标签:集成 体验 max png min strong style 条件 延时
在0.11之前的版本中,多个consumer实例加入到一个空消费组将导致多次的rebalance,这是由于每个consumer instance启动的时间不可控,很有可能超出coordinator确定的rebalance timeout(即max.poll.interval.ms),而每次rebalance的代价又相当地大,因为很多状态都需要在rebalance前被持久化,而在rebalance后被重新初始化。曾经有个国外用户,他有100个consumer,每次rebalance的时间甚至要1个小时以上!
对于目前版本的Kafka来说,consumer的rebalance的确有需要需要改进的部分,很容易想到的包括:
值得高兴的是,社区已经实现了第一个改进并将其集成进0.11.0.0版本中,也就是说用户在升级到0.11后便可以体验到这种延时rebalance的效果,主要表现为空消费组从EMPTY到STABLE的时间间隔应该显著缩短。本文将简要介绍一下该新功能以及实现原理。
新增参数:group.initial.rebalance.delay.ms
对于用户来说,这个改进最直接的效果就是新增了一个broker配置:group.initial.rebalance.delay.ms,默认是3秒钟。用户需要在server.properties文件中自行修改为想要配置的值。这个参数的主要效果就是让coordinator推迟空消费组接收到成员加入请求后本应立即开启的rebalance。在实际使用时,假设你预估你的所有consumer组成员加入需要在10s内完成,那么你就可以设置该参数=10000。目前来看,这个参数的使用还是很方便的~
coordinator底层修改
为了实现这一功能,需要修改一些底层的设计。首先,对于消费组状态而言,之前的文章中讨论过,当前的状态机如下图所示:
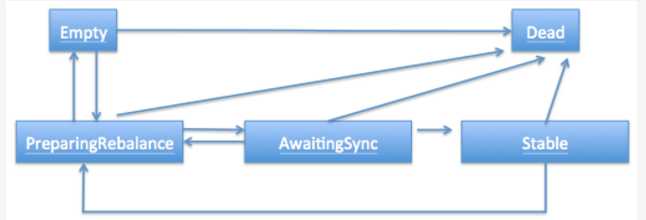
由上图可见,Empty到PreparingRebalance的转化就是发生有成员加入之后。现在在这两个状态之间新增了一个状态:InitialRebalance。那么对于一个空的消费组而言,当第一个成员加入时,组状态会进入到InitialRebalance,同时对这个JoinGroup请求的处理可能会推迟一段时间,但这段时间不会超过rebalance超时时间和group.initial.rebalance.delay.ms两者的小者。之后倘若又有一个新成员加入组,那么仍然按照之前的逻辑,组状态是InitialRebalance,但此时这个请求被推迟的最大时间将会更新为min(剩下的rebalance超时时间,group.initial.rebalance.delay.ms)。这个剩余rebalane超时=初始rebalance超时- N * group.initial.rebalance.delay.ms,N表示前面已经发生过的N次成员加入。改进后的组状态机如下图所示:
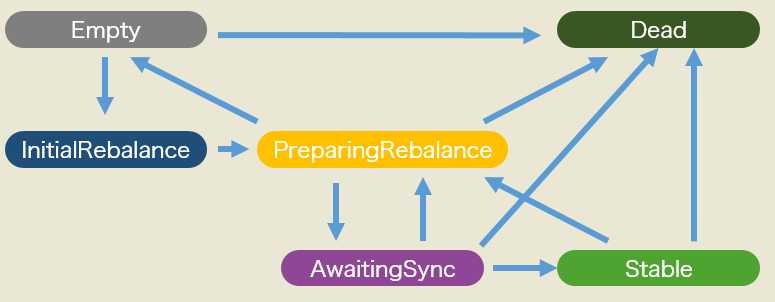
当剩余rebalance超时变更成0时,即认为延时已经过期了,因此coordinator会将消费组状态变更成PreparingRebalance,下面的事情就和之前的流程一致了。至于这些请求是如何在broker端被延时处理的,其实这也要归功于DelayedJoin以及底层的purgatory机制了,有时间的话跟大家详细说说它的设计。
Kafka 0.11版本新功能介绍 —— 空消费组延时rebalance
标签:集成 体验 max png min strong style 条件 延时
原文地址:http://www.cnblogs.com/huxi2b/p/6815797.html