1.为了区分预处理指令和一般的C语句,所有预处理指令都以符号"#"开头,并且结尾不用分号
2.C语言提供的预处理指令主要有:宏定义、文件包含、条件编译
#define 宏名 字符串
比如#define ABC 10
右边的字符串也可以省略,比如#define ABC
它的作用是在编译预处理时,将源程序中所有"宏名"替换成右边的"字符串",常用来定义常量。
接下来写个程序根据圆的半径计算周长

1 #include <stdio.h>
2
3 // 源程序中所有的宏名PI在编译预处理的时候都会被3.14所代替
4 #define PI 3.14
5
6 // 根据圆的半径计radius算周长
7 float girth(float radius) {
8 return 2 * PI *radius;
9 }
10
11 int main ()
12 {
13 float g = girth(2);
14
15 printf("周长为:%f", g);
16 return 0;
17 }
在第4行定义了一个叫PI的宏,在编译预处理之后,第8行中的2 * PI *radius就会变成2 * 3.14 * radius。
输出结果: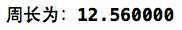
1> 宏名一般用大写字母,以便与变量名区别开来,但用小写也没有语法错误
2> 对程序中用双引号扩起来的字符串内的字符,不进行宏的替换操作。比如:
1 #define R 10
2 int main ()
3 {
4 char *s = "Radio";
5 return 0;
6 }
在第1行定义了一个叫R的宏,但是第4行中"Radio"里面的‘R‘并不会被替换成10
3> 在编译预处理用字符串替换宏名时,不作语法检查,只是简单的字符串替换。只有在编译的时候才对已经展开宏名的源程序进行语法检查
1 #define I 100
2 int main ()
3 {
4 int i[3] = I;
5 return 0;
6 }
在做编译预处理的时候,不管语法对不对,第4行的I都会被替换为100。不过在编译的时候就会报第4行的错。
4> 宏名的有效范围是从定义位置到文件结束。如果需要终止宏定义的作用域,可以用#undef命令
1 #define PI 3.14 2 /* 3 . 4 . 5 . 6 . 7 */ 8 #undef PI
PI这个宏在第1行到第8行之间是有效的,第8行后就无效了
5> 定义一个宏时可以引用已经定义的宏名
#define R 3.0 #define PI 3.14 #define L 2*PI*R #define S PI*R*R
#define 宏名(参数列表) 字符串
在编译预处理时,将源程序中所有宏名替换成字符串,并且将 字符串中的参数 用 宏名右边参数列表 中的参数替换
1 #include <stdio.h>
2
3 #define average(a, b) (a+b)/2
4
5 int main ()
6 {
7 int a = average(10, 4);
8
9 printf("平均值:%d", a);
10 return 0;
11 }
第3行中定义了一个带有2个参数的宏average,第7行其实会被替换成:int a = (10 + 4)/2;,输出结果为: 。是不是感觉这个宏有点像函数呢?
。是不是感觉这个宏有点像函数呢?
