标签:min 理解 war pre www dfs 权限 是什么 comm
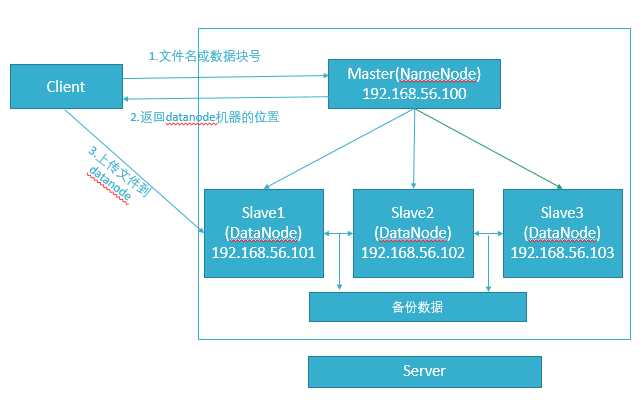
1、hdfs是什么?它与普通服务器的文件系统有什么区别?它的特性有什么?
2、hdfs的工作原理是怎样的?
3、每台机器都单独启动有什么弊端?假设有1000台机器需要启动?该怎么解决呢?
4、hdfs配置与使用
5、利用javaApi充当客户端访问hdfs
hdfs就是一个分布式文件系统。简单说,就是一个“分鱼展”的大硬盘,跟普通的文件系统没什么区别,只是它有多台机器共同承担存储任务。
分鱼展指的是hdfs的特性分别指分布式、冗余性、可拓展。
普通服务器文件系统:上传文件到服务器

hdfs分布式文件系统:相当于一块大硬盘、百度云网盘(内部实现就是hdfs)。
举例:上传一个1G的文件。
分布式:别把hdfs理解得有多难,多抽象,只是数据从存储到一台机器上变成存储到多台机器上罢了。对于客户端而言,它就是一块硬盘,就是一台机器文件系统,跟JavaIO并没有很大差异。
冗余性:因为分布式很难控制,一不小心就宕了一台机器呢?数据容易丢失,备份多份数据是非常有必要的,这也是hdfs的容错性。
拓展性:拓展就是机器之间解耦,随时拓展集群、增加机器维持服务的供给。假设服务器正常运行中,突然之间Slave1宕了,那么怎么办?在我们潜意识当中,肯定分布式系统会自动去备份一份数据到另外一台内存占用比较低的机器。在hadoop有一概念叫做“心跳”检测,就是Master会每隔一段时间给集群发送一个消息,如果没有回应就默认机器宕了,然后Master会把重新把宕了的机器数据重新分配备份到内存占有率比较低的机器。