第 1 行包含 1 个正整数 n ,表示鸡尾酒的杯数。
第 2 行包含一个长度为 n 的字符串 S,其中第 i 个字符表示第 i 杯酒的标签。
第 3 行包含 n 个整数,相邻整数之间用单个空格隔开,其中第 i 个整数表示第 i 杯酒的美味度 ai 。
标签:思路 oid 完全 字母 nlogn 理解 get 包括 com
讲道理是后缀数组裸题吧,虽然知道后缀数组的原理但是小C不会写是什么鬼。。
小C趁着做这题的当儿,学习了一下后缀数组。
网络上的后缀数组模板完全看不懂怎么破,全程照着黄学长的代码抄,感觉黄学长写得还是很优雅的。
求LCP的部分已经崩坏了,小C自己脑补的做法是。。倍增??
看到正确的写法之后小C内心是绝望的,大致意思是:在原字符串中,设相邻两个后缀为Sx、Sx+1,那么有height[x+1]>=height[x]-1。(height数组就是小C代码里的tp数组)
一年一度的“幻影阁夏日品酒大会”隆重开幕了。大会包含品尝和趣味挑战两个环节,分别向优胜者颁发“首席品酒家”和“首席猎手”两个奖项,吸引了众多品酒师参加。在大会的晚餐上,调酒师 Rainbow 调制了 n 杯鸡尾酒。这 n 杯鸡尾酒排成一行,其中第 n 杯酒 (1 ≤ i ≤ n) 被贴上了一个标签si,每个标签都是 26 个小写 英文字母之一。设 str(l, r)表示第 l 杯酒到第 r 杯酒的 r ? l + 1 个标签顺次连接构成的字符串。若 str(p, po) = str(q, qo),其中 1 ≤ p ≤ po ≤ n, 1 ≤ q ≤ qo ≤ n, p ≠ q, po ? p + 1 = qo ? q + 1 = r ,则称第 p 杯酒与第 q 杯酒是“ r 相似” 的。当然两杯“ r 相似”(r > 1)的酒同时也是“ 1 相似”、“ 2 相似”、……、“ (r ? 1) 相似”的。特别地,对于任意的 1 ≤ p , q ≤ n , p ≠ q ,第 p 杯酒和第 q 杯酒都 是“ 0 相似”的。
在品尝环节上,品酒师 Freda 轻松地评定了每一杯酒的美味度,凭借其专业的水准和经验成功夺取了“首席品酒家”的称号,其中第 i 杯酒 (1 ≤ i ≤ n) 的 美味度为 ai 。现在 Rainbow 公布了挑战环节的问题:本次大会调制的鸡尾酒有一个特点,如果把第 p 杯酒与第 q 杯酒调兑在一起,将得到一杯美味度为 ap*aq 的 酒。现在请各位品酒师分别对于 r = 0,1,2, ? , n ? 1 ,统计出有多少种方法可以 选出 2 杯“ r 相似”的酒,并回答选择 2 杯“ r 相似”的酒调兑可以得到的美味度的最大值。
第 1 行包含 1 个正整数 n ,表示鸡尾酒的杯数。
第 2 行包含一个长度为 n 的字符串 S,其中第 i 个字符表示第 i 杯酒的标签。
第 3 行包含 n 个整数,相邻整数之间用单个空格隔开,其中第 i 个整数表示第 i 杯酒的美味度 ai 。
12
abaabaabaaba
1 -2 3 -4 5 -6 7 -8 9 -10 11 -12
66 120
34 120
15 55
12 40
9 27
7 16
5 7
3 -4
2 -4
1 -4
0 0
0 0
这种字符串子串比较的题目,应该很容易都能想到后缀数组。
我们发现如果两杯酒是k相似的,那么k一定小等于 以这两杯酒为开头的后缀 的最长公共前缀。
我们将原串转化为排序好的后缀数组(原串之后就没用了)显然在后缀数组上相邻的最长公共前缀就是它们之间的height。
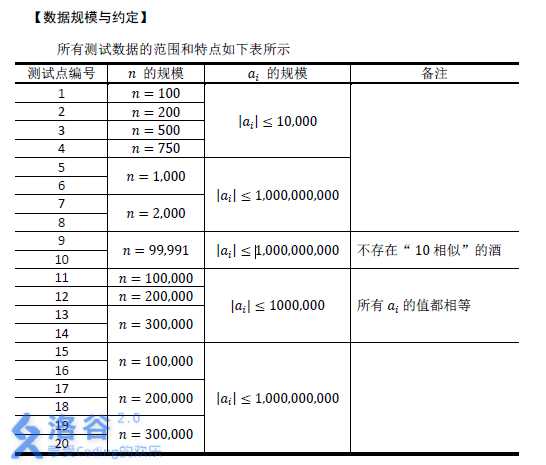
进一步说,在后缀数组上任意两个不相等的后缀s[l]、s[r],那么它们的最长公共前缀就是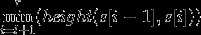 。
。
这样我们得到了n-1个height,设height[i]=height(s[i-1],s[i])。
height[i]对答案的贡献是存在最长的区间[l,r],使得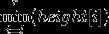 ,如果height有相同的情况,强制给他们定义大小级别。
,如果height有相同的情况,强制给他们定义大小级别。
小C举个例子:
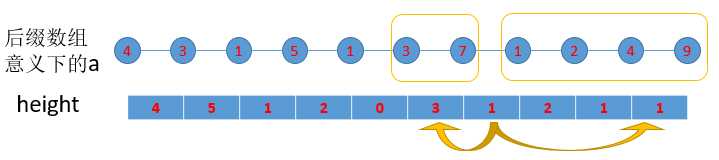
上图中,height[7]影响答案的范围是[6,10],这样左框里的元素3、7,都可以分别和右框里的1、2、4、9配对,每个配对之间的最长公共前缀一定是1。
(顺带一提,a数组就是题目中所述a数组,小C在此提醒方便读者阅读。)
因此,height[7]对于为1相似的配对的数目ans1[1]的贡献是2*4=8,对于为1相似的配对的最大美味度ans2[1]的贡献是7*9=63。
如果像上图中height[7]影响了[6,10],那么同样值等于1的height[9]影响的范围最多只能是[8,10]了,因为我们强制给它们定义了大小级别。
统计最大值时要注意负负得正的情况,所以要同时记录区间的最大值和最小值。
