标签:失效 oci fit lock idt 错误 丢失 第一个 活动
阅读http://book.mixu.net/distsys/replication.html的笔记,是本系列的第四章
拷贝其实是一组通信问题,为一些子问题,例如选举,失灵检测,一致性和原子广播提供了上下文。
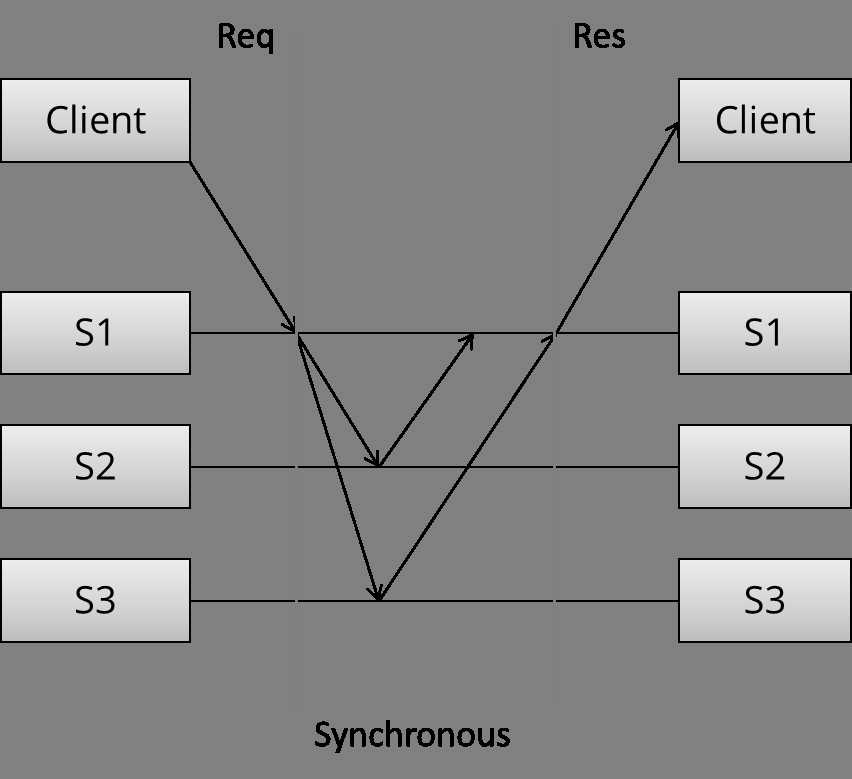
可以看到三个不同阶段,首先client发送请求。然后同步拷贝,同步意味着这时候client还在等待着请求返回。最后,服务器返回。
这就是N-of-N write,只有等所有N个节点成功写,才返回写成功给client。系统不容忍任何服务器下线。从性能上说,最慢的服务器决定了写的速度。
相对的是异步拷贝。
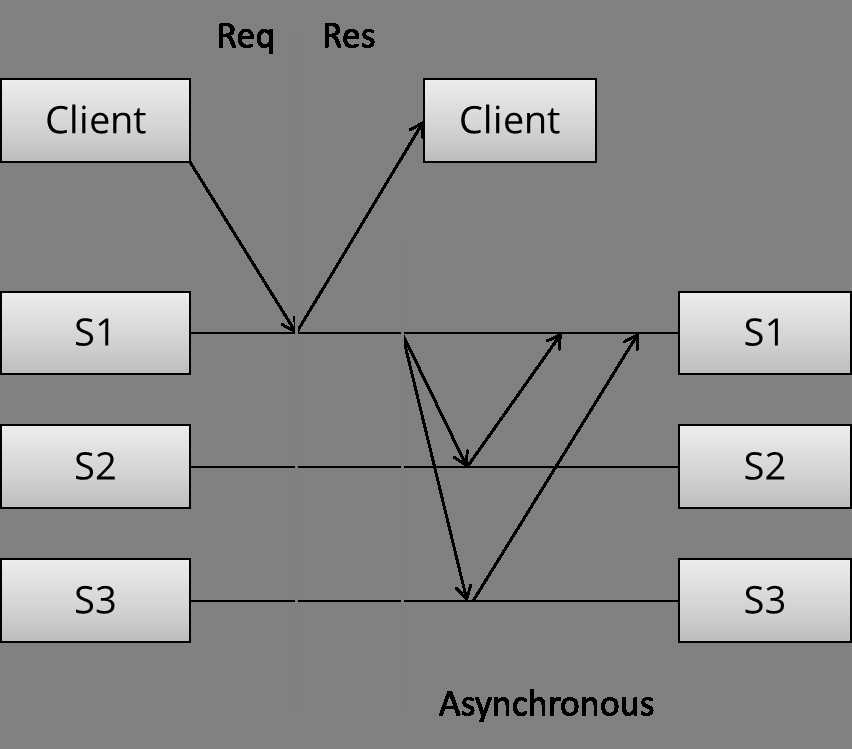
master节点立即返回。该节点可能在本地做了复制,但是不会向其他服务器发送拷贝。只有在返回以后,异步的任务在开始执行。
相对地,这是1-of-N write。性能上说,快。但是不能提供强一致性保证。
作者用下面的方式分类:
第一类途径使系统表现得像“single system”,即使系统部分失效。
单拷贝系统按照一次执行中传递的消息数目,可以做一下分类:
下面的图告诉我们,在不同侧重中选择(折中),我们会得到什么样的结果。
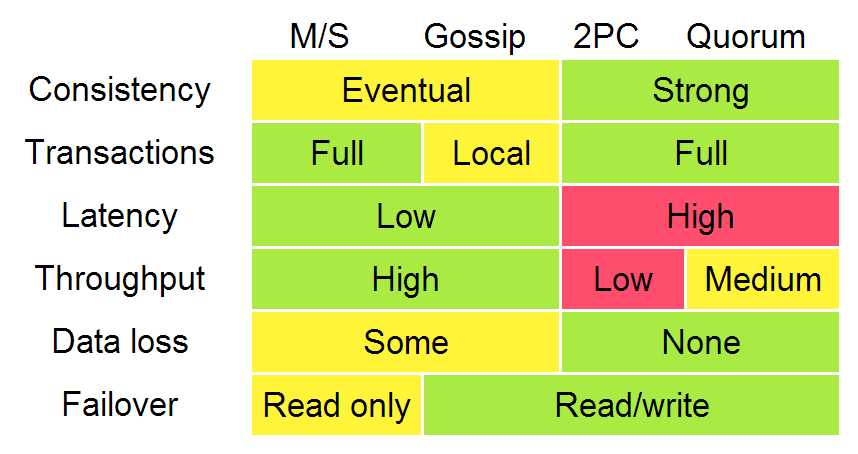
等待,性能就变差,一致性上的保证就更强。
最常见最基本的拷贝方式。所有的update发生在primary,并且以log的形式拷贝到backup 服务器。主从备份也分同步和异步两种。
MySQL和MongoDB都使用异步主从备份。同步主从备份保证在返回给client之前,backup节点成功存储了拷贝(Replica)。不过即使这样,同步方式也仅能保证较弱的承诺。考虑下面的场景:
client现在认为写失败,但是backup其实成功。如果backup promote成为primary,那么就不对了。
2PC在很多经典的关系型数据库中都使用到了。例如MySQL 集群使用2PC提供同步拷贝。下面是2PC的基本流程
[ Coordinator ] -> OK to commit? [ Peers ]
<- Yes / No
[ Coordinator ] -> Commit / Rollback [ Peers ]
<- ACK
在第一阶段,投票,协调者(Coordinator)给所有参与者发送update。每个参与者投票决定是否commit。如果选择commit,结果首先存放在临时区域(the write-ahead log)。除非第二阶段完成,这部分都只算“临时”的update。
在第二阶段,决策,协调者决定结果,并通知参与者。如果所有参与者都选择commit,那结果从临时区域移除,而成为最终结果。
2PC在最后commit之前,有一个临时区域,就能够在节点失效的时候,从而允许回滚。
之前讨论过,2PC属于CA,所以它没有考虑网络分割,对网络分割并没有容错。同时由于是N-of-N write,所以性能上会有一些折扣。
最著名的是Paxos算法,不过比较难理解和实现。所以Raft可以讲讲。
节点本身正常运行,但是网络链路发生问题。不同的Partition甚至还能接收client的请求。
2节点,节点失效 vs 网络分割

3节点,节点失效 vs网络分割
