标签:框架 ora yarn stack 工作 下一步 预警 拓扑 复杂
本文出处:www.cnblogs.com/langtianya/p/5199529.html
伴随着信息科技日新月异的发展,信息呈现出爆发式的膨胀,人们获取信息的途径也更加多样、更加便捷,同时对于信息的时效性要求也越来越高。举个搜索场景中的例子,当一个卖家发布了一条宝贝信息时,他希望的当然是这个宝贝马上就可以被卖家搜索出来、点击、购买啦,相反,如果这个宝贝要等到第二天或者更久才可以被搜出来,估计这个大哥就要骂娘了。再举一个推荐的例子,如果用户昨天在淘宝上买了一双袜子,今天想买一副泳镜去游泳,但是却发现系统在不遗余力地给他推荐袜子、鞋子,根本对他今天寻找泳镜的行为视而不见,估计这哥们心里就会想推荐你妹呀。其实稍微了解点背景知识的码农们都知道,这是因为后台系统做的是每天一次的全量处理,而且大多是在夜深人静之时做的,那么你今天白天做的事情当然要明天才能反映出来啦。
全量数据处理使用的大多是鼎鼎大名的hadoop或者hive,作为一个批处理系统,hadoop以其吞吐量大、自动容错等优点,在海量数据处理上得到了广泛的使用。但是,hadoop不擅长实时计算,因为它天然就是为批处理而生的,这也是业界一致的共识。否则最近这两年也不会有s4,storm,puma这些实时计算系统如雨后春笋般冒出来啦。先抛开s4,storm,puma这些系统不谈,我们首先来看一下,如果让我们自己设计一个实时计算系统,我们要解决哪些问题。
好,如果仅仅需要解决这5个问题,可能会有无数种方案,而且各有千秋,随便举一种方案,使用消息队列+分布在各个机器上的工作进程就ok啦。我们再继续往下看。
在2011年Storm开源之前,由于Hadoop的火红,整个业界都在喋喋不休地谈论大数据。Hadoop的高吞吐,海量数据处理的能力使得人们可以方便地处理海量数据。但是,Hadoop的缺点也和它的优点同样鲜明——延迟大,响应缓慢,运维复杂。
有需求也就有创造,在Hadoop基本奠定了大数据霸主地位的时候,很多的开源项目都是以弥补Hadoop的实时性为目标而被创造出来。而在这个节骨眼上Storm横空出世了。
Storm带着流式计算的标签华丽丽滴出场了,看看它的一些卖点:
下面,我们简单地认识一下Storm这个产品。
Storm是一个免费开源、分布式、高容错的实时计算系统。Storm令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求。Storm经常用于在实时分析、在线机器学习、持续计算、分布式远程调用和ETL等领域。Storm的部署管理非常简单,而且,在同类的流式计算工具,Storm的性能也是非常出众的。
Storm主要分为两种组件Nimbus和Supervisor。这两种组件都是快速失败的,没有状态。任务状态和心跳信息等都保存在Zookeeper上的,提交的代码资源都在本地机器的硬盘上。
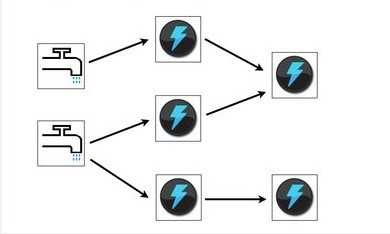
下图是一个Topology设计的逻辑图的例子。
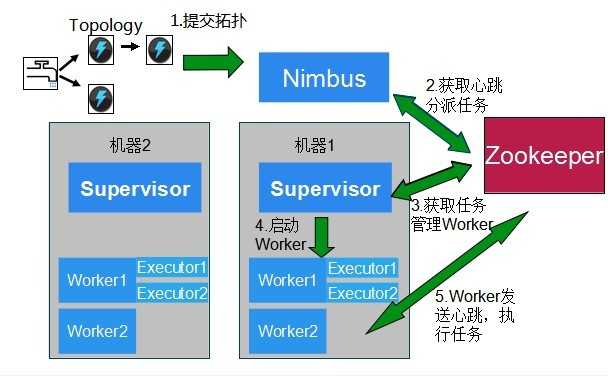
