标签:student span 最大的 vector sda windows系统 learn extern images
本篇以信息增益最大作为最优化策略来详细介绍决策树的决策流程。
首先给定数据集,见下图
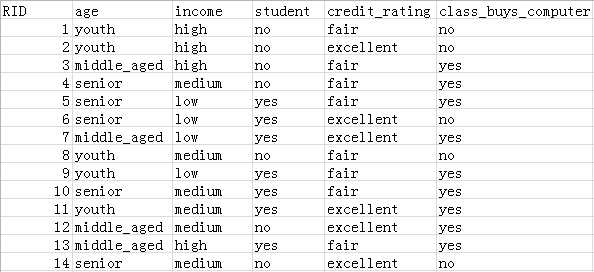
注:本数据来源于网络
本篇将以这些数据作为训练数据(虽然少,但足以介绍清楚原理!),下图是决策树选择特征的流程
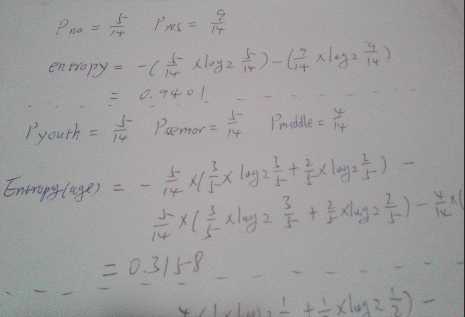
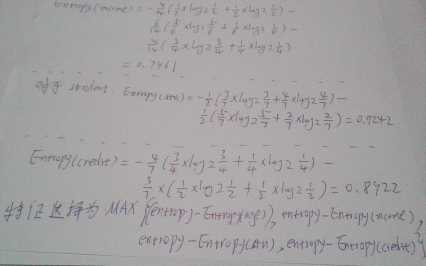
(请原谅我的拍照技术 )
)
图中entropy代表决策树在根节点处的信息熵,Entropy(age)表示用age这个特征作为分支节点后的信息熵,同理,Entropy(income)和Entropy(credit)分别表示用收入和信用作为分支节点后计算出的信息熵,注意这里的信息熵并不是指某一次预测的实例选择某个特征后的分类不确定度,而是指一个总体的情况,针对的是n次预测(n足够大)。
信息增益就是用选择特征前后的信息熵做差,求得最大的信息增益作为我们要选择的特征。上图只是计算了根节点的特征选择情况,可以看出,选择特征age可以得到最大的信息熵,所以根节点的特征就选取age,根节点下面的子树的特征选择同理。
下面用程序来构建决策树
首先介绍环境:Windows系统,Python3.5.2,anaconda1.5.1,下面是代码。
from sklearn.feature_extraction import DictVectorizer import csv from sklearn import tree from sklearn import preprocessing from sklearn.externals.six import StringIO # Read in the csv file and put features into list of dict and list of class label #allElectronicsData = open(‘D:\PythonWorkspace\DecisionTree\AllElectronics.csv‘, ‘r‘) #reader = csv.reader(allElectronicsData) #headers = reader.next() #D:\PythonWorkspace\DecisionTree\ with open("AllElectronics.csv","r") as csvfile: reader=csv.reader(csvfile) rows = [row for row in reader] headers=rows[0] readers=[] for i in range(1,len(rows)): readers.append(rows[i]) featureList = [] labelList = [] for row in readers: labelList.append(row[len(row)-1]) rowList = [] for i in range(1, len(row)-1): rowList.append(len(row[i]))#用字符串长度来标记对应的类别 featureList.append(rowList) print (labelList) print(featureList) clf = tree.DecisionTreeClassifier(criterion=‘entropy‘)#选择信息增益 clf = clf.fit(featureList, labelList)#训练模型 with open("allElectronicInformationGainOri.dot", ‘w‘) as f: f = tree.export_graphviz(clf, feature_names=[‘age‘,‘income‘,‘student‘,‘credit_rating‘,‘class_buys_computer‘], out_file=f)#可视化模型,以dot文件输出 newRowX = [11, 3, 3, 4]#找一个测试用例,因为训练数据本身就少,就捏造一个吧。。。 predictedY = clf.predict(newRowX) print("predictedY: " + str(predictedY))
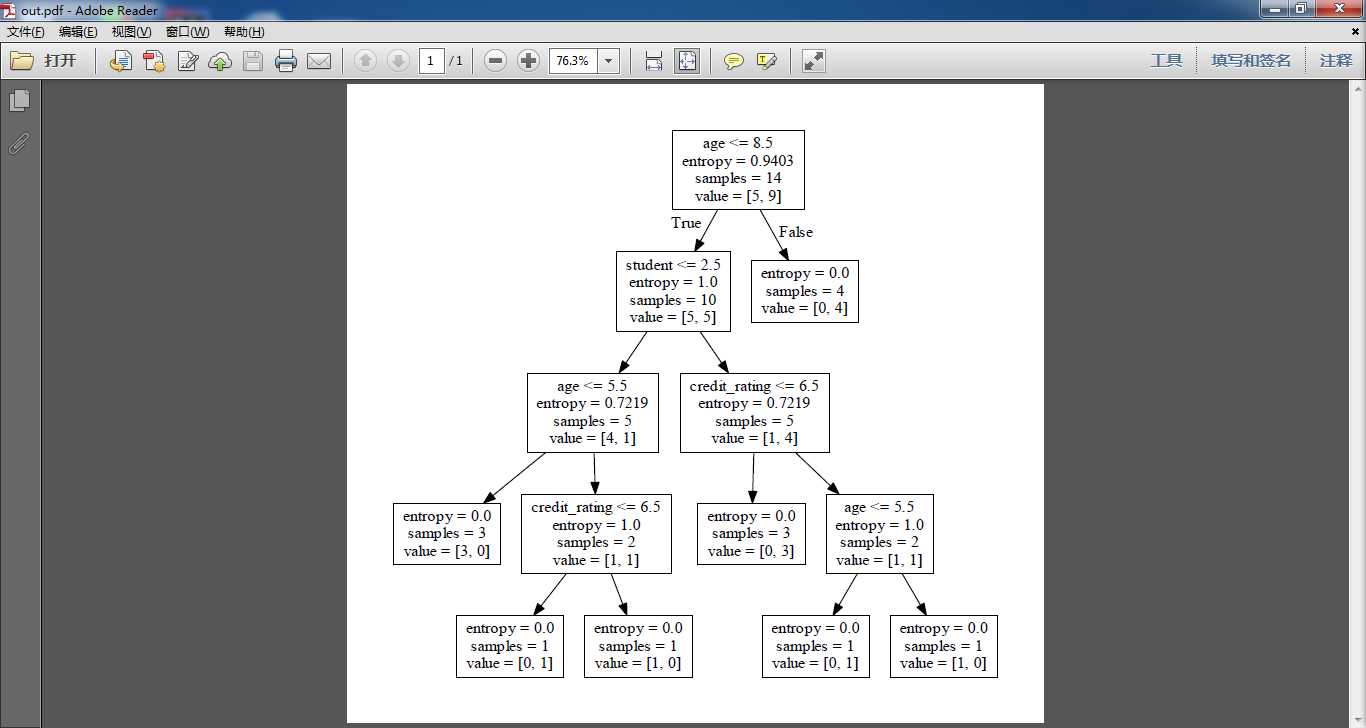
这是可视化为pdf的结果
标签:student span 最大的 vector sda windows系统 learn extern images
原文地址:http://www.cnblogs.com/xueyinzhe/p/6854106.html