1> 宏名和参数列表之间不能有空格,否则空格后面的所有字符串都作为替换的字符串
1 #define average (a, b) (a+b)/2
2
3 int main ()
4 {
5 int a = average(10, 4);
6 return 0;
7 }
注意第1行的宏定义,宏名average跟(a, b)之间是有空格的,于是,第5行就变成了这样:
int a = (a, b) (a+b)/2(10, 4);
这个肯定是编译不通过的
2> 带参数的宏在展开时,只作简单的字符和参数的替换,不进行任何计算操作。所以在定义宏时,一般用一个小括号括住字符串的参数。
下面定义一个宏D(a),作用是返回a的2倍数值:
如果定义宏的时候不用小括号括住参数
1 #include <stdio.h>
2
3 #define D(a) 2*a
4
5 int main ()
6 {
7 int b = D(3+4);
8
9 printf("%d", b);
10 return 0;
11 }
第7行将被替换成int b = 2*3+4;,输出结果: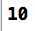
如果定义宏的时候用小括号括住参数,把上面的第3行改成:
#define D(a) 2*(a)
注意右边的a是有括号的,第7行将被替换成int b = 2*(3+4);,输出结果: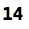
3> 计算结果最好也用括号括起来
下面定义一个宏P(a),作用是返回a的平方:
如果不用小括号括住计算结果
1 #include <stdio.h>
2
3 #define Pow(a) (a) * (a)
4
5 int main(int argc, const char * argv[]) {
6 int b = Pow(10) / Pow(2);
7
8 printf("%d", b);
9 return 0;
10 }
注意第3行,没有用小括号扩住计算结果,只是括住了参数而已。第6行代码被替换为:
int b = (10) * (10) / (2) * (2);
简化之后:int b = 10 * (10 / 2) * 2;,最后变量b为: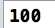
如果用小括号括住计算结果
将上面的第3行代码改为:
#define Pow(a) ( (a) * (a) )
那么第6行被替换为:
int b = ( (10) * (10) ) / ( (2) * (2) );
简化之后:int b = (10 * 10) / (2 * 2);,最后输出结果: 。这个才是我们想要的结果。
。这个才是我们想要的结果。
也就意味着前面的#define average(a, b) (a+b)/2应该写成#define average(a, b) (((a)+(b))/2)
从整个使用过程可以发现,带参数的宏定义,在源程序中出现的形式与函数很像。但是两者是有本质区别的:
1> 宏定义不涉及存储空间的分配、参数类型匹配、参数传递、返回值问题
2> 函数调用在程序运行时执行,而宏替换只在编译预处理阶段进行。所以带参数的宏比函数具有更高的执行效率
在很多情况下,我们希望程序的其中一部分代码只有在满足一定条件时才进行编译,否则不参与编译(只有参与编译的代码最终才能被执行),这就是条件编译。
#if 和 #elif后面的条件不仅仅可以用来判断宏的值,还可以判断是否定义过某个宏。比如:
1 #if defined(MAX) 2 ...code... 3 #endif
如果前面已经定义过MAX这个宏,就将code编译进去。它不会管MAX的值是多少,只要定义过MAX,条件就成立。
条件也可以取反:
1 #if !defined(MAX) 2 ...code... 3 #endif
如果前面没有定义过MAX这个宏,就将code编译进去。
