标签:blog http java os 使用 io 文件 ar 2014
伪分布模式主要涉及一下的配置信息:
在具体操作前我们先在Hadoop目录下创建几个文件夹:
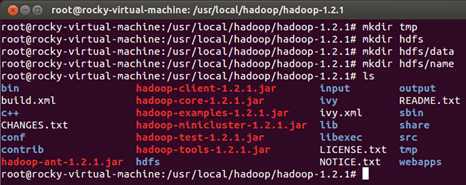
下面开始构建具体的伪分布式的过程并进行测试:
首先配置core-site.xml文件:

进入core-site.xml文件:
配置后文件的内容如下所示:
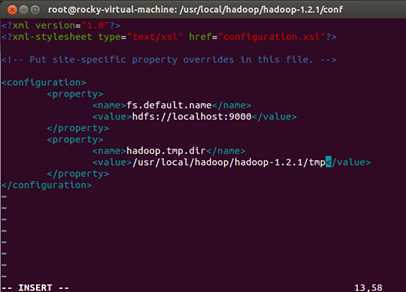
使用“:wq”命令保存并退出。
接下来配置hdfs-site.xml,打开文件:

打开后的文件:
配置后的文件:
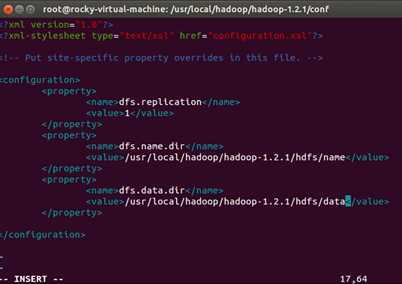
输入“:wq”保存修改信息并退出。
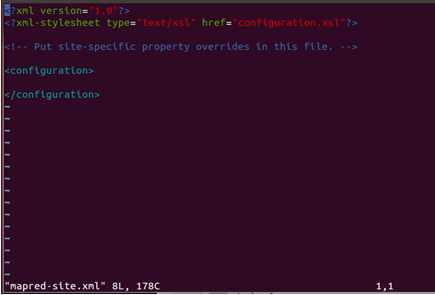
接下来修改mapred-site.xml配置文件:

进入配置文件:
修改后的mapred-site.xml配置文件的内容为:
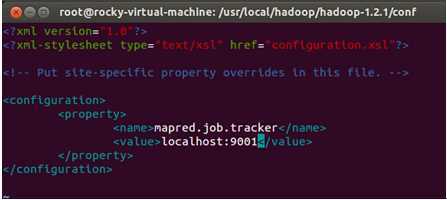
使用“:wq”命令保存并退出。
通过上面的配置,我们完成了最简单的伪分布式配置。
接下来进行hadoop的namenode格式化:
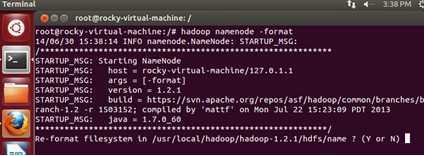
输入“Y”,完成格式化过程:
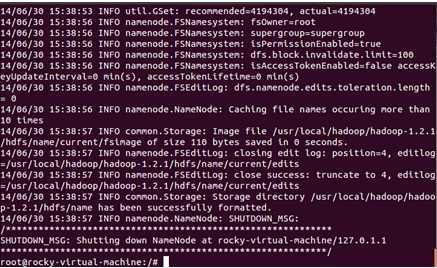
接下来启动Hadoop!
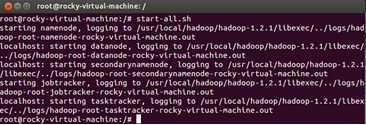
启动Hadoop,如下所示:
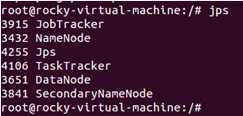
使用java自带的jps命令查询出所有的守护进程:
启动Hadoop!!!
接下来使用Hadoop中用于监控集群状态的Web页面查看Hadoop的运行状况,具体的页面如下:
http://localhost:50030/jobtracker.jsp
http://localhost:50060/tasttracker.jsp
http://localhost:50070/dfshealth.jsp
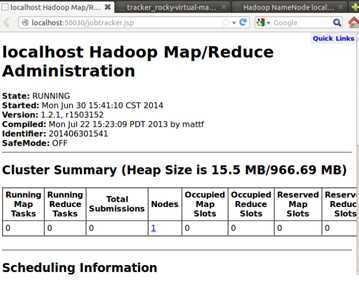
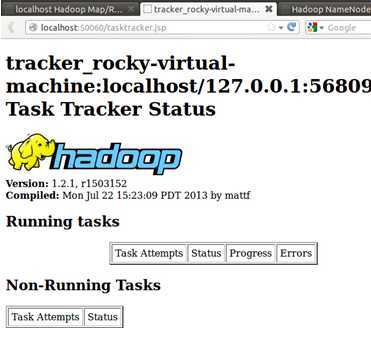
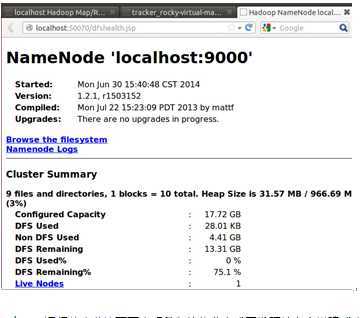
上述Hadoop运行状态监控页面表明我们的伪分布式开发环境完全搭建成功!
接下来我们使用新建的伪分布式平台运行wordcount程序:
首先在dfs中创建input目录:

此时创建的文件因为没有指定hdfs具体的目录,所以会在当前用户“rocky”下创建“input”目录,查看Web控制台:
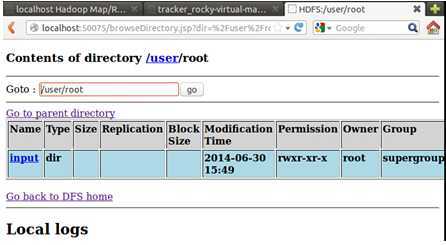
执行文件拷贝操作
Spark教程-构建Spark集群-配置Hadoop伪分布模式并运行Wordcount示例(1)
标签:blog http java os 使用 io 文件 ar 2014
原文地址:http://www.cnblogs.com/spark-china/p/3935145.html