标签:绑定 全分布式 hand sha property creat under node 一半
经过一系列的前期环境准备,现在可以开始Hadoop的安装了,在这里去apache官网下载2.7.3的版本 http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
不需要下载最新的3.0版本, 与后续Hive最新版本有冲突,不知道是不是自己的打开方式不对。
hadoop有三种运行方式:单机、伪分布式、完全分布式,本文介绍完全分布式。
现在有三个机器,一个Master H32,两个Slaver H33、H34。
将下载的压缩包上传到解压并移动至Master机器的相应目录。
将软件放置/usr/local目录下:
tar -zxvf hadoop-2.7.3.tar.gz mv hadoop-2.7.3 hadoop273
[root@H32 local]# groupadd hadoop #添加hadoop组 [root@H32 local]# useradd -g hadoop hadoop -s /bin/false
将该hadoop文件夹的属主用户设为hadoop
sudo chown -R hadoop:hadoop /usr/local/hadoop273
配置文件之前先大体介绍一下hadoop2目录中的各个文件夹,注意区分与Hadoop1中的改变。
外层的启动脚本在sbin目录
内层的被调用脚本在bin目录
Native的so文件都在lib/native目录
配置程序文件都放置在libexec
配置文件都在etc目录,对应以前版本的conf目录
所有的jar包都在share/hadoop目录下面
mkdir -p /usr/local/hadoop273/hdfs/name
mkdir -p /usr/local/hadoop273/hdfs/data
若不配置,Hadoop默认将数据存储在tmp文件夹中,重启会清空tmp数据,因此单独配置其数据存储文件夹,具体使用配置在下面XML中。
/etc/profile 增加如下内容:
export HADOOP_HOME=/usr/local/hadoop273 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export HADOOP_MAPARED_HOME=${HADOOP_HOME} export HADOOP_COMMON_HOME=${HADOOP_HOME} export HADOOP_HDFS_HOME=${HADOOP_HOME} export HADOOP_YARN_HOME=${HADOOP_HOME} export YARN_HOME=${HADOOP_HOME} export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export HDFS_CONF_DIR=${HADOOP_HOME}/etc/hadoop export LD_LIBRARY_PATH=${HADOOP_HOME}/lib/native/:$LD_LIBRARY_PATH export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
执行执行source /etc/profile,使之生效
$HADOOP_HOME/etc/hadoop/slaves (Master主机特有,子节点可以不加)
H33
H34
或写对应的IP
192.168.80.33
192.168.80.34
export JAVA_HOME=/usr/local/java/jdk1.8.0_101
让环境变量配置生效source
source /usr/local/hadoop3/etc/hadoop/hadoop-env.sh
