标签:src abi call pos ati func oss bsp win
1. Linear classifier
It will use training data to learn a weight or coefficient for each word.
We use the gradient ascent to find the best model with the highest likelihood.
2. Sigmoid function
How can we map the output value of score (-∞ to +∞) with the probabilities ( 0 to 1).
we can use the sigmoid function shown below
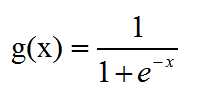
and for linear classifer, the
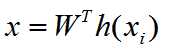
and it is called the generalized linear model.
3. Categorical inputs(countries or zipcode)
1-hot encoding: only one of these features has value 1 at the time everything else is 0.
Bag-words:the number of each word is a feature, with different wors, we have different features.
4. Multiclass classification
one-vesus-all
Train each classifier for one category and whatever class with the highest probability wins.
5. Likelihood function
We need to define a likelihood function to train the data, for positive data points we need the probability to be 1
and for negative data points we need the probability to be zero, but no weights can perfectlty achive that, so the
likelihood funciton is to measure the quality of fit for model with coefficients w and the highest likelihood defines the
best model. And that is where gradient ascent comes in. And the likelihood function is defined as:
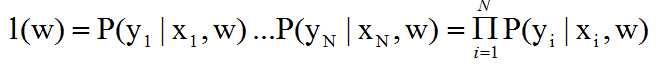
Now the task is to choose W to mask the likelihood function as large as possible
and we use gradient ascent to get the maximum value
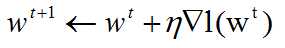
and we stop when the magnitude of the gradient is small enough
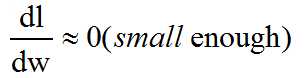 \
\
and the gradient is:
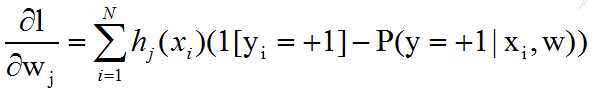
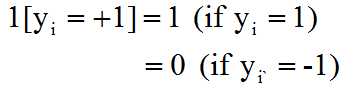 and hj(xi) is the feature value
and hj(xi) is the feature value
6. Learning curve
The learning curve plot is the The log likelihood over alll data points vs number of
iterations. And we use this cure to choose the step size. If the step size is too large,
it can cause divergence or wild oscillations. And if the step size is too small then the
time to converge is too slow. And we the advanced tip is that we can try step size that
decreases with iterations.
7. Overfitting
Often, overfitting is associated with large magnitude of coefficients and overconfident predictions. Because the
maximum likelihood function will try to find a larget w to get a larger probalility value to the data. And for linearly
separable data, the coefficients will grow to infinity.
8. Regularization
Total cost = measure of the fit - measure of magnitude of coefficients
measure of the fit = log of likelihood function
measure of magnitude of coefficients = (L2 norm penalize the large coefficients)
we can choose w to maximize the function below:
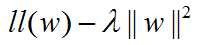
and the gradient ascent becomes:
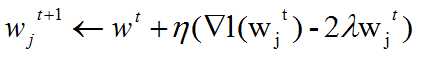
so the interpretation of the gradient is to try to move the coefficients towards zero.
机器学习笔记(Washington University)- Classification Specialization-week one & week two
标签:src abi call pos ati func oss bsp win
原文地址:http://www.cnblogs.com/climberclimb/p/6828156.html