标签:add height 设计 action mtd 6.2 max get 库存
使用唐诗语料库,经过去噪预处理、分词、生成搭配、生成主题等过程,生成唐诗。
github上repository地址:https://github.com/lijiancheng0614/poem_generator
Python 2.7
Flask
jieba
如果是第一次运行,则需要安装相关的库及生成初始数据:
pip install flask
pip install jieba
python preprocess.py
python get_collocations.py
python get_topic.py
python get_start_words.py以后只需要输入以下代码即可运行网站:
python index.py观察到给定的唐诗语料库存在以下噪声:
诗句中出现类似<img height=32 width=32 border=0 src=/bzk/QLXQ.bmp >的HTML标签。
出现空格、“.”等字符。
诗句中出现注释,用“(”、“)”标出来。
诗句不完整,出现方框字符。
对于前三种情况的噪声,直接去掉即可。对于最后一种噪声,直接把这行诗句忽略考虑。(此外,对于第三种噪声,“(”、“)”不在同一行时未处理。)
由于暂时只需要用到唐诗标题和诗句,故只提取这两部分内容。
相关代码实现在preprocess.py。
输入:
.\data\唐诗语料库.txt输出:
.\data\poem.txt对于中文分词,这里采用在工业界上较广泛应用的“结巴”中文分词组件1。该分词组件主要采用以下算法:基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG);采用动态规划查找最大概率路径,找出基于词频的最大切分组合;对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。
由于唐诗中的每一个字基本都是有用的,故停用词(Stop Words)主要为标点符号,这里直接使用默认的停用词。
搭配包括横向搭配和纵向搭配。横向搭配指每句诗中每个词与下一个词的搭配关系,纵向搭配指每两句诗中,第一句诗中的词与下一句诗中对应相等长度的词的搭配关系。
分词之后把唐诗(不含标题)按句子切割,对句子总数为偶数的唐诗,遍历每两句诗,第一句诗中的词与第二句诗中对应相等长度的词形成一个纵向搭配。对每一句诗,每两个词形成一个横向搭配。
易知,使用似然比、频率、t检验等搭配发现方法都能得到较好结果,这里为了方便,直接使用频率来发现搭配。
相关代码实现在get_collocations.py。
输入:
.\data\poem.txt输出:
.\data\collocations_h.\data\collocations_v对每首诗,提取TF-IDF2特征并构建矩阵3,然后使用非负矩阵分解(Non-negative matrix factorization, NMF)45提取唐诗主题类别。考虑到唐诗分类数量有限,这里只生成10个类,每个类用频率最高的20个词来表示。
相关代码实现在get_topic.py。
输入:
.\data\poem.txt输出:
.\data\topics.txt.\data\words.\data\topic_words对每首诗,分词后取第一句诗的第一个词作为起始词。统计所有起始词,并输出出现超过两次的词。
相关代码实现在get_start_words.py。
输入:
.\data\poem.txt输出:
.\data\start_words.txt由于前期并没有平仄处理,也没有对唐诗语料库作过多的要求,因此,生成的唐诗可能对仗不太工整。
输入的参数除了上述生成的部分文件(如搭配、主题等)外,还需要指定诗句数量、诗句长度、主题和起始词(若不指定则随机产生)。
对于给定诗句长度
其中
显然,对于该问题,可以把目标函数中的乘积部分用
设
其中
初始时
最后最优值为
而产生下一句诗,则需要考虑纵向搭配。同理我们也可以把产生下一句诗抽象成一个子问题:
其中
设
其中
初始时
求最优值与最优解方法同上。
相关代码实现在generate_poem.py。
输入:
.\data\collocations_v.\data\collocations_h.\data\words.txt.\data\topic_words.\data\start_words.txt输出:
为了更好的用户体验,可以把随机和成的唐诗写成一个网站“古诗生成器”。若是用户没有输入,则随机生成唐诗;若是用户输入第一句诗或更多句诗,则生成剩下的诗。
具体的实现使用Flask框架,由于只是demo,只使用了bootstrap作为样式,并未过多设计,具体效果如下图所示。
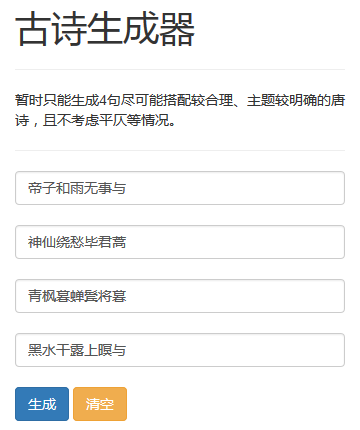
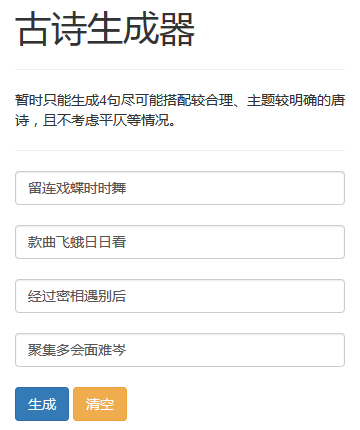
总的来说,这个系统生成的唐诗还只是基本符合搭配和主题尽可能相关的要求,平仄、主旨等唐诗的属性还有待改进。今后可以考虑生成更精确、更有意义的唐诗,如文献6提供了一种解决方案。期待以后能做出更好的效果!
标签:add height 设计 action mtd 6.2 max get 库存
原文地址:http://blog.csdn.net/lijiancheng0614/article/details/71747592