Hadoop配置文件在conf目录下,之前的版本的配置文件主要是Hadoop-default.xml和Hadoop-site.xml。
由于Hadoop发展迅速,代码量急剧增加,代码开发分为了core,hdfs和map/reduce三部分,配置文件也被分成了三个core-site.xml、hdfs-site.xml、mapred-site.xml。
core-site.xml和hdfs-site.xml是站在HDFS角度上配置文件;core-site.xml和mapred-site.xml是站在MapReduce角度上配置文件。
<configuration> <property> <name>fs.default.name</name> <value>hdfs://H32:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop273/hadoop_tmp</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.sqoop2.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.sqoop2.groups</name> <value>*</value> </property> </configuration>
单独创建tmp文件夹hadoop_tmp 给 hadoop.tmp.dir 用于跟普通数据隔离。
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>H32:9001</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.tmp.dir</name> <value>/usr/local/hadoop273/hadoop_tmp</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop273/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop273/hdfs/data</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.datanode.max.xcievers</name> <value>4096</value> </property> </configuration>
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value>/usr/local/hadoop273/etc/hadoop,/usr/local/hadoop273/share/hadoop/common/*,/usr/local/hadoop273/share/hadoop/common/lib/*,/usr/local/hadoop273/share/hadoop/hdfs/*,/usr/local/hadoop273/share/hadoop/hdfs/lib/*,/usr/local/hadoop273/share/hadoop/mapreduce/*,/usr/local/hadoop273/share/hadoop/mapreduce/lib/*,/usr/local/hadoop273/share/hadoop/yarn/*,/usr/local/hadoop273/share/hadoop/yarn/lib/*</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>H32:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>H32:19888</value> </property> <property> <name>mapreduce.map.memory.mb</name> <value>1536</value