善于思考的大佬们又想了,假设Master宕了呢?这么严重的问题,hadoop的开发者当然要考虑进去,在hadoop里面有一个类似于NameNode东西叫做SecondaNameNode,它将会隔一段时间将NameNode的快照和日志备份一遍到自己机器,并且通知NameNode更新日志,当NameNode宕了,SecondaNameNode将会及时顶上。有分析很透彻的文章,我就不班门弄斧了。http://blog.csdn.net/xh16319/article/details/31375197
1、回顾之前命令
查看结点启动情况:jps
启动|关闭NameNode:hadoop-daemon.sh start|stop namenode
启动|关闭DataNode:hadoop-daemon.sh start|stop datanode
查看集群情况:hdfs dfsadmin -report或者利用网页http://192.168.56.100:50070
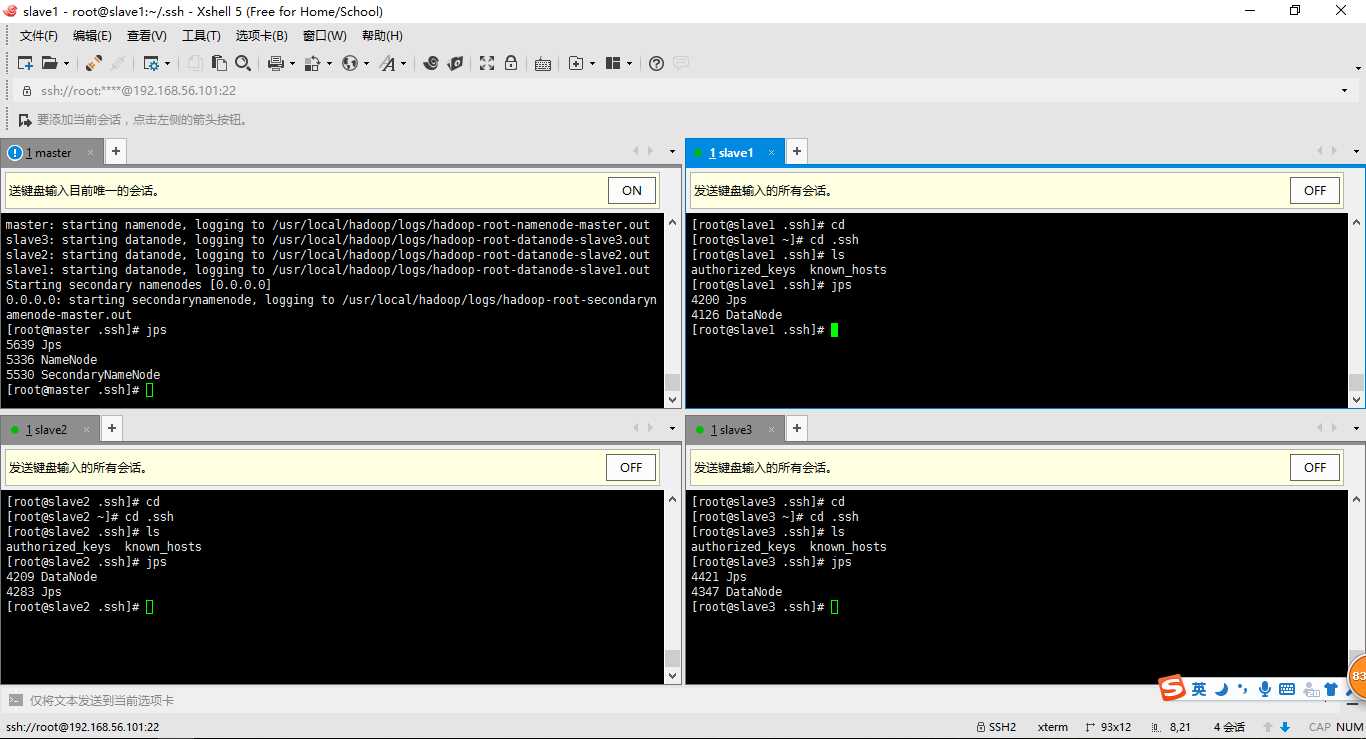
2、集中式管理集群(注意:我们修改过的配置文件:/etc/hadoop/slaves)
slave1 slave2 slave3
3、启动集群(如果没有配置环境变量:start-dfs.sh、stop-dfs.sh在/usr/local/hadoop/sbin目录下找)
切换至目录/usr/local/hadoop/sbin
使用start-dfs.sh启动集群
使用stop-dfs.sh关闭集群
问题:需要依次输入远程机器的登录账号密码?这样貌似作用不大啊?
