标签:技术 历史 bsp 挖掘 style 任务 spi ima 流处理
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
所谓网络爬虫,就是一个在网上到处或定向抓取数据的程序,当然,这种说法不够专业,更专业的描述就是,抓取特定网站网页的HTML数据。抓取网页的一般方法是,定义一个入口页面,然后一般一个页面会有其他页面的URL,于是从当前页面获取到这些URL加入到爬虫的抓取队列中,然后进入到新页面后再递归的进行上述的操作,其实说来就跟深度遍历或广度遍历一样。
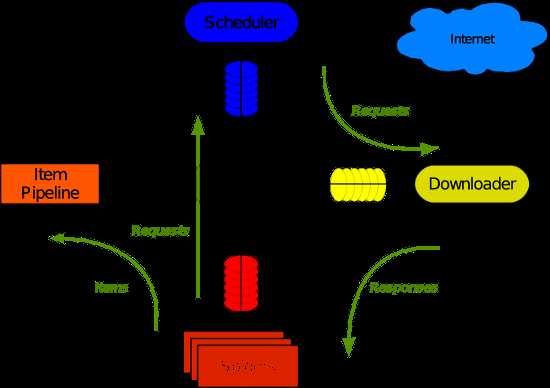
Scrapy 使用 Twisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。
标签:技术 历史 bsp 挖掘 style 任务 spi ima 流处理
原文地址:http://www.cnblogs.com/Mr24/p/6425909.html