标签:for 视图 www 拷贝 ret iter ted 读写 https
主要分析 List Map Set 中的 并发集合。 默认基于1.6分析
juc包下的类;
该类是支持随机访问的List, 和Vector(同步锁实现线程安全)和ArrayList(非线程安全)对照。
transient final ReentrantLock lock = new ReentrantLock();private volatile transient Object[] array;
array 和ArrayList 一样。 还是Object类型数组。volatile 保证该引用线程可见性。
对于array中数据的读写,此类都是通过函数getArray/setArray实现。 也就是简单的get(i) 也不能直接返回array[i] 而是需要先通过getArray()获取array然后使用索引获取值。
ArrayList 中默认数组大小10 ; 此处默认创建空的Object数组。
由于Arrays.ArrayList.toArray() 该方法返回的数组不是Object类型数组(数组本质类型不是引用)。 这属于javaBug .所以集合中基于 数组存储的类像ArrayList Vector等都需要做检查,防止array指向非Obeject数组。
http://www.cnblogs.com/zhizhizhiyuan/p/3662371.html
即对于数组元素不会修改的函数。
contains。indexOf。lastIndexOf。toArray()。get。containsAll().
这些函数对底层数组并不修改但是执行之前都必须使用getArray()获取 内部的数组array进而操作!
以下的这些函数都会对数组发生修改,他们在执行时都会加锁解锁(独占锁),这些函数都会创建新的数组然后将array指向新的数组。
该类实现的同样是浅拷贝。 该类中默认会持有独占锁该变量是transient的,所以需要单独克隆(初始化该变量)。
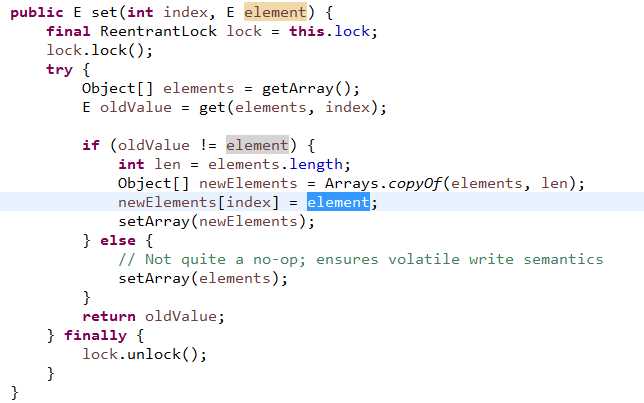
执行前后都要使用 独占锁 加锁解锁。
同样该操作每次也会创建新的数组,然后直接更新数组引用。
对于数组使用都是使用getArray和setArray 不能直接操作该引用。
remove 同上。也是创建新的数组。修改array指向的数组。
removeAll(Collection<?>) 也是创建新的数组,将留下的元素放到新的数组中,最后修改array引用。
直接将数组指向新的空数组。
该方法在ArrayList中没有; 如果元素不存在就添加
addAllAbsent(Collection<? extends E>) 同理。
此类直接实现List接口, 所以自然也支持两种迭代器。 但是该类实现时将这两个迭代器使用一个类实现COWIterator
支持双向遍历,不支持remove ,set, add


A: 该类中不可变函数(不修改数组内容结构)并不会修改array引用, 而可变函数当add元素后就会修改该类中array引用指向新的数组。也就是当次迭代器在迭代过程中时,别的线程add修改底层数组,这只会导致array指向别的数组。而该迭代器snapshot指向的还是之前的数组,并不会受到影响。

该类本质就是对 能造成数组修改的函数 : 每次都创建新的数组,将array指向新的数组。
对于迭代器: 不支持修改数组操作。 不同的迭代器实现的效果就是保存当前 array的镜像, 不会受到外部数组修改影响(对此也不可见)。
场景
线程安全:
该类的线程安全是使用volatile+独占锁 实现。
Q: 对于修改操作只能是使用创建新的数组这样方式?
