标签:兴趣 int XML 抓取 result lis href 结果 pre
上篇给大家介绍了Python爬虫索要爬去的源网站及所需的软件,本篇开始,将正式的开始爬取数据。
1、简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。
2、安装 Beautiful Soup
pip install beautifulsoup4
然后需要安装 lxml
pip install lxml
1 # coding = utf-8 2 3 import urllib 4 import urllib.request 5 from bs4 import BeautifulSoup 6 7 8 def getCityLinks(): 9 url = ‘http://lishi.tianqi.com/‘ 10 response = urllib.request.urlopen(url, timeout=20) 11 result = response.read() 12 soup = BeautifulSoup(result, "lxml") 13 print(soup) 14 getCityLinks()
运行代码:
结果:
# coding = utf-8 import urllib import urllib.request from bs4 import BeautifulSoup def getCityLinks(): url = ‘http://lishi.tianqi.com/‘ response = urllib.request.urlopen(url, timeout=20) result = response.read() soup = BeautifulSoup(result, "lxml") links = soup.select("ul > li > a") for a in links: print(a) getCityLinks()
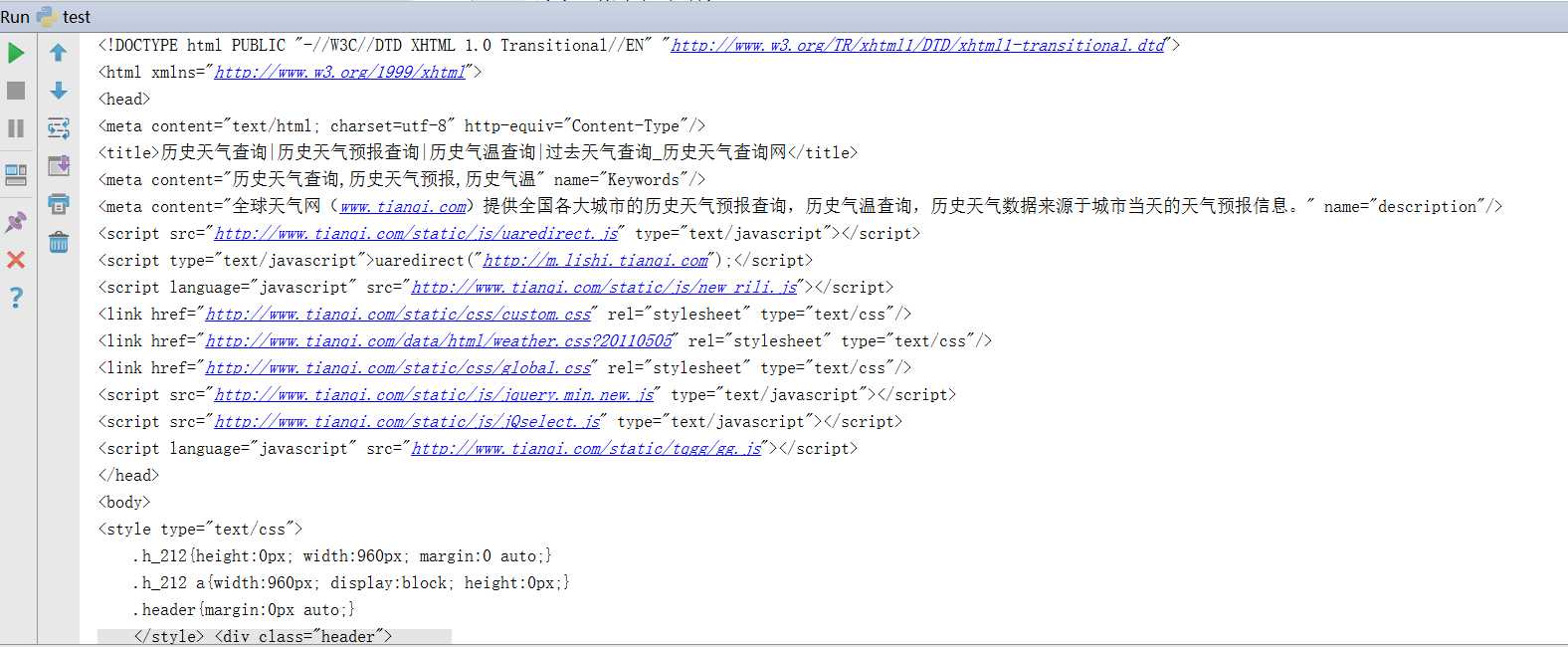
至此我们已经获取了网页的源代码,下一步我们索要做的就是提取我们感兴趣的信息。
我们的目标数据为城市信息,且都是a标签,分析html结构,使用 soup.select("ul > li > a") 提取符合该条件下的所有a标签
# coding = utf-8 import urllib import urllib.request from bs4 import BeautifulSoup def getCityLinks(): url = ‘http://lishi.tianqi.com/‘ response = urllib.request.urlopen(url, timeout=20) result = response.read() soup = BeautifulSoup(result, "lxml") links = soup.select("ul > li > a") for a in links: print(a) getCityLinks()
再一次运行,得到如下数据。

并不是所有的a标签都是我们需要的数据,因此再次过滤。
# coding = utf-8 import urllib import urllib.request from bs4 import BeautifulSoup def getCityLinks(): url = ‘http://lishi.tianqi.com/‘ response = urllib.request.urlopen(url, timeout=20) result = response.read() soup = BeautifulSoup(result, "lxml") links = soup.select("ul > li > a") for a in links: if a.get_text() + ‘历史天气‘ == a.get(‘title‘): city = a.get_text() url = a.get(‘href‘) print(a) getCityLinks()
再次运行后,得到的结果才是我们想要的。

标签:兴趣 int XML 抓取 result lis href 结果 pre
原文地址:http://www.cnblogs.com/yansg/p/6830393.html