标签:task spi art 解析 img image shuffle 输出 src
MapReduce内部逻辑
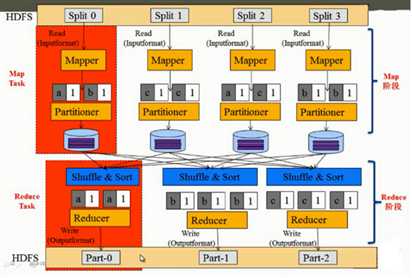
Split:HDFS 中的数据以 Split 方式作为 MapReduce 的输入
Block 是 HDFS 术语,Split 是 MapReduce 术语 通常1个 Split 对应1个 block,也可能对应多个block,具体是由 InputFormat 和压缩格式决定的
默认情况下,使用的是TextInputFormat,这时1个Split对应1个block,上图4个Split对应4个Block
Mapper解析出的数据输出到本地磁盘上
Map阶段由一批同时运行的Map Task 组成,每个 Map Task由3个部分组成:
InputFormat:对输入数据格式进行解析,默认为TextInputFormat,key代表每行偏移量,value代表每行数据内容。
Mapper:输入数据处理 Partitioner:数据分组, Mapper 的输出key会经过
Partitioner 分组选择不同的Reduce。默认Partitioner 会对 map 输出的key进行hash取模,比如有6个Reduce Task,它就是模(mod)6,如果key的hash值为0,就选择第0个 Reduce Task。这样不同的map 对相同key,它的 hash 值取模是一样的
Reduce 阶段由一批同时运行的 Reduce Task 组成,每个 Reduce Task由4个部分组成:
Shuffle: Reduce Task 远程拷贝每个 map 处理的结果,从每个 map 中读取一部分结果,每个 Reduce Task 拷贝哪些数据,是由 Partitioner 决定的
Sort:读取完数据后,会按照key排序,相同的key被分到一组
Reducer:数据处理,以WordCount为例,对相同的key计词频数 OutputFormat:数据输出格式, Reducer 的结果将按照
OutputFormat 格式输出,默认为 TextOutputFormat ,以WordCount为例,这里的key为单词,value为词频数
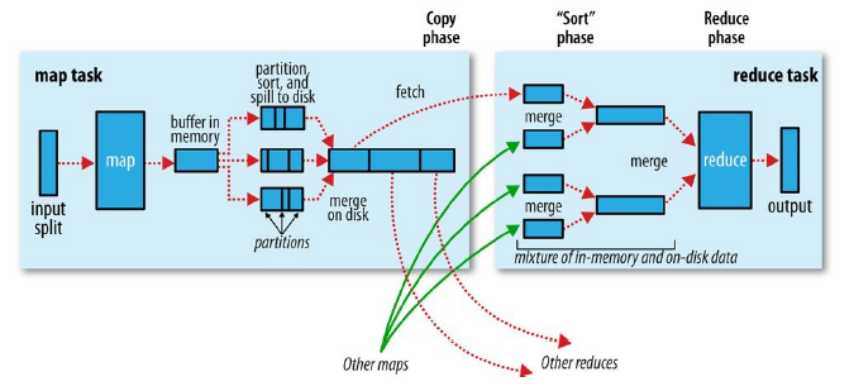
缓冲区默认为100M,由io.sort.mb属性控制
缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),写磁盘,最后合并,reduce端也一样,reduce端拿到的map端数据是按key排序
标签:task spi art 解析 img image shuffle 输出 src
原文地址:http://www.cnblogs.com/fast-walking/p/6837958.html