下图是Topology的提交流程图。
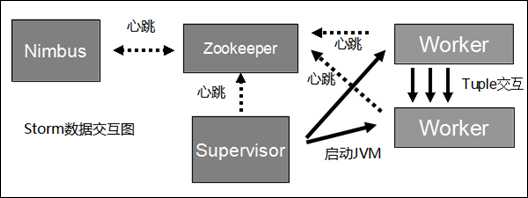
下图是Storm的数据交互图。可以看出两个模块Nimbus和Supervisor之间没有直接交互。状态都是保存在Zookeeper上。Worker之间通过ZeroMQ传送数据。
虽然,有些地方做得还是不太好,例如,底层使用的ZeroMQ不能控制内存使用(下个release版本,引入了新的消息机制使用netty代替ZeroMQ),多语言支持更多是噱头,Nimbus还不支持HA。但是,就像当年的Hadoop那样,很多公司选择它是因为它是唯一的选择。而这些先期使用者,反过来促进了Storm的发展。
Storm已经发展到0.8.2版本了,看一下两年多来,它取得的成就:
Transactional topologies和Trident都是针对实际应用中遇到的重复计数问题和应用性问题的解决方案。可以看出,实际的商用给予了Storm很多良好的反馈。
Storm被广泛应用于实时分析,在线机器学习,持续计算、分布式远程调用等领域。来看一些实际的应用:
如果,业务场景中需要低延迟的响应,希望在秒级或者毫秒级完成分析、并得到响应,而且希望能够随着数据量的增大而拓展。那就可以考虑下,使用Storm了。
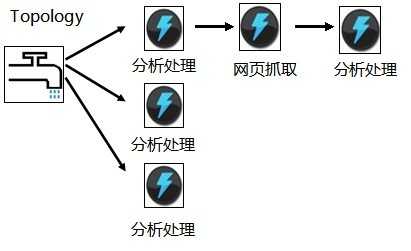
我们只需要实现每个分析的过程,而Storm帮我们把消息的传送和接受都完成了。更加激动人心的是,你只需要增加某个Bolt的并行度就能够解决掉某个结点上的性能瓶颈。
在流式处理领域里,Storm的直接对手是S4。不过,S4冷淡的社区、半成品的代码,在实际商用方面输给Storm不止一条街。
如果把范围扩大到实时处理,Storm就一点都不寂寞了。
当然,Storm也有Yarn-Storm项目,能让Storm运行在Hadoop2.0的Yarn框架上,可以让Hadoop的MapReduce和Storm共享资源。
知乎上有一个挺好的问答: 问:实时处理系统(类似s4, storm)对比直接用MQ来做好处在哪里? 答:好处是它帮你做了: 1) 集群控制。2) 任务分配。3) 任务分发 4) 监控 等等。
需要知道Storm不是一个完整的解决方案。使用Storm你需要加入消息队列做数据入口,考虑如何在流中保存状态,考虑怎样将大问题用分布式去解决。解决这些问题的成本可能比增加一个服务器的成本还高。但是,一旦下定决定使用了Storm并解决了那些恼人的细节,你就能享受到Storm给你带来的简单,可拓展等优势了。
技术的发展日新月异,数据处理领域越来越多优秀的开源产品。Storm的过去是成功的,将来会如何发展,我们拭目以待吧。
本文的重点是描述Storm的应用场景和未来的发展前景,让大家对Storm有一个初步的印象。如果,要落地使用的朋友,在网上可以找到很多优秀的Storm的技术文章。例如:Storm的核心贡献者徐明明的博客和淘宝关于storm的文章。
标签:框架 ora yarn stack 工作 下一步 预警 拓扑 复杂
原文地址:http://www.cnblogs.com/sigm/p/6822757.html