* #ifdef的使用和#if defined()的用法基本一致
* #ifndef又和#if !defined()的用法基本一致
这讲介绍最后一个预处理指令---文件包含
其实我们早就有接触文件包含这个指令了, 就是#include,它可以将一个文件的全部内容拷贝另一个文件中。
直接到C语言库函数头文件所在的目录中寻找文件
系统会先在源程序当前目录下寻找,若找不到,再到操作系统的path路径中查找,最后才到C语言库函数头文件所在目录中查找
1.#include指令允许嵌套包含,比如a.h包含b.h,b.h包含c.h,但是不允许递归包含,比如 a.h 包含 b.h,b.h 包含 a.h。
下面的做法是错误的
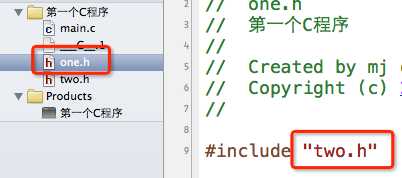
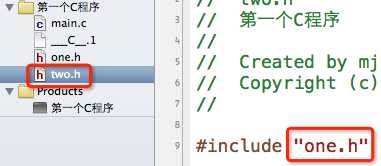
2.使用#include指令可能导致多次包含同一个头文件,降低编译效率
比如下面的情况:
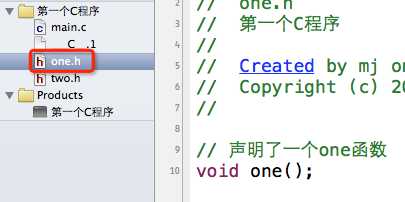
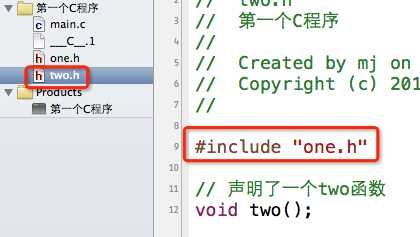
在one.h中声明了一个one函数;在two.h中包含了one.h,顺便声明了一个two函数。(这里就不写函数的实现了,也就是函数的定义)
假如我想在main.c中使用one和two两个函数,而且有时候我们并不一定知道two.h中包含了one.h,所以可能会这样做:
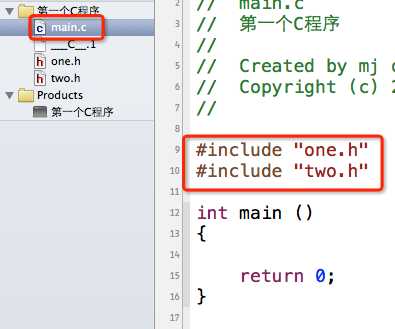
编译预处理之后main.c的代码是这样的:
1 void one();
2 void one();
3 void two();
4 int main ()
5 {
6
7 return 0;
8 }
第1行是由#include "one.h"导致的,第2、3行是由#include "two.h"导致的(因为two.h里面包含了one.h)。可以看出来,one函数被声明了2遍,根本就没有必要,这样会降低编译效率。
为了解决这种重复包含同一个头文件的问题,一般我们会这样写头文件内容:
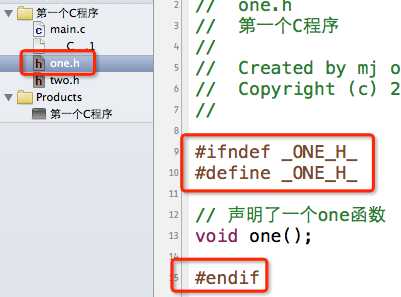
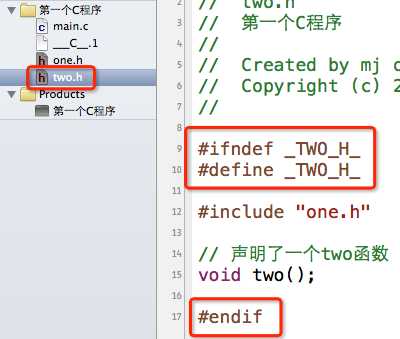
大致解释一下意思,就拿one.h为例:当我们第一次#include "one.h"时,因为没有定义_ONE_H_,所以第9行的条件成立,接着在第10行定义了_ONE_H_这个宏,然后在13行声明one函数,最后在15行结束条件编译。当第二次#include "one.h",因为之前已经定义过_ONE_H_这个宏,所以第9行的条件不成立,直接跳到第15行的#endif,结束条件编译。就是这么简单的3句代码,防止了one.h的内容被重复包含。
这样子的话,main.c中的:
#include "one.h" #include "two.h"
就变成了:
1 // #include "one.h" 2 #ifndef _ONE_H_ 3 #define _ONE_H_ 4 5 void one(); 6 7 #endif 8 9 // #include "two.h" 10 #ifndef _TWO_H_ 11 #define _TWO_H_ 12 13 // #include "one.h" 14 #ifndef _ONE_H_ 15 #define _ONE_H_ 16 17 void one(); 18 19 #endif 20 21 void two(); 22 23 #endif
第2~第7行是#include "one.h"导致的,第10~第23行是#include "two.h"导致的。编译预处理之后就变为了:
1 void one(); 2 void two();
这才是我们想要的结果
原文地址:http://12879490.blog.51cto.com/12869490/1923499