> </property> <property> <name>mapreduce.map.java.opts</name> <value>-Xmx3072M</value> </property> <property> <name>mapreduce.reduce.memory.mb</name> <value>3072</value> </property> <property> <name>mapreduce.reduce.java.opts</name> <value>-Xmx6144M</value> </property> <property> <name>mapreduce.cluster.map.memory.mb</name> <value>-1</value> </property> <property> <name>mapreduce.cluster.reduce.memory.mb</name> <value>-1</value> </property> </configuration>
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.address</name> <value>H32:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>H32:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>H32:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>H32:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>H32:8088</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>mapreduce.application.classpath</name> <value>/usr/local/hadoop273/etc/hadoop,/usr/local/hadoop273/share/hadoop/common/*,/usr/local/hadoop273/share/hadoop/common/lib/*,/usr/local/hadoop273/share/hadoop/hdfs/*,/usr/local/hadoop273/share/hadoop/hdfs/lib/*,/usr/local/hadoop273/share/hadoop/mapreduce/*,/usr/local/hadoop273/share/hadoop/mapreduce/lib/*,/usr/local/hadoop273/share/hadoop/yarn/*,/usr/local/hadoop273/share/hadoop/yarn/lib/*</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>3</value> </property> </configuration>
注意黄色标志,要classpath一定是绝对路径,不要用$HADOOP_HOME,运行会一直提示找不到相关类错误,至此master节点的hadoop搭建完毕。
现在在Master机器上的Hadoop配置就结束了,剩下的就是配置Slave机器上的Hadoop。
将 Master上配置好的hadoop所在文件夹"/usr/local/hadoop273"复制到所有的Slave的"/usr/local"目录下(实际上Slave机器上的slavers文件是不必要的, 复制了也没问题)。用下面命令格式进行。(备注:此时用户可以为hadoop也可以为root)
把H32的hadoop目录下的logs和tmp删除,再把H32中的jdk、hadoop文件夹复制到H33和H34节点