答:在master机器上可以设置ssh远程登录的免密工作。ssh slave1输入账号密码就能远程登录
cd
ls -la
cd .ssh
ssh-keygen -t rsa (四个回车)
#会用rsa算法生成私钥id_rsa和公钥id_rsa.pub
ssh-copy-id slave1
ssh-copy-id slave2
ssh-copy-id slave3
1、解释hdfs最简陋的/usr/local/hadoop/etc/hdfs-site.xml配置文件。注意:修改完配置以后,一定要对master进行 hadoop NameNode -format
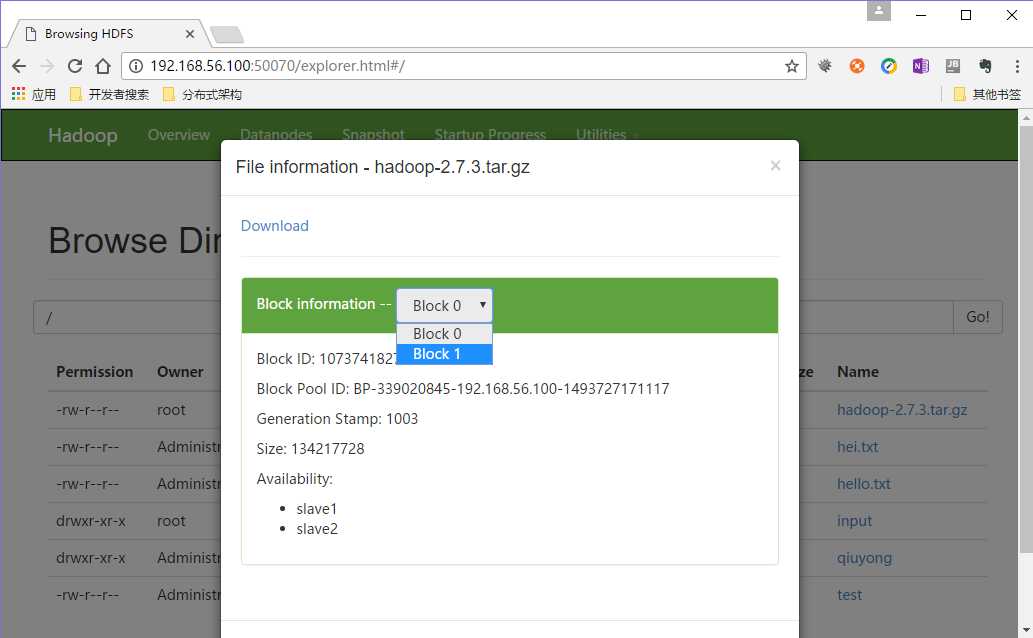
<configuration> <!--文件的存储位置--> <property> <name>dfs.name.dir</name> <value>/usr/local/hadoop/data</value> </property> <!--关闭dfs权限,以免待会不允许客户端访问--> <property> <name>dfs.permissions</name> <value>false</value> </property> <!--备份数据多少份,默认三份,我配置了两份测试--> <property> <name>dfs.replication</name> <value>2</value> </property> <!--心跳检测--> <property> <name>dfs.namenode.heartbeat.recheck-interval</name> <value>10000</value> </property> </configuration>
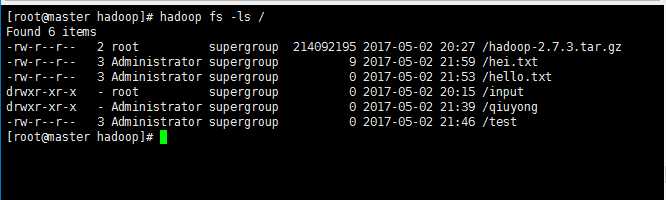
2、hdfs的使用(最好通过网页查看 http:192.168.56.100:50070)
1、添加jar-pom.xml包
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.ccut.aaron.test</groupId> <artifactId>HadoopHdfs</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>war</packaging> <name>HadoopHdfs</name> <description/> <properties> <webVersion>3.0</webVersion> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.3</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.3</version> </dependency>
</dependencies> </project>
2、读文件
public class ReadFile { public static void main(String[] args) throws MalformedURLException, IOException { URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory()); InputStream in = new URL("hdfs://192.168.56.100:9000/hei.txt").openStream(); IOUtils.copyBytes(in, System.out, 4096, true); } }
3、写文件
public class WriteFile { public static void main(String[] args) throws IOException { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://192.168.56.100:9000"); FileSystem fileSystem = FileSystem.get(conf); boolean b = fileSystem.exists(new Path("/hello")); System.out.println(b); boolean success = fileSystem.mkdirs(new Path("/mashibing")); System.out.println(success); success = fileSystem.delete(new Path("/mashibing"), true); System.out.println(success); FSDataOutputStream out = fileSystem.create(new Path("/hei.txt"), true); FileInputStream fis = new FileInputStream("f:/hei.txt"); IOUtils.copyBytes(fis, out, 4096, true); FileStatus[] statuses = fileSystem.listStatus(new Path("/")); //System.out.println(statuses.length); for(FileStatus status : statuses) { System.out.println(status.getPath()); System.out.println(status.getPermission()); System.out.println(status.getReplication()); } } }
标签:min 理解 war pre www dfs 权限 是什么 comm
原文地址:http://www.cnblogs.com/qiuyong/p/6816949.html