以上就基本解决了统计答案一类的问题,那么如何寻找每个height影响的区间呢?
很容易想到的就是对于每个height分别向左向右利用ST表二分它作为最小值的区间,注意值相等的情况,复杂度O(nlogn)。
还有就是解决这类问题很经典的区间RMQ数据结构——笛卡尔树,可以实现O(n)解决问题。
简单的说,笛卡尔树长得就像一棵treap,它既满足二分查找树的性质,又满足堆的性质。(假装大家都会treap)
大约就可以脑补笛卡尔树是干什么用的了吧?
如果还是不理解或是想知道构建方法的可以自行上网百度,小C这里就不多说了。
建树的时候把每个height看做一个点(本来height很像是两点之间的线段,这里就很像是化边为点?)。
而存储信息的时候每个节点存储的是后缀数组上的某段区间的信息,注意别混淆了。具体实现可以看小C的代码。
#include <cstdio> #include <cstring> #include <algorithm> #include <ctime> #define l(a) (son[a][0]) #define r(a) (son[a][1]) #define ll long long #define INF 0x3FFFFFFF #define MN 300005 #define MS 20 using namespace std; int mp[MN],a[MN],sa[MS][MN],rak[MS][MN]; ll ad[MN],an[MN],FINF; int son[MN][2],fa[MN],tp[MN],st[MN],top; int len[MN],w[MN],mn[MN],mx[MN]; char c[MN]; int n,p; int T; inline int read() { int n=0,f=1; char c=getchar(); while (c<‘0‘ || c>‘9‘) {if(c==‘-‘)f=-1; c=getchar();} while (c>=‘0‘ && c<=‘9‘) {n=n*10+c-‘0‘; c=getchar();} return n*f; } void mul(int* osa,int* ork,int* nsa,int* nrk,int k) { register int i; for (i=1;i<=n;++i) mp[ork[osa[i]]]=i; for (i=n;i;--i) if (osa[i]>k) nsa[mp[ork[osa[i]-k]]--]=osa[i]-k; for (i=n-k+1;i<=n;++i) nsa[mp[ork[i]]--]=i; for (i=1;i<=n;++i) nrk[nsa[i]]=nrk[nsa[i-1]]+(ork[nsa[i]]!=ork[nsa[i-1]]||ork[nsa[i]+k]!=ork[nsa[i-1]+k]); } void presa() { register int i,k; for (i=1;i<=n;++i) ++mp[a[i]]; for (i=1;i<=26;++i) mp[i]+=mp[i-1]; for (i=1;i<=n;++i) sa[p][mp[a[i]]--]=i; for (i=1;i<=n;++i) rak[p][sa[p][i]]=rak[p][sa[p][i-1]]+(a[sa[p][i-1]]!=a[sa[p][i]]); for (k=1;k<n;k<<=1,++p) mul(sa[p],rak[p],sa[p+1],rak[p+1],k); } void dfs(int x) { if (!x) return; dfs(l(x)); dfs(r(x)); if (!l(x)) l(x)=MN-1,mn[l(x)]=mx[l(x)]=w[sa[p][rak[p][x]-1]],len[l(x)]=1; if (!r(x)) r(x)=MN-2,mn[r(x)]=mx[r(x)]=w[sa[p][rak[p][x] ]],len[r(x)]=1; mn[x]=min(mn[l(x)],mn[r(x)]); mx[x]=max(mx[l(x)],mx[r(x)]); len[x]=len[l(x)]+len[r(x)]; ad[tp[x]]+=1LL*len[l(x)]*len[r(x)]; an[tp[x]]=max(an[tp[x]],1LL*mn[l(x)]*mn[r(x)]); an[tp[x]]=max(an[tp[x]],1LL*mn[l(x)]*mx[r(x)]); an[tp[x]]=max(an[tp[x]],1LL*mx[l(x)]*mn[r(x)]); an[tp[x]]=max(an[tp[x]],1LL*mx[l(x)]*mx[r(x)]); } int main() { register int i,k,x,y; n=read(); scanf("%s",c+1); for (i=1;i<=n;++i) a[i]=c[i]-‘a‘+1; presa(); for (i=1;i<=n;++i) w[i]=read(); mn[0]=INF; mx[0]=-INF; memset(an,128,sizeof(an)); FINF=an[0]; tp[0]=-1; for (i=2;i<=n;++i) for (tp[sa[p][i]]=0,k=p,x=sa[p][i],y=sa[p][i-1];k>=0;--k) if (rak[k][x]==rak[k][y]) tp[sa[p][i]]+=(1<<k),x+=(1<<k),y+=(1<<k); for (i=2;i<=n;++i) { for (x=0;top&&tp[sa[p][i]]<=tp[st[top]];x=st[top--]); if (x) fa[x]=sa[p][i]; l(sa[p][i])=x; r(st[top])=sa[p][i]; fa[sa[p][i]]=st[top]; st[++top]=sa[p][i]; } dfs(st[1]); for (i=n-1;i>=0;--i) an[i]=max(an[i],an[i+1]),ad[i]+=ad[i+1]; for (i=0;i<n;++i) printf("%lld %lld\n",ad[i],an[i]==FINF?0:an[i]); }
这个做法是小C之后才知道的,小C在这之前还自己YY了一个奇怪的线段树做法,思路好像完全不一样,洛谷上卡过了,BZOJ(时限0.5s)和自家OJ(未开O2)死活卡过不去几个点。代码姑且放出来留念吧。

#include <cstdio> #include <cstring> #include <algorithm> #define l(a) (a<<1) #define r(a) (a<<1|1) #define ll long long #define MM 1200005 #define MN 300005 #define MS 20 using namespace std; int mp[MN],a[MN],sa[MS][MN],rak[MS][MN]; ll ad[MM],an[MM],FINF; int len[MM],w[MN],mn[MM],mx[MM],inf,Finf; bool tg[MM]; char c[MN]; int n,p; inline int read() { int n=0,f=1; char c=getchar(); while (c<‘0‘ || c>‘9‘) {if(c==‘-‘)f=-1; c=getchar();} while (c>=‘0‘ && c<=‘9‘) {n=n*10+c-‘0‘; c=getchar();} return n*f; } void mul(int* osa,int* ork,int* nsa,int* nrk,int k) { register int i; for (i=1;i<=n;++i) mp[ork[osa[i]]]=i; for (i=n;i;--i) if (osa[i]>k) nsa[mp[ork[osa[i]-k]]--]=osa[i]-k; for (i=n-k+1;i<=n;++i) nsa[mp[ork[i]]--]=i; for (i=1;i<=n;++i) nrk[nsa[i]]=nrk[nsa[i-1]]+(ork[nsa[i]]!=ork[nsa[i-1]]||ork[nsa[i]+k]!=ork[nsa[i-1]+k]); } void presa() { register int i,k; for (i=1;i<=n;++i) ++mp[a[i]]; for (i=1;i<=26;++i) mp[i]+=mp[i-1]; for (i=1;i<=n;++i) sa[p][mp[a[i]]--]=i; for (i=1;i<=n;++i) rak[p][sa[p][i]]=rak[p][sa[p][i-1]]+(a[sa[p][i-1]]!=a[sa[p][i]]); for (k=1;k<n;k<<=1,++p) mul(sa[p],rak[p],sa[p+1],rak[p+1],k); } void mark0(int x) { void down(int); if (tg[x]) {ad[x]+=1LL*len[x]*(len[x]-1)/2; len[x]=0; mn[x]=inf; mx[x]=Finf;} else {down(x); tg[x]=1;} } void enlen(int x,int z) {len[x]+=z;} void upmx(int x,int z) { if (mx[x]!=Finf) an[x]=max(an[x],1LL*mx[x]*z); if (mn[x]!