标签:技术 约束 产生 1.5 线性 第一个字符 blog 选择 code
为什么我们不用词法分析那一套方式(正则文法、有限状态机等)来解决语法分析?
正则文法通常什么样?
对于文法G=(V, T, S, P),如果产生式的形式如下:
A -> xB
A -> x其中A, B属于V,x属于T*,则称为右线性文法;相似的,如果产生式的形式如下:
A -> Bx
A -> x则称为左线性文法。右线性文法和左线性文法统称为正则文法。
例子:
G(S):
S->aS|bS
S->aA
A->aB|bB
B->a|b
上下文无关文法通常什么样?
对于文法G=(V, T, S, P),如果产生式的形式如下:
对于任何 0型文法: α -> β :α∈(VN∪VT)* , β∈(VN∪VT)* (可以是符号也可以是字) 1. 在0型文法的基础上,约束满足|β|>=|α|,即1型文法(上下文有关文法)。 2. 在上下文有关文法的基础上,约束满足所有的产生式左边只有一个非终结符。 例子: G(S): S -> aSa|bSbA A -> bA
很显然的上下文无关文法包括了正则文法,是一个更大的范围。
所以由于正则文法的表达能力,它的表述能力有限,而高级语言的语法结构合适用上下文无关文法描述。所以我们需要一套全新的算法来进行语法分析。
对于任何一个上下文无关文法,我们可以构建一个类似于下图的语法树。
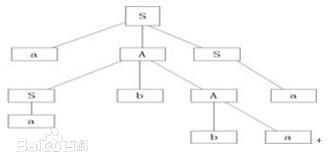
该语法树(将无线递归下去)可以用来表示文法:
G(s):
假设有文法:
S -> xAy
A -> **|*
对于输入串 x**y 匹配过程如下:
1.读第1个字符x,展开S树,发现S有唯一产生式S->xAy。且对于产生式的右边确实有第一个节点是叶结点(终结符),且为x。所以x得到匹配。
2.读第2个字符*,因为S的第一个节点已经处理完毕,于是尝试第二个节点A。发现第二个节点A并不是叶结点。
3.因为A不是叶节点,于是展开A,发现产生式右边有两个项:*和**,他们都满足第一个字符是*,故可能存在两个选择。当第一个选择是错误的时候,就需要回溯。
回溯会带来很多麻烦事:
1.因为语义和语法处理一般同时工作,所以当回头的时候,语义部分的工作都白费了。
2.如果存在了虚假匹配(如题用A->*处理了**的第一个*,后面出错)使得需要复杂的回溯处理。
3.如果分析不成功,我们难于知道输入串出错的确切位置。
如果存在左递归的产生式(如A->Abc),那么因为是处理过程的本质是树的深度遍历,会导致会无穷无尽的递归下去。
P->Pα|β
这意味着 β(α)*
改写成:
P->βP‘
P‘->αP‘|ε
更通用的:
P→Pα1 / Pα2 /…/ Pαn / β1 / β2 /…/βm
其中,αi(I=1,2,…,n)都不为ε,而每个βj(j=1,2,…,m)都不以P开头,将上述规则改写为如下形式即可消除P的直接左递归:
P→β1 P’ / β2 P’ /…/βm P’
P’ →α1P’ / α2 P’ /…/ αn P’ /ε
对于类似于:
S->Qc|c
Q->Rb|b
R->Sa|a
把S->Qc|c中的Q替换成S的表达式,就变成了直接左递归,再按照上述方法处理。
标签:技术 约束 产生 1.5 线性 第一个字符 blog 选择 code
原文地址:http://www.cnblogs.com/TsAihS/p/6811309.html