scp -r /usr/local/hadoop273 root@H33:/usr/local
例如:从"Master.Hadoop"到"Slave1.Hadoop"复制配置Hadoop的文件。
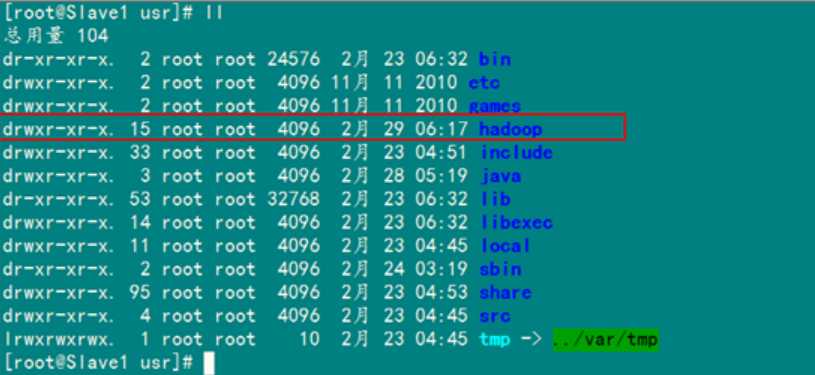
上图中以root用户进行复制,当然不管是用户root还是hadoop,虽然Master机器上的"/usr/local/hadoop273"文件夹用户hadoop有权限,但是Slave1上的hadoop用户却没有"/usr/local"权限,所以没有创建文件夹的权限。所以无论是哪个用户进行拷贝,右面都是"root@机器IP"格式。因为我们只是建立起了hadoop用户的SSH无密码连接,所以用root进行"scp"时,扔提示让你输入"Slave1.Hadoop"服务器用户root的密码。
查看"Slave1.Hadoop"服务器的"/usr/local"目录下是否已经存在"hadoop"文件夹,确认已经复制成功。
hadoop文件夹确实已经复制了,但是我们发现hadoop权限是root,所以我们现在要给"Slave1.Hadoop"服务器上的用户hadoop添加对"/usr/local/hadoop"读权限。
以上配置完成后,将hadoop整个文件夹复制到其他机器。
hdfs namenode -format 只需一次,下次启动不再需要格式化,只需 start-all.sh
若没有设置路径$HADOOP_HOME/bin为环境变量,则需在$HADOOP_HOME路径下执行
bin/hdfs namenode -format
start-dfs.sh 在启动前关闭集群中所有机器的防火墙,不然会出现datanode开后又自动关闭(暂未发现) service iptables stop
start-yarn.sh
若没有设置路径$HADOOP_HOME/sbin为环境变量,则需在$HADOOP_HOME路径下执行
sbin/start-dfs.sh sbin/start-yarn.sh
或 直接start-all.sh都启动
另外还要启动history服务,不然在面板中不能打开history链接。
sbin/mr-jobhistory-daemon.sh start historyserver
停止集群
sbin/stop-dfs.sh sbin/stop-yarn.sh 或 直接stop-all.sh
下面使用jps命令查看启动进程:
4504 ResourceManager
4066 DataNode
4761 NodeManager
5068 JobHistoryServer
4357 SecondaryNameNode
3833 NameNode
5127 Jps
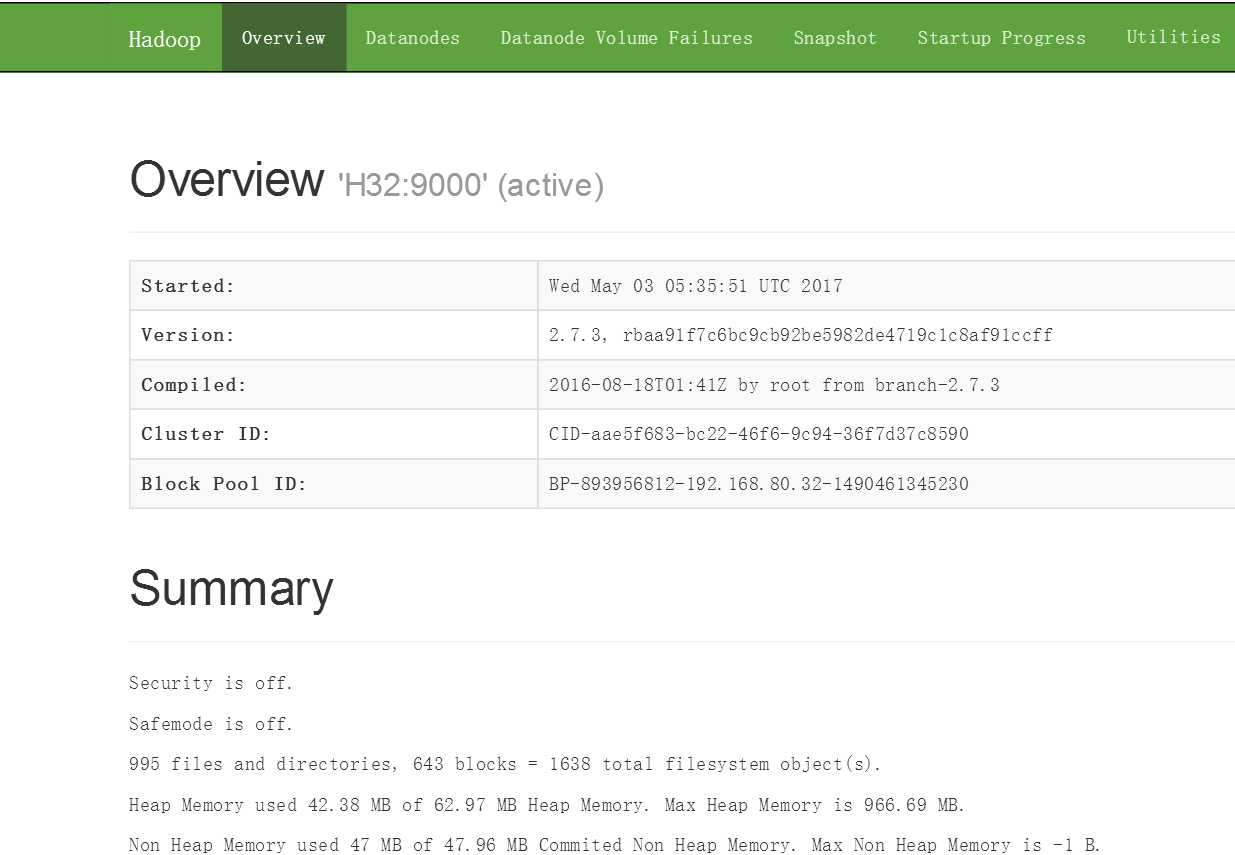
现在便可以打开页面http://192.168.80.32:8088及http://192.168.80.32:50070;看到下面两个页面时说明安装成功。

在root中创建文件:
~/hadoop-test-data.txt
向hdfs中上传文件:
bin/hadoop fs -put ~/hadoop-test-data.txt /tmp/input
查看hdfs文件目录:
hdfs dfs –ls /
移除文件命令:
hadoop fs -rm -r /tmp/input
运行WordCount测试程序,output为输出文件。
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /tmp/input output
运行过程出现下面内容,没有错误提示说明正常:
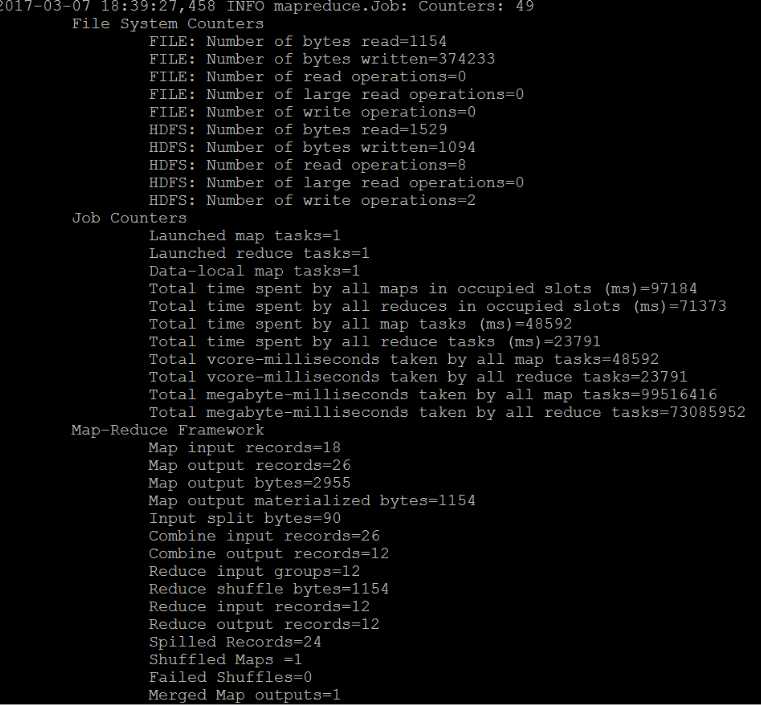
查看生成列表,会有两个文件,主要查看part-r-00000
hadoop fs -ls output/

