标签:保存 编程模式 情况 img spark ... 关系型数据库 shell 数据
一:准备
1.启动服务
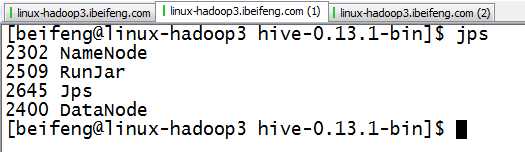
2.启动spark-shell

二:测试检验程序
1.DataFrame的构成
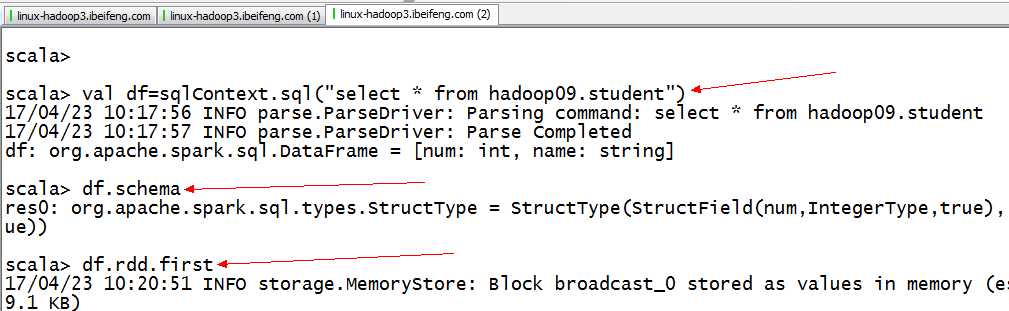
2.结果

三:DataFrame的创建
1.创建SQLContext
val sqlContext=new SQLContext(sc)
2.创建DataFrame(两种方式)
val df=sqlContext.#
val df=sqlContext.read.#
3.DataFrame数据转换
val ndf=df.#.#
4.结果保存
ndf.#
ndf.write.#
四:DataFrame的保存
1.第一种方式
将DataFrame转换为RDD,RDD数据保存
2.第二种方式
直接通过DataFrame的write属性将数据写出。
但是有限制,必须有定义类实现,默认情况:SparkSQL只支持parquet,json,jdbc
五:DataFrame reader编程模式
功能: 通过SQLContext提供的reader读取器读取外部数据源的数据,并形成DataFrame
1.源码的主要方法
format:给定数据源数据格式类型,eg: json、parquet
schema:给定读入数据的数据schema,可以不给定,不给定的情况下,进行数据类型推断
option:添加参数,这些参数在数据解析的时候可能会用到
load:
有参数的指从参数给定的path路径中加载数据,比如:JSON、Parquet...
无参数的指直接加载数据(根据option相关的参数)
jdbc:读取关系型数据库的数据
json:读取json格式数据
parquet:读取parquet格式数据
orc: 读取orc格式数据
table:直接读取关联的Hive数据库中的对应表数据
2.
标签:保存 编程模式 情况 img spark ... 关系型数据库 shell 数据
原文地址:http://www.cnblogs.com/juncaoit/p/6777648.html