标签:正则 基础 工具 upper 需要 表达式 正则表达式 统计 空格
正则表达式基础以及grep的简单使用
1 定义
正则表达式是你所定义的模式模板,Linux可以用它来过滤文本。Linux工具(比如grep、sed、gawk)能够在处理数据时使用正则表达式对数据进行模式匹配。如果数据匹配模式,它就会被接受并进一步处理;如果数据不匹配,它就会被滤掉。
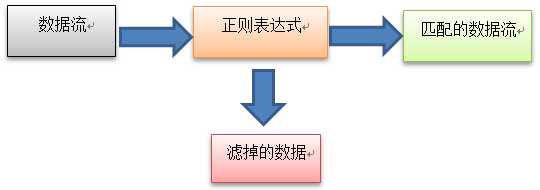
2 正则表达式的原则
(1)正则表达式模式都区分大小写。(2)可以使用空格,数字。(3)空格和其他字符并没有什么区别。
3 特殊字符
包括 * [ ] ^ $ ( ) \ + ? | { }
要使用特殊字符,必须转义,在转义字符时,需要在它前面加个特殊字符来告诉正则表达式引擎应该将接下来的字符当做普通的文本字符,这个特殊符号就是反斜线(\)。
4 锚字符
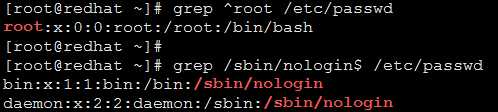
^ 行首锚定
$ 行尾锚定
\b \b 匹配词首和词尾
\< \> 匹配词首和词尾

5 grep 基本用法
-v 取反,找出不包含关键字的行
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配到的行数
-o 仅显示匹配到的字符串
-w 匹配整个单词
-A n匹配的前n行
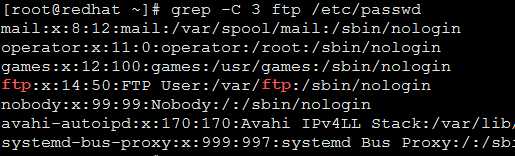
-B n 关键字的后n行
-C n 关键字的前后各n行
-e 实现多个选项的逻辑或关系

-E === egrep 支持扩展的正则表达式
-F === fgrep 不支持正则表达式
6 字符匹配规则
. 配任意单个字符
[abc] 匹配a,b,c中单个字符
[^abc] 匹配除a,b,c之外的字符
[:alnum:] 匹配数字和字符
[:alpha:] 匹配英文大小写字母a-z,A-Z
[:lower:] 匹配小写字母
[:upper:] 匹配大写字母
[:space:] 匹配空格
[:digit:] 匹配十进制数字
7 匹配次数
* 匹配前面的字符任意次数,0至正无穷
.* 匹配任意字符任意次数
\? 匹配前面字符0次或者1次
\+ 匹配前面字符至少1次
\{n\} 配前面字符n次
\{m,n\} 匹配前面字符出现m至n次
\{,n\} 匹配前面字符最多出现n次
\{n,\} 匹配前面字符至少n次
8 扩展正则表达式 egrep
次数匹配,和基本正则表达式类似,就是少了转义字符(\)
* 匹配前面字符任意次
? 匹配前面字符0次或1次
+ 匹配前面字符1次或多次
{m} 匹配前面字符m 次
{m,n}匹配前面字符m到n 次
9 使用管道(|)
管道允许你在检查数据时,用逻辑或方式指定正则表达式引擎要用的两个或者多个模式,如果任何一个模式匹配了数据文本,文本就通过,如果没有模式匹配,则数据流文本匹配失败。

10 分组
将匹配规则分成不同的组 使用 1 2 3..等数字去标识,便于后面使用同样规则的时候可以直接饮用
\(root\)\+\1
\(string1\+\(string2\)*\)
\1 string1\+\(string2\)*
\2 string2
找出/etc/passwd用户名同shell名的行
cat /etc/passwd | grep "^\(\b[[:alnum:]]\+\b\):.*\1$" grep "^\<\(.*\)\>.*\1$" /etc/passwd cat /etc/passwd | egrep "^(\b[[:alnum:]]+\b):.*\1$"

标签:正则 基础 工具 upper 需要 表达式 正则表达式 统计 空格
原文地址:http://www.cnblogs.com/Sunzz/p/6842343.html