A: volatile仅仅能保证该引用的可见性。juc中原子类也仅仅能提供对对象个别字段的原子更新。如果不使用此方法那么我们就需要对get等读方法采取加锁以保证看到最新值。 此类使用此方法就是适合读多写少场景,所以写操作开销稍微大点。以上解释有误; 参见ConcurrentHashMap中对于每个Segment(相当于一个HashMap)中维护的 volatile Entry[] 如何保证读写可见性。 ????
使用:
该描述和CopyOnWriteArrayList 几乎一模一样,只是此是Set
继承体系
该类直接继承自AbstractSet,该类并不像AbstractList中实现了许多方法,仅仅实现了个别方法。
该类持有CopyOnWriteArrayList, 二者本身功能类似只是此类是Set不支持重复,那么只要在add时控制重复元素即可。(实际上也是这么做的使用addIfAbsent代替add 防止重复)
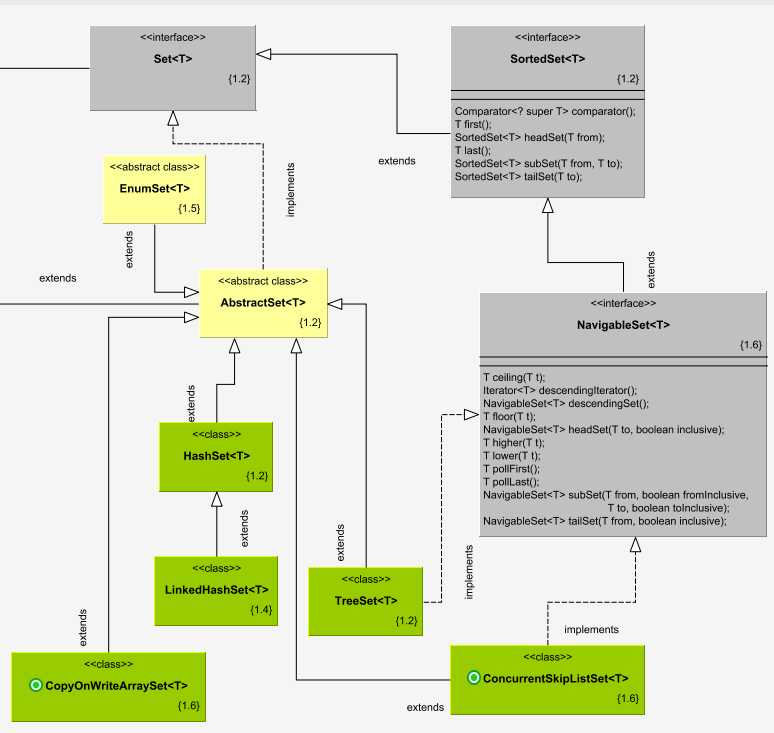
此类基于CopyOnWriteArrayList(代理模式or 适配?)
