标签:线性 共享 优点 斯坦福 获取 写代码 9.png 字符串 lex
被用于重新实现AlexNet,然后用AlexNet的特征来解决其他事情
用C++书写的,可以去GitHub上面读取源代码
主要四个类:

Blob可以存你的权重,像素值,激活等,是n维的张量,就像NumPy一样,他实际上内部有四个n维张量,这个张量有一个数据的版本,用于存储原始未处理的数据。剩下三个分别有diffs,GPU,CPU;
层是一种与你作业中所需要实现的功能相似的功能,会接收输入的Blob,caffe管这些输入的Blob称为底端输入,然后生成。输出的Blob,caffe称其为顶端Blobs。其原理就是,这些层会接收指针指向底端Blobs,这些Blobs中已经有了数据。他们还会收到指向顶端Blobs的指针,他会向前传递,最终会将数据填满在顶端Blobs的数值中。在向回传递时,这些层会实现梯度算法。他们会接收到指向顶端Blobs的指针,Blob中存储了梯度和激活值,他还会接收一个指向底部Blobs的指针,其中已经存满了梯度。问题是:没有一个很好的列表来完整的写出所有层的种类
网的作用就是把许多的层连接在一起。Net其实就是层额有向非循环图,其作用就是按正确的顺序执行层的向前和向后的方法
求解器的功能就是进入Net中,前后地用数据来运行Net,更新网络中的参数,进行检查,并把数据从检查点恢复等一系列的事情。
使用caffe不用书写代码,但要遵循四个步骤:

必须用lua来写,lua语言是专门为前入睡设备设计的,他运行得非常高效。缺点是处理字符串等这类的工作有时候会显得很笨重,并且数组下标是从1开始。
在torch里,我们并不需要区分层和网络,所有的一切只是一个模型而已,整个神经网络是一个模型,每一层也是一个模型。模型又是用lua定义的类,在实际使用的时候用的是tensor API
linear就是lua的全连接层
顺序容器就是有很多模型,每一个都把前一个的输出作为输入,进入一个线性的堆栈
concat表:你想要对同一个输入执行两个不一样模型,这个表支持你这样做,你会得到一个清单的结果
并行表:如果你有一个清单的输入,你想要对每一个输入都应用不一样的模型,你可以使用并行表
工作流程:

最大的弊端是对RNN无能为力
Python是一种解释性语言,这就是为什么他循环效果很差,因为需要进行大量的内存分配和一些其他相关的事情
他全是关于计算图的,计算图能很好地把复杂的结构整合到一起
为了训练的不同之处在于我们可以计算微分,这里dw1,dw2是损失函数关于w1和w2的梯度,theano可以让你求得图中任一部分关于另一部分的梯度,然后把他们作为新的变量引入计算图中
实现方式叫做共享变量,他是网络中的另一部分,实际上是计算图中存在的值,每一次调用值都不变
也支持多GPU
事实上Keras还会使用Tensorflow作为后端
theano有预训练的模型,Lasagne有一个模型组,有着你可能需要的大量不同模型结构
缺点:对于快速迭代的模型这不是很理想的;他的API比torch要胖一些,必须在后台完成这些复杂的事情;预训练的模型可能没有caffe和torch那么好
采用了操作图的思想,并在此基础上添加了所有的东西
one-hot(独热):在任务中做的softmax损失函数,y总是一个整数,告诉你所需要是哪个,在一些框架中他不是整数,他是一个向量
优点:将任务分配到多个设备,在TensorFlow中,每个设备的输出都是计算图谱中的一个检查点
缺点:如果你想做一些创新,而且无法用计算图谱实现,则可能会遇到麻烦,但是使用torch的话,则可以做任何创新;没有预训练好的模型
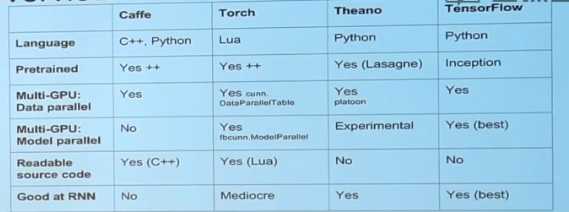
假设我们想要提取AlexNet或者VGG-Net的特征,我们会选择使用Caffe;
如果我们想要对AlexNet进行调优,选择caffe;
如果我们要做调优图片截取,我们需要预训练好的模型还有RNN,则我们可以选择torch或者lasagna;
如果要进行场景分割,我们先要将每个像素点分割开来,首先我们要读取一张输入图片,我们不想要对图片进行标注,而是希望获取独立的每个像素点的标签,需要一个预训练好的模型,所以使用caffe或者torch;
对于物体检测,需要预训练好的模型,还可能要做一些奇特的创新,所以caffe+Python或者torch;

斯坦福CS231n—深度学习与计算机视觉----学习笔记 课时24&&25
标签:线性 共享 优点 斯坦福 获取 写代码 9.png 字符串 lex
原文地址:http://www.cnblogs.com/bxyan/p/6785254.html
{kind=link}