=inf) an[x]=max(an[x],1LL*mn[x]*z); mn[x]=min(mn[x],z); mx[x]=max(mx[x],z); } void down(int x) { if (tg[x]) {mark0(l(x)); mark0(r(x)); tg[x]=0;} if (len[x]) { enlen(l(x),len[x]); enlen(r(x),len[x]); upmx(l(x),mx[x]); upmx(r(x),mx[x]); if (len[x]>1) {upmx(l(x),mn[x]); upmx(r(x),mn[x]);} len[x]=0; mn[x]=inf; mx[x]=Finf; } if (ad[x]) {ad[l(x)]+=ad[x]; ad[r(x)]+=ad[x]; ad[x]=0;} if (an[x]!=FINF) {an[l(x)]=max(an[l(x)],an[x]); an[r(x)]=max(an[r(x)],an[x]); an[x]=FINF;} } void write(int x,int L,int R) { if (L==R) {if (L<n) printf("%lld %lld\n",ad[x],an[x]==FINF?0:an[x]); return;} down(x); int mid=L+R>>1; write(l(x),L,mid); write(r(x),mid+1,R); } void chzero(int x,int L,int R,int ql,int qr) { if (ql==L&&qr==R) {mark0(x); return;} down(x); int mid=L+R>>1; if (qr<=mid) chzero(l(x),L,mid,ql,qr); else if (ql>mid) chzero(r(x),mid+1,R,ql,qr); else {chzero(l(x),L,mid,ql,mid); chzero(r(x),mid+1,R,mid+1,qr);} } void modify(int x,int L,int R,int ql,int qr,int z) { if (ql==L&&qr==R) {enlen(x,1); upmx(x,z); return;} down(x); int mid=L+R>>1; if (qr<=mid) modify(l(x),L,mid,ql,qr,z); else if (ql>mid) modify(r(x),mid+1,R,ql,qr,z); else {modify(l(x),L,mid,ql,mid,z); modify(r(x),mid+1,R,mid+1,qr,z);} } int main() { register int i,tp,k,x,y; n=read(); scanf("%s",c+1); for (i=1;i<=n;++i) a[i]=c[i]-‘a‘+1; for (i=1;i<=n;++i) w[i]=read(); presa(); memset(an,128,sizeof(an)); FINF=an[0]; memset(mn,127,sizeof(mn)); inf=mn[0]; memset(mx,128,sizeof(mx)); Finf=mx[0]; chzero(1,0,n,0,n); for (i=1;i<=n;++i) { for (tp=0,k=p,x=sa[p][i],y=sa[p][i-1];k>=0;--k) if (rak[k][x]==rak[k][y]) tp+=(1<<k),x+=(1<<k),y+=(1<<k); if (tp<n) chzero(1,0,n,tp+1,n); modify(1,0,n,0,n,w[sa[p][i]]); } chzero(1,0,n,0,n); write(1,0,n); }
看到最后你知道小C一定又要吐槽了。(废话,小C发哪篇文章不是为了吐槽?)
做这题之前小C还从来没有写过后缀数组,上网找了一篇“公认”很优秀的后缀数组模板(这里不是指黄学长的)讲解,理解了半天,愣是没理解。
奇怪,这大概是小C唯一一个看着模板还依然没有思路的算法了吧。(明明是你智商比较低)
然后点开黄学长的博客,发现了画风迥异的后缀数组模板,小C当机立断就写这种风格的了。
虽然黄学长写得十分优雅,但感觉还是无法拯救自己的智商,全程抄代码,至今好像还有点蒙。(CTSC考试之前一直都在看后缀数组模板QAQ,还好没考)
这是其一。然后就是自己脑子一抽写了个线段树(败给了常数),结果学写了正解之后发现自己想不出原来的线段树做法了有木有?
写正解的时候也处处碰壁,直到遇到小D和小F两位大神的指(yi)点(tong)迷(nu)津(D),才理解可以把height理解为连接后缀数组的线段,思路瞬间清晰。
蒟 蒻 求 轻 D
标签:思路 oid 完全 字母 nlogn 理解 get 包括 com
原文地址:http://www.cnblogs.com/ACMLCZH/p/6840529.html