hadoop fs -cat output/part-r-00000
hadoop 1
hello 2
java 4
jsp 1
到这里,hadoop-2环境搭建结束,配置文件根据具体需求,具体配置。
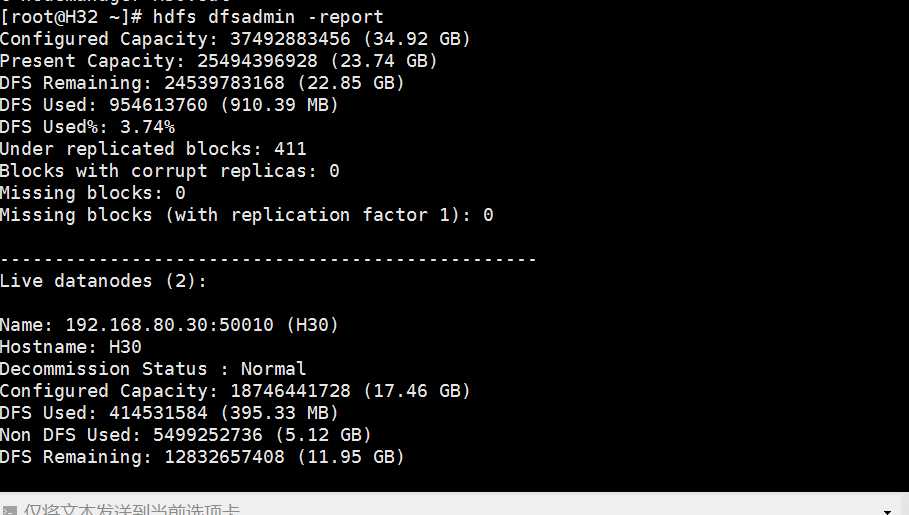
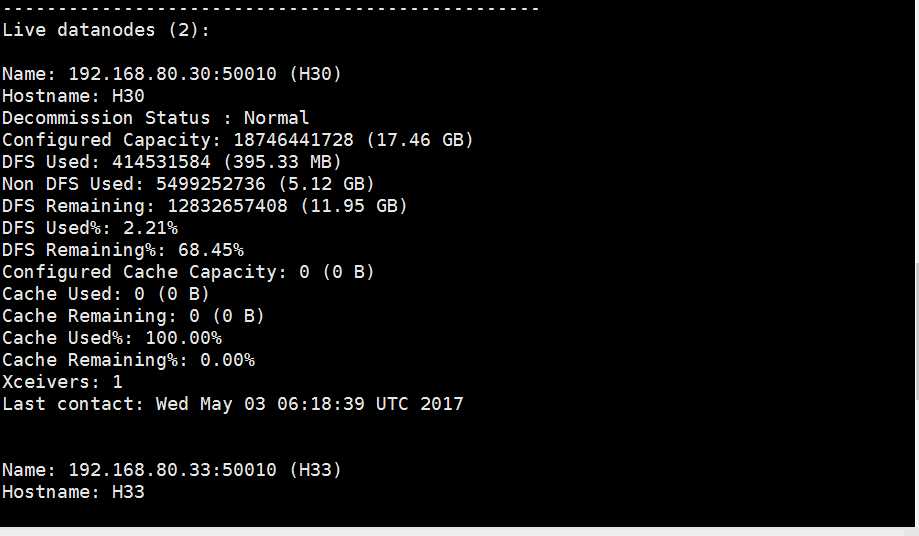
[root@H32 hadoop273]$ ./bin/hdfs dfsadmin -report


以下列布署过程中遇到的几个常见问题,加了网上一些网友的内容。
当停止Hadoop时发现如下信息:
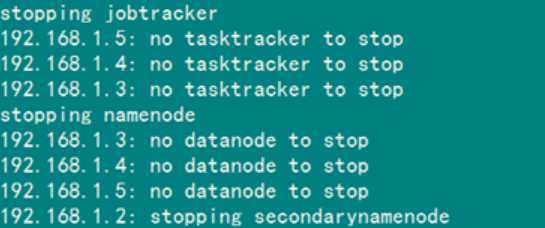
原因:每次namenode format会重新创建一个namenodeId,而tmp/dfs/data下包含了上次format下的id,namenode format清空了namenode下的数据,但是没有清空datanode下的数据,导致启动时失败,所要做的就是每次fotmat前,清空tmp一下的所有目录。
第一种解决方案如下:
1)先删除"/usr/hadoop/tmp"
rm -rf /usr/hadoop/tmp
2)创建"/usr/hadoop/tmp"文件夹
mkdir /usr/hadoop/tmp
3)删除"/tmp"下以"hadoop"开头文件
rm -rf /tmp/hadoop*
4)重新格式化hadoop
hadoop namenode -format
5)启动hadoop
start-all.sh
使用第一种方案,有种不好处就是原来集群上的重要数据全没有了。假如说Hadoop集群已经运行了一段时间。建议采用第二种。
第二种方案如下:
1)修改每个Slave的namespaceID使其与Master的namespaceID一致。
或者
2)修改Master的namespaceID使其与Slave的namespaceID一致。
该"namespaceID"位于"/usr/hadoop/tmp/dfs/data/current/VERSION"文件中,前面蓝色的可能根据实际情况变化,但后面红色是不变的。
例如:查看"Master"下的"VERSION"文件

本人建议采用第二种,这样方便快捷,而且还能防止误删。
查看日志发下如下错误。
ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: java.io.IOException: Call to ... failed on local exception: java.net.NoRouteToHostException: No route to host
解决方案是:关闭防火墙
service iptables stop
从本地往hdfs文件系统上传文件
出现如下错误:
INFO hdfs.DFSClient: Exception in createBlockOutputStream java.io.IOException: Bad connect ack with firstBadLink
INFO hdfs.DFSClient: Abandoning block blk_-1300529705803292651_37023
WARN hdfs.DFSClient: DataStreamer Exception: java.io.IOException: Unable to create new block.
解决方案是:
1)关闭防火墙
service iptables stop
2)禁用selinux
编辑 "/etc/selinux/config"文件,设置"SELINUX=disabled"
处理速度特别的慢
出现map很快,但是reduce很慢,而且反复出现"reduce=0%"。
解决方案如下:
结合解决方案5.7,然后修改"conf/hadoop-env.sh"中的"export HADOOP_HEAPSIZE=4000"
