeeper——>HBase
停止顺序HBase——>Zookeeper——>Hadoop
hadoop@master:/home/hadoop/zookeeper/bin/$ zkServer.sh start hadoop@slave1:/home/hadoop/zookeeper/bin/$ zkServer.sh start hadoop@slave2:/home/hadoop/zookeeper/bin/$ zkServer.sh start
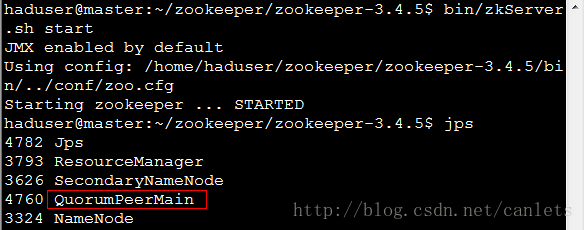
其中,QuorumPeerMain是zookeeper进程,启动正常。
如上依次启动了所有机器上的Zookeeper之后可以通过ZooKeeper的脚本来查看启动状态,包括集群中各个结点的角色(或是Leader,或是Follower),如下所示,是在ZooKeeper集群中的每个结点上查询的结果:
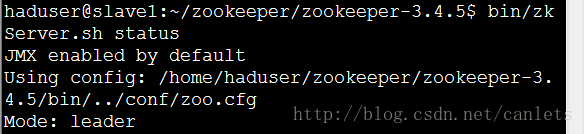
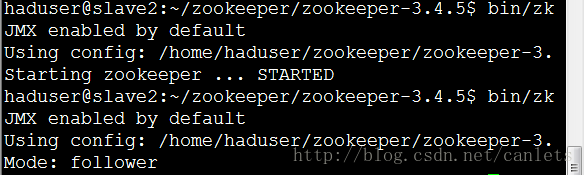
通过上面状态查询结果可见,slave1是集群的Leader,其余的两个结点是Follower。
另外,可以通过客户端脚本,连接到ZooKeeper集群上。对于客户端来说,ZooKeeper是一个整体(ensemble),连接到ZooKeeper集群实际上感觉在独享整个集群的服务,所以,你可以在任何一个结点上建立到服务集群的连接。
$ zkServer.sh stop
Error contacting service. It is probably not running.
网上看了下‘Error contacting service. It is probably not running.‘类错误不外乎3种答案:
1,配置文件zoo.cfg中的datadir文件夹未创建导致
2,防火墙未关闭,建议永久关闭防火墙-->chkconfig iptables of
3,修改sh脚本里的一个nc的参数来解决,可在自己的版本中并没有找到nc的调用。-->nc属于老版本,新版本没有了nc
但是,我的都不是上述问题,我的问题是myid文件配置错误。
myid的文件,文件中的内容只有一行,为本主机对应的id值,也就是上图中server.id中的id
原文地址:http://hzz333.blog.51cto.com/12844012/1919912