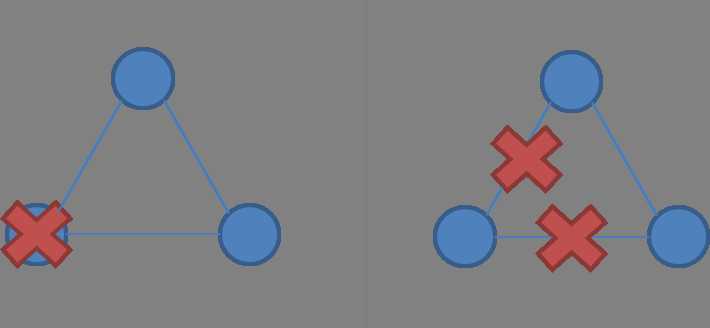
单拷贝一致系统必须找到方法去破坏对称性。否则如果网络分裂成两个独立对等系统,divergence发生,无法保证single-copy。所以必须保证只有一个Partition处于活动状态。
所以,对分割容错的一致性算法依赖多数投票。依赖多数,而不是所有(例如2PC)节点,即可容许少数因为网络分割出现的较慢的,无法到达的节点。只要 (N/2 + 1)of N中的节点正常,系统就可以正常运行。
在对网络分割容错的算法中,系统一般使用奇数数目的节点,例如3个节点的系统,允许1个节点失效。5个允许2个失效。这样发生网络分割,我们总能找到一个“大多数”的Partition。
在系统中,节点要么都扮演同一角色,要么各自担任不同角色。
一致性算法通常使节点扮演不同角色。有一个固定的领导或主节点,可以让算法更加高效。Paxos和Raft都利用了不同角色。在Paxos中,存在Proposer。领导者负责在操作中协调,余下的节点作为followers(Paxos中的Acceptors 或者 Voters)
在Paxos和Raft中,每次操作的周期都叫一个Epoch(”term“ in Raft)。在每个epoch,都有一个节点被指定为领导(Leader,后面都用英文吧,免得有歧义)。这个有点类似中国的朝代。
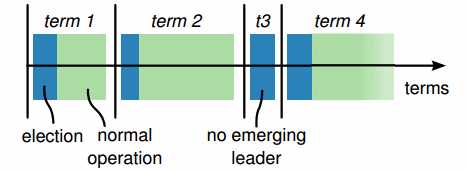
在每一次成功的选举后,一个epoch始终使用一个固定的leader,如上图。一些选举可能失败,那么epoch里面迭代到下一个。
真有点类似前面提到的逻辑时钟,让其他节点可以辨识凹凸的节点。那些分割的节点的epoch计数会比较小。
在一开始,某节点变成leader,其他节点成为follower。在操作过程中,leader维护心跳消息,这样follower就知道leader是否失灵,或者有网络分割发生。
当某节点发现leader没有响应了,(或者在初始状态,没有leader),该节点就转换成中间模式(在Raft称为candidate),然后将其epoch计数加1,发起leader的选举(election),竞争成为leader。
要成为leader,节点必须接收到足够多的votes,一种获取vote的方式就是谁先到谁取得。这样,最终会选出一个leader。
在每个epoch,leader提议某值用于投票。提案用一个唯一的递增的数字标记。followers则接受它们收到的第一个提案。
普通操作中,所有提案都经过leader节点。当一个client提交提案(client指分布式系统使用者),leader节点联系所有法定人数中的节点,如果在follower的回复中,没有与此冲突的提案,leader就提议某值。如果大多数follower都接受该值,那么该值就被认为正式接收。
当然有可能另外一个节点也在尝试成为leader,我们需要确保一旦提案被接受,该值永不改变。否则一个已经接受的提案可能被另外一个竞争leader推翻。
Lamport对该属性有如下表述:
如果对于值v的某提案被选中,那么每一个有较高数字标记的提案都有该值v。
原文如下:
P2: If a proposal with value
vis chosen, then every higher-numbered proposal that is chosen has valuev.
这个性质可以理解为一致性,也就是业已提出的提案,对其他后来提案都可见,是一种有效性。