解决hadoop OutOfMemoryError问题
出现这种异常,明显是jvm内存不够得原因。
解决方案如下:要修改所有的datanode的jvm内存大小。
Java –Xms 1024m -Xmx 4096m
一般jvm的最大内存使用应该为总内存大小的一半,我们使用的8G内存,所以设置为4096m,这一值可能依旧不是最优的值。
Namenode in safe mode
解决方案如下:
bin/hadoop dfsadmin -safemode leave
IO写操作出现问题
0-1246359584298, infoPort=50075, ipcPort=50020):Got exception while serving blk_-5911099437886836280_1292 to /172.16.100.165:
java.net.SocketTimeoutException: 480000 millis timeout while waiting for channel to be ready for write. ch : java.nio.channels.SocketChannel[connected local=/
172.16.100.165:50010 remote=/172.16.100.165:50930]
at org.apache.hadoop.net.SocketIOWithTimeout.waitForIO(SocketIOWithTimeout.java:185)
at org.apache.hadoop.net.SocketOutputStream.waitForWritable(SocketOutputStream.java:159)
……
It seems there are many reasons that it can timeout, the example given in HADOOP-3831 is a slow reading client.
解决方案如下:
在hadoop-site.xml中设置dfs.datanode.socket.write.timeout=0
java.net.NoRouteToHostException: No Route to Host from H32/192.168.80.32 to H30:40080 failed on socket timeout exception: java.net.NoRouteToHostException: 没有到主机的路由;
关闭to H30的防火墙,或不能访问H30服务器,重启H30
This token is expired. current time is 1489243761235 found 1489239661109
Note: System times on machines may be out of sync. Check system time and time zones.
两个主机的时间不一致,重置两个主机的时间,重置方法网上有很多。
启动hadoop时没有NameNode的可能原因:
(1) NameNode没有格式化
(2) 环境变量配置错误
(3) Ip和hostname绑定失败
(4)hostname含有特殊符号如何.(符号点),会被误解析
地址占用
报错:org.apache.hadoop.hdfs.server.namenode.NameNode: Address already in use
解决方法:查找被占用的端口号对应的PID:netstat –tunl
Pkill -9 PID
实在不行就killall -9 java
标签:绑定 全分布式 hand sha property creat under node 一半
原文地址:http://www.cnblogs.com/zhangs1986/p/6798544.html