该类仅仅是对add方法稍加修改使用 addIfAbsent防止重复,迭代器等实现都一样,代理调用;
equals(Object): 实现Set版本的比较。无序比较。
https://www.ibm.com/developerworks/cn/java/java-lo-concurrenthashmap/
http://www.infoq.com/cn/articles/ConcurrentHashMap
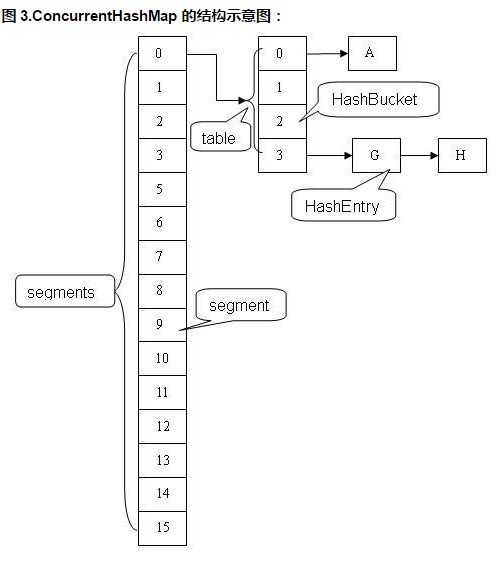
该类中主要有四种函数
该类中键值 均不允许使用null, hashMap中允许;
segmentMask 和 segmentShift : 二者是用来定位segment区域的。构造函数中会初始化此变量。
segment数组长度默认16,(它也会选取2的N次幂作为长度,方便hash定位区域,和HashMap类似) 简单来说当get(O)时:
三个视图变量: AbstractMap中以及有了两个视图变量(本来是volatile),此处覆盖后取消volatile;(而在HashMap中直接使用抽象类中定义的volatile变量。)
一个Map对象中,这三个变量实质上都是只有一个实例。也并不涉及引用的改变,所以也没必要volatile?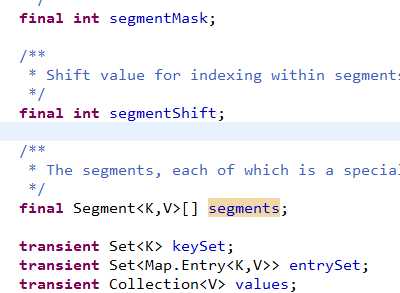
和HashMap相比,此函数多了一个参数concurrencyLevel;

对get() , put(), contain(), remove(), clear() ; 这些函数。 外层类中主要工作就是找到该元素所在区域segment, 然后在该区域中执行操作. 核心就是区域定位
get:


该类就是一个Map中的一个区域, 功能等于HashMap, 只是get put 程安全。
每个区域相对于别的区域都是独立的 ,ConcurrentHashMap 正是将Map划分为不同的区域才能提供并发。(缩小冲突范围)
该类的实现基本和HashMap一致。 此处选取个别方法分析 如get put;
该类为ReentrantLock子类,也就是该segment本身就能当作锁来使用。
在get等读操作中不会锁,只有put等写操作才会采用锁。 而且各个区域Segment持有各自不同的锁。
变量:
transient int modCount; : 和HashMap一样,该变量记录Map结构修改次数。 HashMap中使用此变量实现fail-fast机制,而此类并不用此机制。 此变量主要是用来ConcurrentHashMap.size().(外部类中并不记录总的映射个数,利用此变量提高并发,见size()分析)
hash : 和HashMap中一致: return tab[hash & (tab.length - 1)]; 都是直接利用hashcode直接确定。如当前segment中桶为32,即依据hashcode的低5位直接判断所在的桶;
rehash() : 此函数只在put()中被调用,而put每次执行需要加锁解锁,所以此函数不会出现多个线程同时执行。
假设当前桶的长度是8也就是从000-111, 那么每次使用hashcode的低3位便可以确定所在的桶。 假设现在扩容为16长度也即使用末尾4位判断桶位置。
所以对于原来某个桶中的元素(如0号):只会被分到0号或者8号桶中;
该函数执行过程中会尽量使用原有的Entry. 但是绝对不会破话原有Entery的结构。 实际上HashEntry的next引用也被设置为final防止修改。

get操作不需要获取锁,这也是ConcurrentHashMap能高效并发的原因!
该类中不允许key-value为null;
count作用:
A: count是volatile变量。在每次get前都会读取,而在每次put后都会执行写入操作。这样做是利用volatile内存语义。保证上次put操作的修改能够对此get可见。
在contain等函数中同样每次都会读取count;
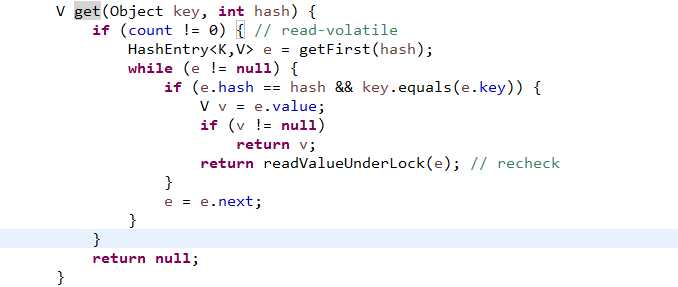
利用传入的hash定位桶,在该桶中变量查找键值对然后返回。segment中不允许键值对为null,为什么此处v可能为null?
