标签:oss 公式 对比 represent 梯度下降 去中心化 tween work height
DeepLDA 并不是把LDA模型整合到了Deep Network,而是利用LDA来指导模型的训练。从实验结果来看,使用DeepLDA模型最后投影的特征也是很discriminative 的,但是很遗憾没有看到论文是否验证了topmost 的hidden representation 是否也和softmax指导产生的representation一样的discriminative。
DeepLDA和一般的deep network唯一不同是它的loss function。两者对比如下:

对于LDA,优化的目标是最小化类内方差,同时最大化类间方差。由于LDA是一个有监督的模型,对于多分类的情况如![]() 个类,则最终投影的一个子空间
个类,则最终投影的一个子空间![]() 的维数只有
的维数只有![]() 。多分类情况LDA优化的目标公式为,
。多分类情况LDA优化的目标公式为,
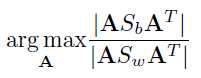
其中A就是投影矩阵。![]() 是between scatter matrix,可以理解为类中心间的方差;而
是between scatter matrix,可以理解为类中心间的方差;而![]() 定义为within scatter matrix,可以理解为类内协方差的和。它们的计算公式如下:
定义为within scatter matrix,可以理解为类内协方差的和。它们的计算公式如下:
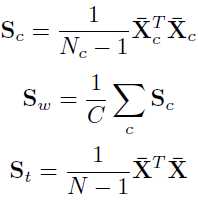
这里,我们已经假设所有的样本都是去中心化的了![]() 。最后问题变成了一个泛化的特征方程求解的问题
。最后问题变成了一个泛化的特征方程求解的问题![]() ,矩阵A对应着相应的特征向量。
,矩阵A对应着相应的特征向量。
事实上,特征向量指示着投影最大方差的方向,特征值则是对特征向量重要程度的一个量化。而论文的一个insight就是,希望可以指导网络生成topmost的representation能够在各个方向都产生较大的特征值,即不希望投影的方向在某个方向更方差会更大,因为这代表了信息量的多少。论文提出一种直接把特征值作为loss function的方法,因为训练的时候,网络倾向于优化最大的特征值,产生一个trivial的结果,即使得大的特征值会倾向于更大而牺牲其他小的特征值。因此论文定义loss function在小的特征值上:
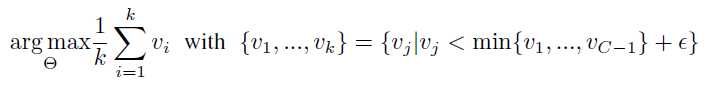
特征值的求解是建立在topmost的representation的基础上的。模型的训练使用mini-batch的随机梯度下降法,而特征值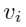 可以直接对representation
可以直接对representation ![]() 进行求导:
进行求导:
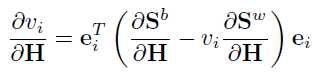
论文的appendix可以看到完整的求导过程。
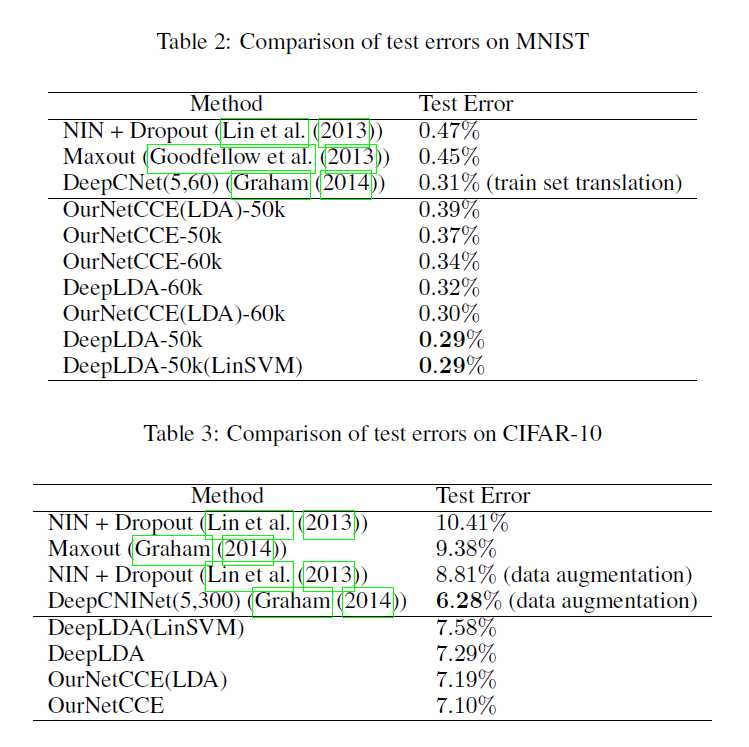
最后,论文的实验室通过对project后的特征进行分类,所以比较的是分类的精度,以及test error。而且,实验的结果还挺competitive的。
【CV论文阅读】Deep Linear Discriminative Analysis, ICLR, 2016
标签:oss 公式 对比 represent 梯度下降 去中心化 tween work height
原文地址:http://www.cnblogs.com/jie-dcai/p/6808862.html