为了保证该属性,proposer(leader)必须首先要求followers出示它们已有的最高数字的提案和值。如果proposer发现某提案已经存在,那么必须首先完成执行而不是重新提出提案。Lamport表述如下。
P2b. If a proposal with value
vis chosen, then every higher-numbered proposal issued by any proposer has valuev.
更具体地,
P2c. For any
vandn, if a proposal with valuevand numbernis issued [by a leader], then there is a setSconsisting of a majority of acceptors [followers] such that either (a) no acceptor inShas accepted any proposal numbered less thann, or (b)vis the value of the highest-numbered proposal among all proposals numbered less thannaccepted by the followers inS.
这是Paxos算法的核心。如果之前有多个提案存在,那么数字标记最高的提案会被提出。为了保证在leader在依次询问每个acceptor其最新的value的过程中不出现冲突的提案,leader告知follower不要接受比当前提案数字标记小的提案。
那么在Paxos中要达成一个决策,需要两轮通信。
[ Proposer ] -> Prepare(n) [ Followers ]
<- Promise(n; previous proposal number
and previous value if accepted a
proposal in the past)
[ Proposer ] -> AcceptRequest(n, own value or the value [ Followers ]
associated with the highest proposal number
reported by the followers)
<- Accepted(n, value)
准备阶段,proposer须知道任何冲突或者之前的提案。第二个阶段,一个新的value或者之前被提出的value,在proposer处提出。在某些情况下,比如说同时有两个proposer;比如消息丢失了;或者大多数节点失灵,那么不会有提案被多数节点接受。而这时允许的,因为最终的value还是收敛的。(也就是拥有最高数字标记的那个提案)。
这里非常类似西方民主国家的决策流程。在某项政策需要执行前,首先举行听证会,广泛征求意见。然后根据反馈的结果确定最后的政策。
当然在工程实现上还有不少挑战,这里列举了一些。
总结下各类算法的一些关键特征。
主从备份
2PC
Paxos
[分布式系统学习]阅读笔记 Distributed systems for fun and profit 之四 Replication 拷贝
标签:失效 oci fit lock idt 错误 丢失 第一个 活动
原文地址:http://www.cnblogs.com/lichen782/p/6852722.html