A: 写操作put是需要持有锁的,而get不需要。put执行时对于已经存在的键直接修改value即可, 对于新的键需要创建新的HashEntry。由于put和get并没有同步。所以就会造成get定位到HashEntry时该对象还没有完成初始化。
此时就需要尝试通过获取锁来获取value值。 即readValueUnderLock函数
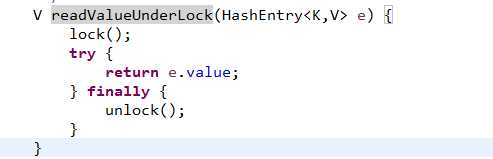
Q: 关于get put多线程环境下可见性,当一个线程put多个线程get时,count的可见性语义仅仅能保证此时刻之前的操作可见, 但是get毕竟不是原子操作。所以get可能会读取到旧的值,但是肯定不会是异常值? 而HashTable中get put 全部持有锁,造成执行串行话,但是HashTable肯定是能看到最新的值。 所以此处get并不是严格地能够获取到最新值??
A: get弱一致性; 以上说的情况的确可能会发生;
api中也提到 Retrievals reflect the results of the most recently completed update operations holding upon their onset.
由于get操作无锁,所以他能观测到put中途执行结果,无锁并发,就是把原来的竞争块变成了点,为成了一个一个的点,就不存在冲突了,并且前后顺序的关键点不是原来的数据写入或读取,而是用来同步的标记之类的读写,上面就是count变量的读写,是一种思维的转变。如果要保证一个并发工具,在执行某个操作后保持该状态,那这就是锁的使用场景
但是从宏观角度put方法执行完之后,get肯定能看到put的结果;
http://ifeve.com/concurrenthashmap-weakly-consistent/
关于读写并发?
A: 参照3.3.3中讨论,1写+多读如何保证不会出现异常。
当创建新的Entry后 写入volatile 变量 count. 但是修改value时为什么写入该变量呢???

contain: 包含两个版本使用key或者value.
replace() 也是两种,直接使用key替换,或者基于key-value。 需要持有锁
clear(): 需要持有锁。直接将table[i]设置为null。
外部类ConcurrentHashMap中不记录总的键值对,Map修改次数等。这些都是记录在各自区域Segment中。
在HashMap中modCount被用来实现fail-fast机制。 而此处并没有此机制。
size需要读取各个区域的count变量,最暴力的方法便是一次性对所有区域加锁,然后计算count总和然后释放全部锁。但是这样代价太高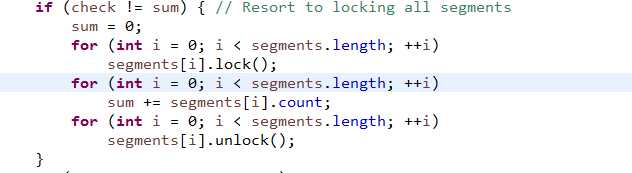
ConcurrentHashMap中充分利用各个区域的modCount(记录该区域Map结构修改次数)
ConcurrentHashMap会对以上不加锁的统计方法尝试两次
该函数仅仅是判断空,所以只要某个区域count!=0 就能返回false.
