标签:输入数据 存储结构 规律 运算 tmp 更新 过程 can 不能
使用递归(Recursion)建立二叉树(Binary Tree)的非顺序存储结构(即二叉链表),可以简化算法编写的复杂程度,但是递归效率低,而且容易导致堆栈溢出,因而很有必要使用非递归算法。
无论是单链表还是二叉树,创建时要解决问题就是关系的建立,即单链表中前驱节点与当前节点的关系和二叉树中父节点与子节点的关系。
首先,思考一下建立单链表的过程,为了使链表各个节点连接起来,在创建当前节点(q)的时候,需借助一个指针(p)指向前一个节点,然后p->next = q。
由此推广至二叉树,把二叉树每一层比作是链表的节点,接着借助一个指针列表(parent_list)存放父层的所有节点,然后每创建当前层的一个节点(current_node)时就与父层次的节点建立关系。
引入中提出了创建二叉树的整体思想,同时也抛出一个问题,如何建立父节点与子节点的关系?
下图为一棵普通的二叉树,下面对其进行一些处理。
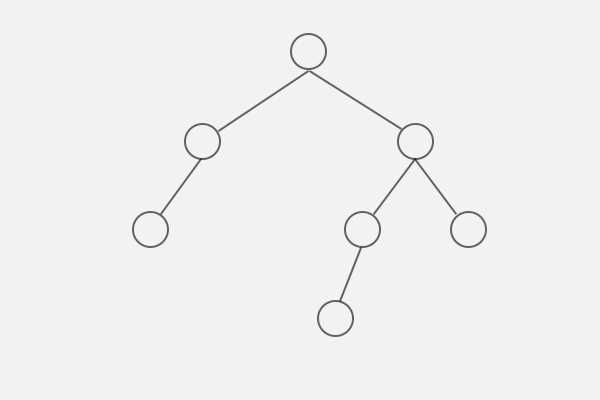
首先,将其补全,用#代表空节点,补全规则为:将只有一个或没有子节点的节点(空节点除外),用空节点补全为两个子节点。
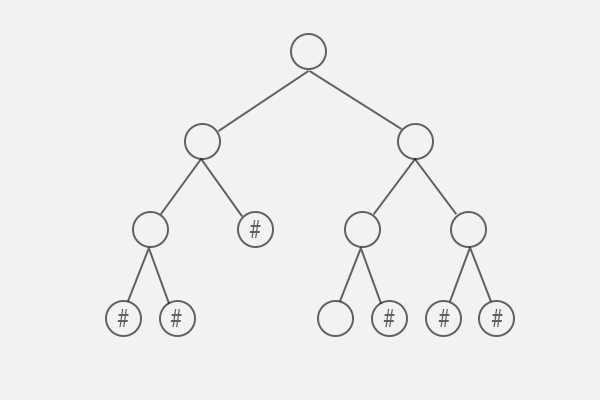
为便于后续分析,将其节点左结构化并去掉关系线。
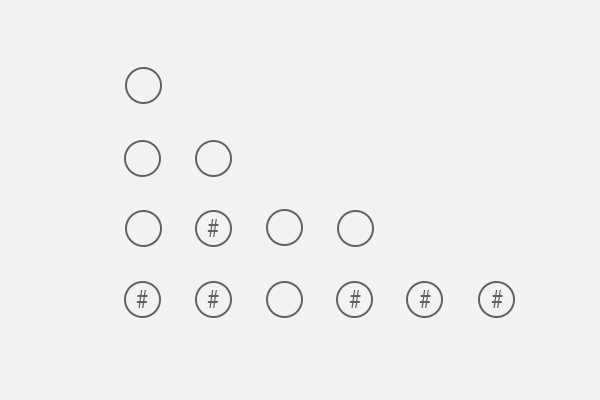
现在,回顾一下引入中提到的“把二叉树每一层比作链表的节点”,而建立单链表每次都只涉及两个节点,因而下面每次分析都只涉及两层。
其中,规定第二层为当前层,第一层为当前层的父层,且当前层为下次分析的父层。
在规定,父层为一个数组p[i](i为父层节点数,后同),当前层为数组q[j]。
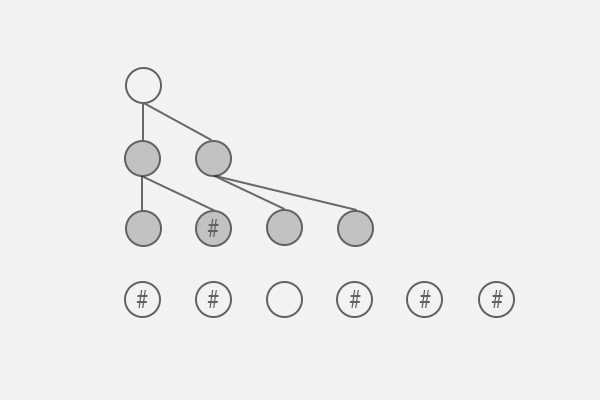
下图为第一次,选中层的节点标记为深灰底色。
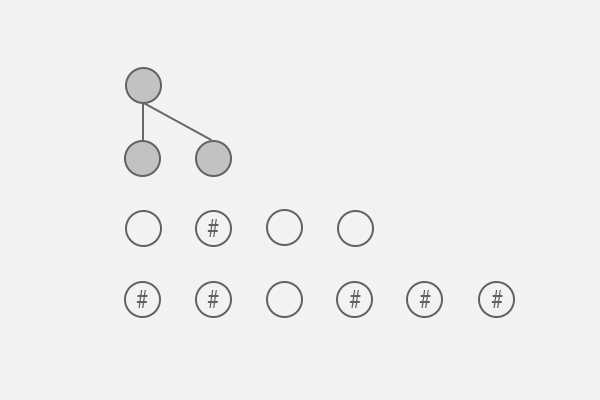
可以容易看出,当前层的两个节点与父层节点的关系:
p[0]->next = q[0]
p[0]->next = q[1]
为其添加关系线,然后再看下一次。
同样,其关系如下:
p[0]->next = q[0]
p[0]->next = q[1] = #
p[1]->next = q[2]
p[2]->next = q[3]
由前两次不难得出,j/2 = i (注意这里 / 运算结果只取整数),这个结果和完全二叉树的性质相同,但是注意这里不是一棵完全二叉树。
接着看下一次。
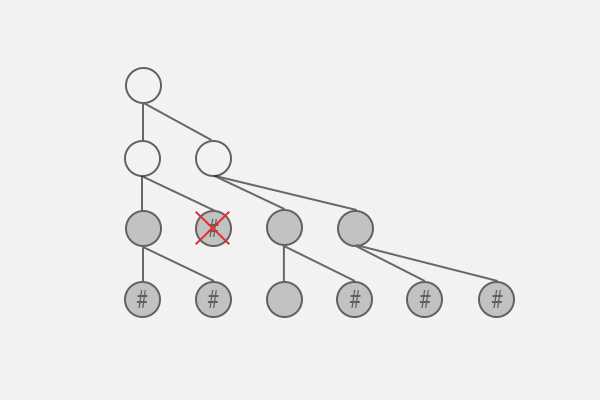
如图所示,为了建立正确的二叉树关系,父层的节点一定不能为空节点。
总观整个结构,可以得出一个规律(该规律可用于动态改变父层列表,以减少内存占用):父层节点数(不包括空节点)的两倍恰好为当前层的节点数(包括空节点)。
此时,还有个小问题,便是判断当前节点是左子树(Left Subtree)还是右子树(Right Subtree)?
这里解决方法很简单,便是计算 j % 2 ,若为0则为左子树,否则为右子树。
现在,理清一下思路:
1.以从上到下、从左到右的顺序创建二叉树,因此有两层循环。
2.有个父层列表(parent_list)用于存放父层所有节点的地址,且外层循环一次就更新一次(即让父层列表等于当前层列表,代码中为tmp_list),同时释放旧父层列表。
3.内层循环创建每一层的节点,若输入数据不为“#”则不为空节点,然后申请内存空间并赋值,再根据上述论述进行父节点和当前节点(current_node)建立关系。
下面给出代码:
