标签:集中 错误 general 技术 性能 多少 ges bsp 相关
能评价:
分类任务可以分为两个子集:“相关的”、“不相关的”。
精确率:“相关的”子集中的正确的样本的比例。
召回率:实际“相关的”子集中正确标注的样本的比例。
| 预测结果 | 标注结果 | ||
| 正例 | 负例 | ||
| 黄金标准 | 正例 | 真正的正例(tp) | 错误的负例(fn) |
| 标注结果 | 负例 | 错误的正例(fp) | 真正的负例(tn) |
精确率:$P = \frac{tp}{tp+fp}$ 正样本中有多少被分类为正样本
召回率:$R = \frac{tp}{tp+fn}$ 分类为正样本的样本中有多少是真正的正样本
准确率:$A = \frac{tp+tn}{tp+fp+fn+tn}$
F值:P和R的结合
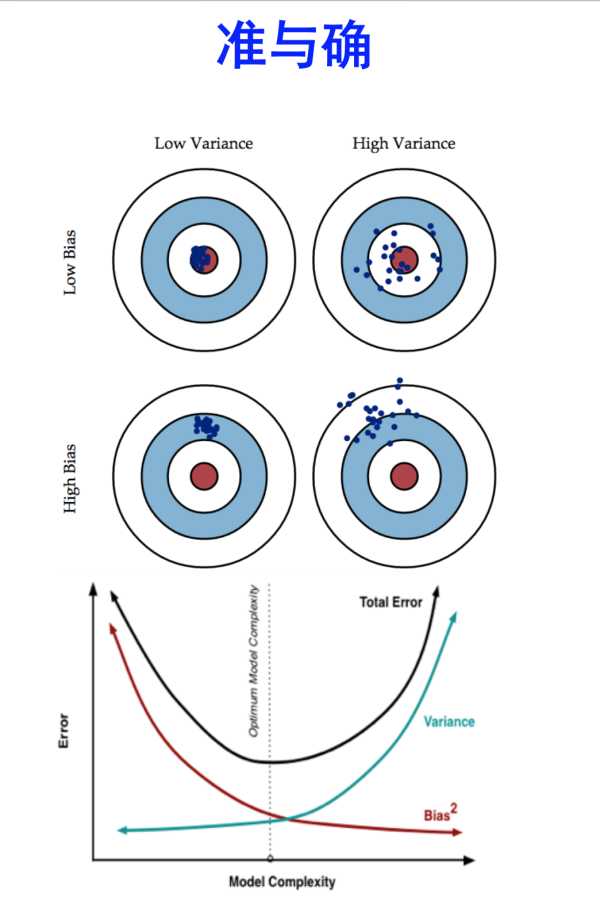
(来自于知乎中修宇亮的回答 https://www.zhihu.com/question/27068705)
Bias和Variance是针对Generalization(一般化,泛化)来说的。
Error = Variance (方差)+ Bias(偏差)
准:bias描述的是根据样本拟合出的模型输出的预测结果的期望与样本真实结果的差距,即在样本上拟合得好不好。想要在bias上表现的好,即获得low bias,就是要将模型复杂化,增加模型的参数,但这样很容易过拟合,对应上图中右上角的图,点都在中心附近,但很分散。
确:varience描述的是在样本上训练出来的模型在测试集上的表现,想要在varience上表现好,即获得low varience,就要将模型简单化,减少模型的参数,但这样容易欠拟合,对应上图中左下角的图,点很集中但偏离中心。
训练一个模型的最终目的,是为了让这个模型在测试数据上表现好,也就是test的error比较小,但在现实问题中,test data 我们是不知道的,不知道test data的内在规律,那么该如何减小test error呢?
分两步:
1)让train error 尽可能小
2)让train error 尽可能等于 test error
(因为A小,而A=B,那么B就小。)
让train error 尽可能小 ----》将模型复杂化,增加参数 ----》low bias
让train error 尽可能等于 test error ----》将模型简单化,减少参数。train error = test error 意味着模型对所有数据没有偏见,对所有数据一视同仁,更具有通用性 ----》low varience
标签:集中 错误 general 技术 性能 多少 ges bsp 相关
原文地址:http://www.cnblogs.com/jiangxiaoxiu/p/6774252.html