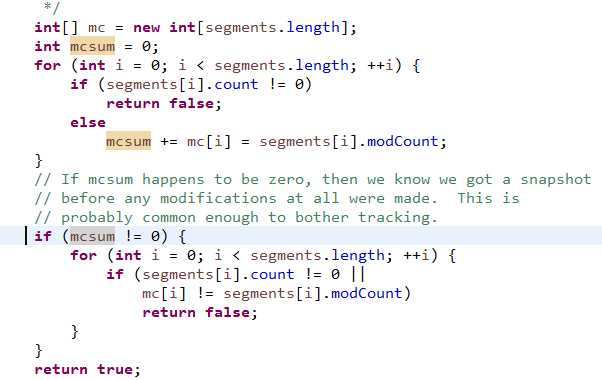
ABA 问题:
假如区域A 在第一次遍历时count = 0, modCount = 1; 第二次遍历 count = 0, modCount = 100;
如果仅仅依靠modCount那么就认为Map没有改变,即Map为空(即使中间经历了许多操作ABA问题 , 0再次被视为同一状态,但是二者其实是不同状态。)
一般对于ABA问题,例如原子类中, 一般是状态绑定时间戳int值来表示二者状态变化。 此处就可以将modCount视为时间戳变量 前后两次的遍历可以认为是不同状态。
该函数可靠性?
A: 由于该函数并没有持有锁,所以其必然没有HashTable那样的可信度。 也就是即使我们两次for循环遍历认为当前Map为空, 但是在执行return之前还可能发生许多次的put操作。(虽然可能性比较小。)
该类中许多函数都是这样。由于不加锁,所以并不具有绝对的语义??
该函数同上类似,只是涉及到全局Map遍历查找。
视图: keySet()。values()。values()。
Enumeration: keys。elements()。
视图概念和HashMap一致,都是对底层的Map数据操作。 各个视图都支持使用iterator返回各自视图的迭代器。
和HashMap相比,此类涉及到分区域Segment, 所以迭代器实现时需要记录更多信息。
abstract class HashIterator {int nextSegmentIndex; //下一个需要遍历的区域编号int nextTableIndex; // 当前区域内,下一个需要遍历的 桶编号HashEntry<K,V>[] currentTable;HashEntry<K, V> nextEntry; // 下一个需要遍历的EntryHashEntry<K, V> lastReturned;
next和remove: 不支持fail-fast, 所以也不必检查modCount等变量。remove函数虽然不是同步的但是它调用的底层remove函数需要获取独占锁,所以此操作是线程安全的。
advance() : 用来获取一个Entry后调整nextSegmentIndex,nextTableIndex,nextEntry等变量方便下次操作。
本质也是迭代器,只是不支持remove操作。 对于keys和elements 都是返回各自的迭代器。 和各自视图中使用相同的迭代器。
在此类中Enumeration和Iterator 遍历效果一模一样,调用函数都是一样的;
ConcurrentHashMap 是一个并发散列映射表的实现,它允许完全并发的读取,并且支持给定数量的并发更新。相比于 HashTable 和用同步包装器包装的 HashMap(Collections.synchronizedMap(new HashMap())),ConcurrentHashMap 拥有更高的并发性。在 HashTable 和由同步包装器包装的 HashMap 中,使用一个全局的锁来同步不同线程间的并发访问。同一时间点,只能有一个线程持有锁,也就是说在同一时间点,只能有一个线程能访问容器。这虽然保证多线程间的安全并发访问,但同时也导致对容器的访问变成_串行化_的了。
ConcurrentHashMap 的高并发性主要来自于三个方面:
http://ifeve.com/concurrenthashmap-weakly-consistent/
get, clear() 以及迭代器等, 都是弱一致性。
clear: 因为没有全局的锁,在清除完一个segments之后,正在清理下一个segments的时候,已经清理segments可能又被加入了数据,因此clear返回的时候,ConcurrentHashMap中是可能存在数据的。因此,clear方法是弱一致的。
get() :3.3.3;
3.3.3 中问题, get和put多线程下 可见性》
A: put方法执行完之后,get肯定能看到put的结果
3.3.4 中put函数count变量为什么不在 修改value地方写入,而仅仅在创建新的节点后写入??? 这样能保证get可见性????
标签:for 视图 www 拷贝 ret iter ted 读写 https
原文地址:http://www.cnblogs.com/yuan7712/p/6817142.html