1 #include <stdio.h> 2 #include <malloc.h> 3 4 // 布尔类型 5 typedef enum {FALSE=0,TRUE=1} bool; 6 // 用于标识当前建立左子树还是右子树 7 typedef enum {LEFT=0,RIGHT=1} flag; 8 // 节点存放数据的类型 9 typedef char data_type; 10 // 二叉树节点类型 11 typedef struct node { 12 data_type data; 13 struct node *left_subtree, 14 *right_subtree; 15 } node , *bin_tree; 16 17 bool create_bin_tree(bin_tree *root) 18 { 19 /* 创建根节点 */ 20 data_type data = ‘\0‘; 21 scanf("%c",&data); 22 if(data == ‘#‘){ 23 return FALSE; // 根节点为空,创建失败 24 } 25 else 26 { 27 *root = (node*)malloc(sizeof(node)); 28 (*root)->data = data; 29 (*root)->left_subtree = NULL; 30 (*root)->right_subtree = NULL; 31 } 32 33 /* 创建非根节点 */ 34 // 存放父层的节点列表 35 node **parent_list = (node**)malloc(sizeof(node*)); 36 parent_list[0] = *root; 37 // 父节点个数 38 int parent_amount = 1; 39 40 while(1) 41 { 42 // 当前节点个数,设置为父节点个数的两倍 43 int current_amount = parent_amount * 2; 44 // 创建临时列表存放当前深度的节点 45 node **tmp_list = (node**)malloc(sizeof(node*) 46 * current_amount); 47 // 用于记录当前深度节点非空节点个数 48 int count = 0; 49 // 创建当前层次的所有节点 50 int j = 0; 51 for(;j < current_amount;++j) 52 { 53 data = ‘\0‘; 54 scanf("%c",&data); 55 if(data != ‘#‘) // 不为空节点 56 { 57 // 新建节点并赋值 58 node *current_node = (node*)malloc(sizeof(node)); 59 current_node->data = data; 60 current_node->left_subtree = NULL; 61 current_node->right_subtree = NULL; 62 // 加入到临时列表中 63 tmp_list[count] = current_node; 64 // 非空节点数加1 65 count++; 66 // 与父节点建立关系 67 if(j%2 == LEFT) 68 { 69 (parent_list[j/2])->left_subtree = current_node; 70 } 71 else 72 { 73 (parent_list[j/2])->right_subtree = current_node; 74 } 75 } 76 } // for循环结束 77 78 // 释放父层列表 79 free(parent_list); 80 // 更新父层列表 81 parent_list = tmp_list; 82 // 若非空节点数为0,则停止创建 83 if(count == 0) break; 84 } 85 return TRUE; 86 }
上述代码中,由于根节点较特殊且需要传出地址,为了降低代码编写复杂程度,因而独立于内层循环。
写文章除了用于记录外,其实也无形中能理清想问题的思路。如写这篇文章前,代码虽实现了,但总感觉思路很乱。而文章写完了,便也豁然开朗了。
标签:输入数据 存储结构 规律 运算 tmp 更新 过程 can 不能
原文地址:http://www.cnblogs.com/linzhehuang/p/6822847.html